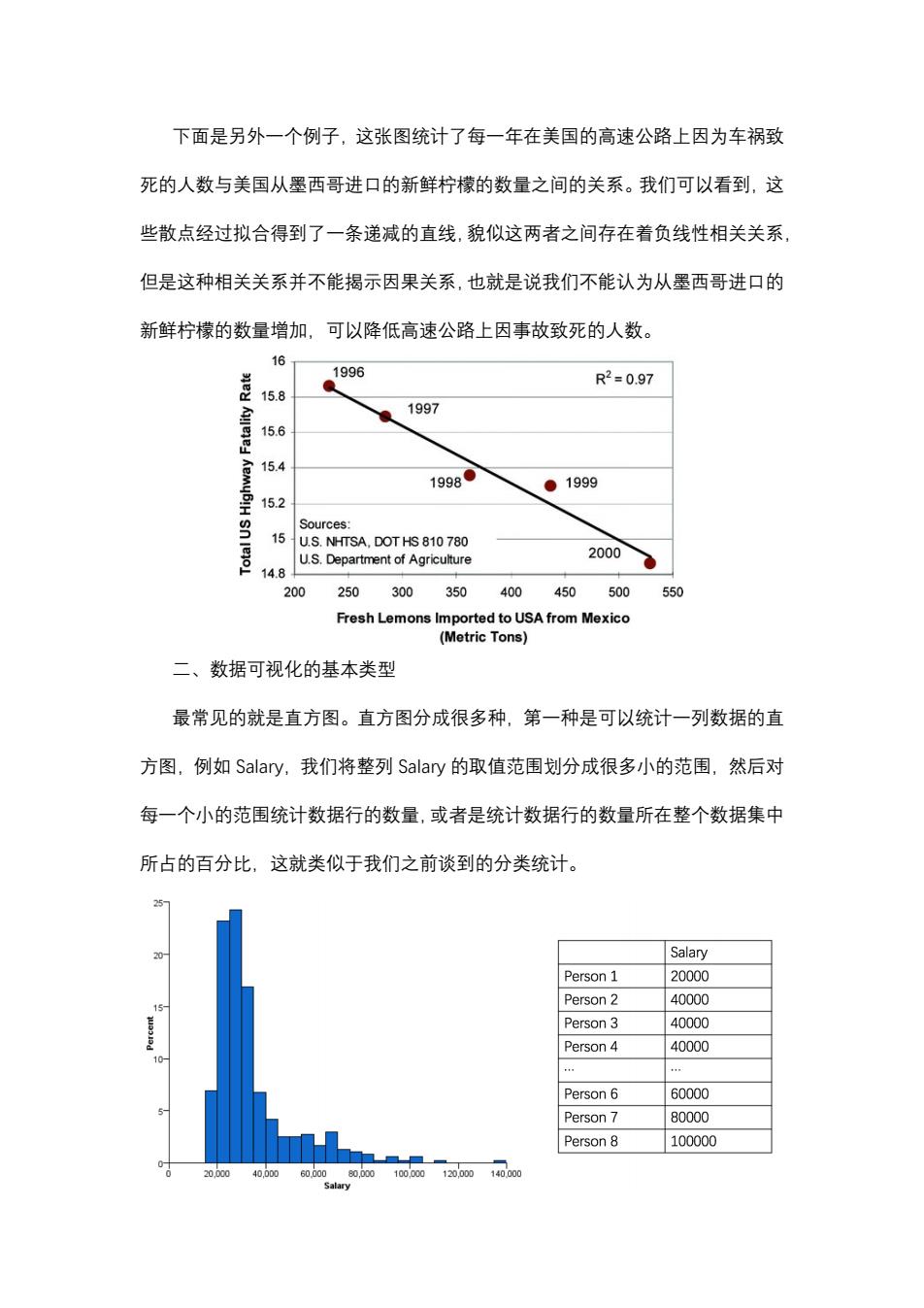
下面是另外一个例子,这张图统计了每一年在美国的高速公路上因为车祸致 死的人数与美国从墨西哥进口的新鲜柠檬的数量之间的关系。我们可以看到,这 些散点经过拟合得到了一条递减的直线,貌似这两者之间存在着负线性相关关系, 但是这种相关关系并不能揭示因果关系,也就是说我们不能认为从墨西哥进口的 新鲜柠檬的数量增加,可以降低高速公路上因事故致死的人数。 16 1996 R2=0.97 15.8 1997 15.6 15.4 MyB!H 1998● ● 1999 15.2 Sources: 15 U.S.NHTSA.DOT HS 810 780 U.S.Department of Agriculture 2000 14.8 200 250 300 350 400 450 500 550 Fresh Lemons Imported to USA from Mexico (Metric Tons) 二、数据可视化的基本类型 最常见的就是直方图。直方图分成很多种,第一种是可以统计一列数据的直 方图,例如Salary,我们将整列Salary的取值范围划分成很多小的范围,然后对 每一个小的范围统计数据行的数量,或者是统计数据行的数量所在整个数据集中 所占的百分比,这就类似于我们之前谈到的分类统计。 Salary Person 1 20000 Person 2 40000 15 Person 3 40000 Person 4 40000 10. Person 6 60000 Person 7 80000 Person 8 100000 20.000 40,000 60.00080,000100.000120,000 140.000 Salary
下面是另外一个例子,这张图统计了每一年在美国的高速公路上因为车祸致 死的人数与美国从墨西哥进口的新鲜柠檬的数量之间的关系。我们可以看到,这 些散点经过拟合得到了一条递减的直线,貌似这两者之间存在着负线性相关关系, 但是这种相关关系并不能揭示因果关系,也就是说我们不能认为从墨西哥进口的 新鲜柠檬的数量增加,可以降低高速公路上因事故致死的人数。 二、数据可视化的基本类型 最常见的就是直方图。直方图分成很多种,第一种是可以统计一列数据的直 方图,例如 Sa濿ary,我们将整列 Sa濿ary 的取值范围划分成很多小的范围,然后对 每一个小的范围统计数据行的数量,或者是统计数据行的数量所在整个数据集中 所占的百分比,这就类似于我们之前谈到的分类统计
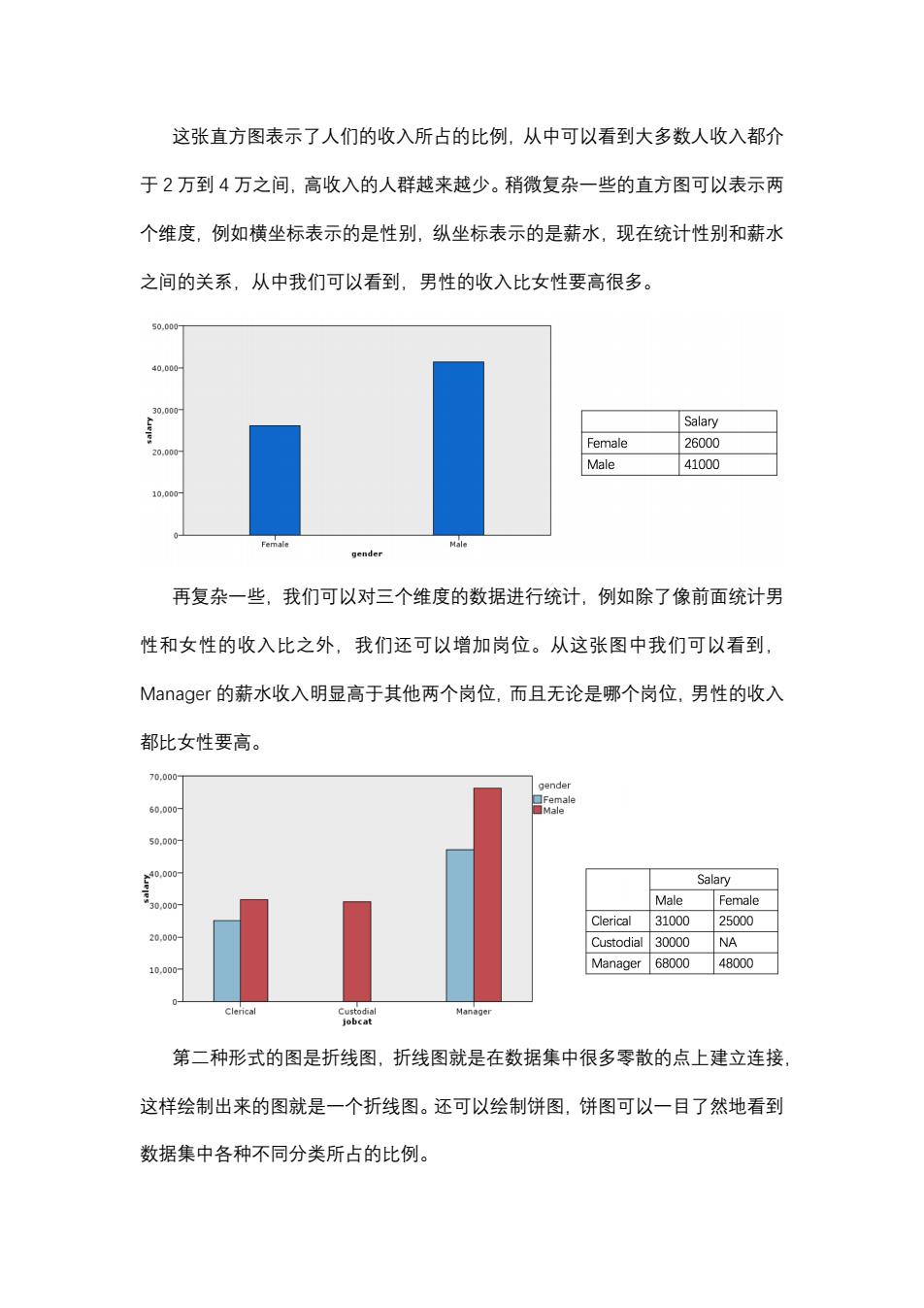
这张直方图表示了人们的收入所占的比例,从中可以看到大多数人收入都介 于2万到4万之间,高收入的人群越来越少。稍微复杂一些的直方图可以表示两 个维度,例如横坐标表示的是性别,纵坐标表示的是薪水,现在统计性别和薪水 之间的关系,从中我们可以看到,男性的收入比女性要高很多。 50,000- 40,000 30.000 Salary Female 26000 20.000 Male 41000 10,00 Fem Male gender 再复杂一些,我们可以对三个维度的数据进行统计,例如除了像前面统计男 性和女性的收入比之外,我们还可以增加岗位。从这张图中我们可以看到, Manager的薪水收入明显高于其他两个岗位,而且无论是哪个岗位,男性的收入 都比女性要高。 70,000 gender 60,000 Female 50,000 40,000 Salary 30.000 Male Female Clerical 31000 25000 20,.000 Custodial 30000 NA Manager 68000 48000 10.D00 Clerica Custodial Manage jobcat 第二种形式的图是折线图,折线图就是在数据集中很多零散的点上建立连接 这样绘制出来的图就是一个折线图。还可以绘制饼图,饼图可以一目了然地看到 数据集中各种不同分类所占的比例
这张直方图表示了人们的收入所占的比例,从中可以看到大多数人收入都介 于 2 万到 4 万之间,高收入的人群越来越少。稍微复杂一些的直方图可以表示两 个维度,例如横坐标表示的是性别,纵坐标表示的是薪水,现在统计性别和薪水 之间的关系,从中我们可以看到,男性的收入比女性要高很多。 再复杂一些,我们可以对三个维度的数据进行统计,例如除了像前面统计男 性和女性的收入比之外,我们还可以增加岗位。从这张图中我们可以看到, Ma瀁ager 的薪水收入明显高于其他两个岗位,而且无论是哪个岗位,男性的收入 都比女性要高。 第二种形式的图是折线图,折线图就是在数据集中很多零散的点上建立连接, 这样绘制出来的图就是一个折线图。还可以绘制饼图,饼图可以一目了然地看到 数据集中各种不同分类所占的比例

70,000 gender 60,000 50,000 90,000- Salary 30.000 Male Female Clerical 31000 25000 Custodial 30000 NA Manager 68000 48000 Manager Revenue Americas Asia Pacific Central Europe Northern Europe Southern Europe 下面是一张更复杂的图,它的横坐标表示销售的收入,纵坐标表示销量,每 一个圆的圆心所在的坐标表示这一种商品销售的收入和数量,圆的面积表示的是 这种商品的净利润。从中可以看到,某些商品的利润很高,有些利润很低,但是 有些商品的销售量很少,它的收入却不是很低,证明它的单价比较高。这张图可 以从三个维度来刻画,这个数据集分别是收入、 销售量以及利润。 Product line ● ● ● Revenue Quantity Profit Camping Equipment Mountain Equipment Personal Accessonie 5 Outdoor Protection 200 Golf Equipment 50 2,000 2500
下面是一张更复杂的图,它的横坐标表示销售的收入,纵坐标表示销量,每 一个圆的圆心所在的坐标表示这一种商品销售的收入和数量,圆的面积表示的是 这种商品的净利润。从中可以看到,某些商品的利润很高,有些利润很低,但是 有些商品的销售量很少,它的收入却不是很低,证明它的单价比较高。这张图可 以从三个维度来刻画,这个数据集分别是收入、销售量以及利润

还有很多例子是希望在地图上进行可视化的。例如,下面这张图就给出了星 巴克各个门店在世界上的位置的信息。 大厦分店,海口市,46CN rand tore tore wnership itate/Province Country Postcode hone Timezone Longitude Latitud NumberI Name Address Number 47370 censed AD D500 76818720 GMT+1:00 257954 153 42.51 1 Street 22331 212325 Drive ,N GMT+04:00 Asia/Duba 55.47 25.42 Thru 三、数据可视化案例美国人的死因分析 让我们通过一个notebook来了解数据是如何被可视化的。这个notebook在 分析美国人的死因,所使用的数据集是美国疾病控制和预防中心提供的一份有关 从1999年到2015年的死亡人员的信息数据,这些数据当中包含了死亡年龄、 死亡的死因、死亡人员的性别和种族,以及所处的城市等等。我们希望对这些数 据的分析可以回答下面三个问题,第一,美国人最大的死因是什么?第二,男人 是否比女人更容易死亡?死亡与年龄是否相关?第三,随着时间的推移,哪些死 因会变得更加流行,而那些死因变得更加少见了。 在这个notebook中,我们是在学习如何进行数据可视化,我们需要 matplotlib这个库的支持,所以要先加载这个库,然后加载数据数据,可以从指 定URL处下载,下载后把它加载到DataFrame中。我们可以来看一看这些数据, 例如,它的前10行。可以看到,数据集中包含了用中文描述的死因,以及在集 控中心的编号和死亡的人员的年龄、性别、死亡的年份等等信息
还有很多例子是希望在地图上进行可视化的。例如,下面这张图就给出了星 巴克各个门店在世界上的位置的信息。 三、数据可视化案例 I - 美国人的死因分析 让我们通过一个 瀁瀂teb瀂瀂濾 来了解数据是如何被可视化的。这个 瀁瀂teb瀂瀂濾 在 分析美国人的死因,所使用的数据集是美国疾病控制和预防中心提供的一份有关 从 1999 年到 2015 年的死亡人员的信息数据,这些数据当中包含了死亡年龄、 死亡的死因、死亡人员的性别和种族,以及所处的城市等等。我们希望对这些数 据的分析可以回答下面三个问题,第一,美国人最大的死因是什么?第二,男人 是否比女人更容易死亡?死亡与年龄是否相关?第三,随着时间的推移,哪些死 因会变得更加流行,而那些死因变得更加少见了。 在这个 瀁瀂teb瀂瀂濾 中,我们是在学习如何进行数据可视化,我们需要 瀀at瀃濿瀂t濿ib 这个库的支持,所以要先加载这个库,然后加载数据数据,可以从指 定 URL 处下载,下载后把它加载到 DataFra瀀e 中。我们可以来看一看这些数据, 例如,它的前 10 行。可以看到,数据集中包含了用中文描述的死因,以及在集 控中心的编号和死亡的人员的年龄、性别、死亡的年份等等信息

载入matplotlib库 1n【11: fenable grapha to be diaplayed in notebooks smatplotlib inline reload(sys) python2 sys.setdofaultencoding('GBK')varning may display but 1e OK out[1]:<module 'sys'(built-in)> 获得数据 从下面的链接中下载deaths.cy In ]#inux fwget --output-document /resources/data/deatha.csv https://ibm.box.com/shared/static/10iexjaa280qzdxcdtu98xlv51h 读取deaths.csw文件内容: ng-'GaK' 很好现在数据都在变量df内了 理解数据 前10行: In【3]:df.head(310) 0ut3]: Cause CauseCN Code-ICD-10-113 Age Gender Year Deaths Population Crude Rate 0 沙门氏萄悬染 G113-001 10 20050 1956682 Unmiable 沙门氏菌感染 GR113-001 0 20101 1929677 沙门氏菌暴染 GR13-001 20153 1942904 3 Saimonela infections 沙门氏菊懸染 GR113-001 20060 1950494 4 沙门氏萄蒸染 GR113-001 20100 1947217 沙门氏菌感染 GR113-001 F 20150 1939269 6Saimonella infections 沙门氏葡暴染 GR113-001 2 20050 1932337 Unreliable 7Salmonela infections 沙门氏葡瑟染 GR113-001 2 20100 2004731 Urriabie 8Salmonella infections 沙门氏菌藤染 GR113-001 20150 1939979 Unreliable 9Salmonela infections 沙门氏菌綦染 G113-001 3 20050 1930395 Unreliable 我们可以对死亡的年龄做一个汇总,可以看到,最大的死亡人员有100岁, 最小的是刚出生的婴儿,平均年龄是50岁,我们还可以看看数据集中到底包含 了哪些年份,可以看到数据集里面包含了死亡年份有2005年、2010年、2015 年。我们还可以看看性别是否只包含男女两种,我们看到Gender这一列确实只 包含F和M这两个取值
我们可以对死亡的年龄做一个汇总,可以看到,最大的死亡人员有 100 岁, 最小的是刚出生的婴儿,平均年龄是 50 岁,我们还可以看看数据集中到底包含 了哪些年份,可以看到数据集里面包含了死亡年份有 2005 年、2010 年、2015 年。我们还可以看看性别是否只包含男女两种,我们看到 Ge瀁der 这一列确实只 包含 F 和 M 这两个取值