
在系统分组的资料中,一般把按一 级因子分组的样本称为一级样本,把按 二级因子分组的样本,称为二级样本或 次级样本。 次级样本含量又分为相等和不相等 两种情况。 嵌套分组:
在系统分组的资料中,一般把按一 级因子分组的样本称为一级样本,把按 二级因子分组的样本,称为二级样本或 次级样本。 次级样本含量又分为相等和不相等 两种情况。 嵌套分组:

7.3.1 数据模式 最简单的系统分组资料,是二级样本 的分组资料。 假设: 1. 一级因子A:p个水平: i=1,2.p
7.3.1 数据模式 最简单的系统分组资料,是二级样本 的分组资料。 假设: 1. 一级因子A:p个水平: i=1,2.p

2. 二级因子B :q 个水 平: j=1,2.q, 3. 每个二级因子水平又有n个观察值: k=1,2.n, 共有pqn 个观察值
2. 二级因子B :q 个水 平: j=1,2.q, 3. 每个二级因子水平又有n个观察值: k=1,2.n, 共有pqn 个观察值
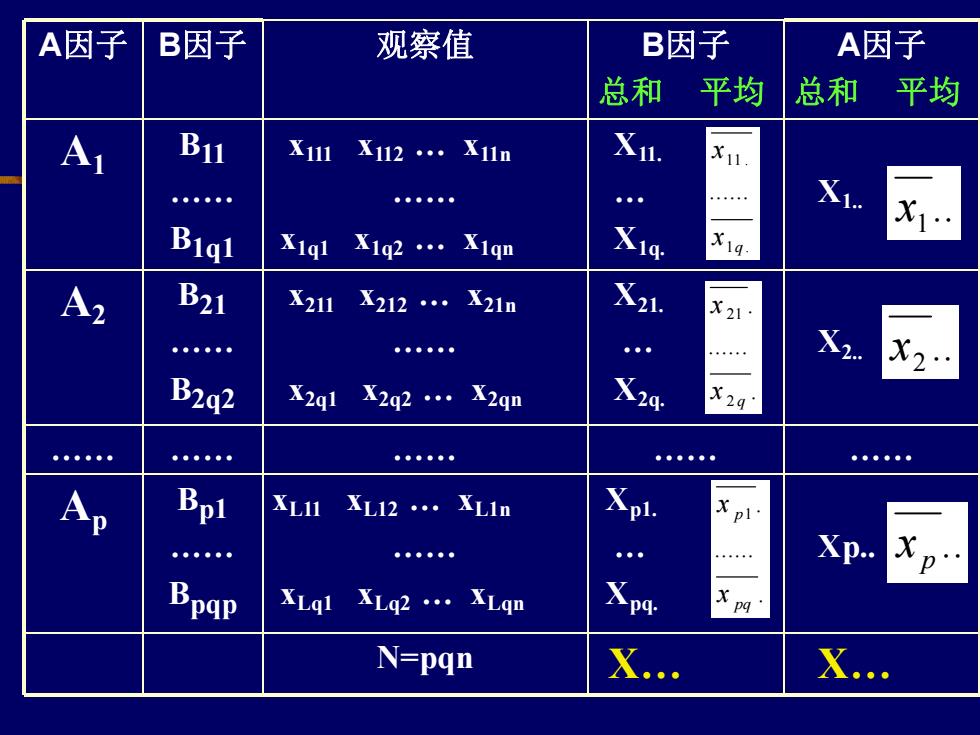
A因子 B因子 观察值 B因子 总和 平均 A因子 总和 平均 A1 B11 . B1q1 x111 x112 . x11n . x1q1 x1q2 . x1qn X11. . X1q. X1. A2 B21 . B2q2 x211 x212 . x21n . x2q1 x2q2 . x2qn X21. . X2q. X2. . . . . . Ap Bp1 . Bpqp xL11 xL12 . xL1n . xLq1 xLq2 . xLqn Xp1. . Xpq. Xp. N=pqn X. X. . 1 x . p x . 2 x 1 . 11 . .q x x . . . 2 21 q x x . . . 1 pq p x x
A因子 B因子 观察值 B因子 总和 平均 A因子 总和 平均 A1 B11 . B1q1 x111 x112 . x11n . x1q1 x1q2 . x1qn X11. . X1q. X1. A2 B21 . B2q2 x211 x212 . x21n . x2q1 x2q2 . x2qn X21. . X2q. X2. . . . . . Ap Bp1 . Bpqp xL11 xL12 . xL1n . xLq1 xLq2 . xLqn Xp1. . Xpq. Xp. N=pqn X. X. . 1 x . p x . 2 x 1 . 11 . .q x x . . . 2 21 q x x . . . 1 pq p x x

7.3.2 数学模型 i ij ijk i ij ijk i p j q k n x e 1,2,. ; 1,2,. ; 1,2,., ; 0 2 : 因子的第 个水平下 因子的第 个水平中的观察值个数 : 因子的第 个水平下 因子的水平数; : 因子的水平数; :随机误差;服从 ( , ) : 因子的第 个水平下 因子的第 个水平的效应; : 因子的第 个水平的效应; :总平均; n A i B j q A i B p A e N A i B j A i ij i ijk ij i
7.3.2 数学模型 i ij ijk i ij ijk i p j q k n x e 1,2,. ; 1,2,. ; 1,2,., ; 0 2 : 因子的第 个水平下 因子的第 个水平中的观察值个数 : 因子的第 个水平下 因子的水平数; : 因子的水平数; :随机误差;服从 ( , ) : 因子的第 个水平下 因子的第 个水平的效应; : 因子的第 个水平的效应; :总平均; n A i B j q A i B p A e N A i B j A i ij i ijk ij i