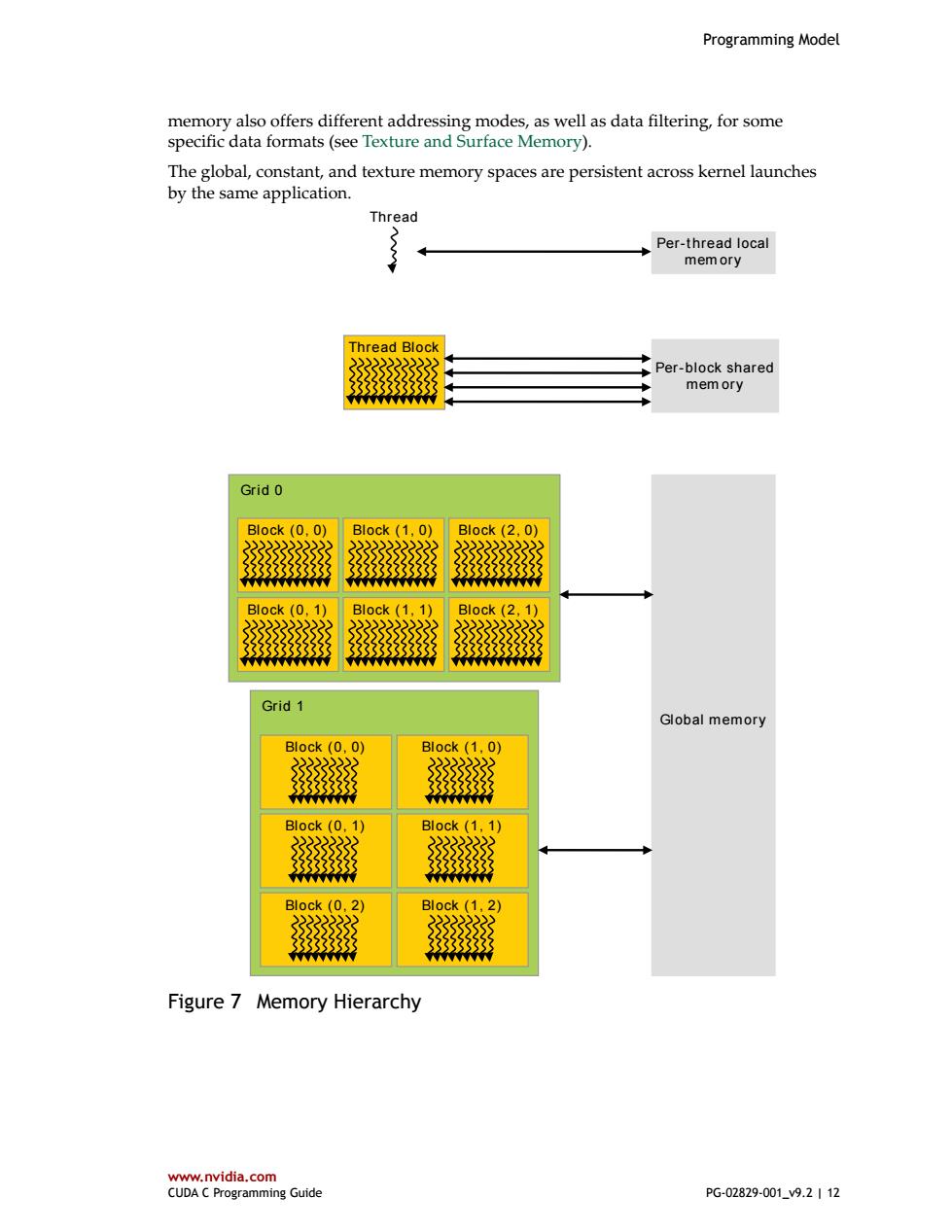
Programming Model memory also offers different addressing modes,as well as data filtering,for some specific data formats(see Texture and Surface Memory). The global,constant,and texture memory spaces are persistent across kernel launches by the same application. Thread Per-thread local mem ory Thread Block Per-block shared mem ory Grid 0 Block(0,0) Block (1,0) Block(2,0) 33333333333 33333333333 Block (0,1) B1ock(1,1) B1ock(2,1) 33333333333 中中 NMNMANMAAN Grid 1 Global memory Block (0,0) BI0ck(1,0) 这 33333333 333333 A A点 Block (0,1) B1ock(1,1) Block(0.2) Block(1.2) 33333333 Figure 7 Memory Hierarchy www.nvidia.com CUDA C Programming Guide PG-02829-001_v9.2|12
Programming Model www.nvidia.com CUDA C Programming Guide PG-02829-001_v9.2 | 12 memory also offers different addressing modes, as well as data filtering, for some specific data formats (see Texture and Surface Memory). The global, constant, and texture memory spaces are persistent across kernel launches by the same application. Global memory Grid 0 Block (0, 1) Block (1, 1) Block (2, 1) Block (0, 0) Block (1, 0) Block (2, 0) Grid 1 Block (1, 1) Block (1, 0) Block (1, 2) Block (0, 1) Block (0, 0) Block (0, 2) Thread Block Per-block shared mem ory Thread Per-thread local mem ory Figure 7 Memory Hierarchy

Programming Model 2.4.Heterogeneous Programming As illustrated by Figure 8,the CUDA programming model assumes that the CUDA threads execute on a physically separate device that operates as a coprocessor to the host running the C program.This is the case,for example,when the kernels execute on a GPU and the rest of the C program executes on a CPU. The CUDA programming model also assumes that both the host and the device maintain their own separate memory spaces in DRAM,referred to as host memory and device memory,respectively.Therefore,a program manages the global,constant,and texture memory spaces visible to kernels through calls to the CUDA runtime(described in Programming Interface).This includes device memory allocation and deallocation as well as data transfer between host and device memory. Unified Memory provides managed memory to bridge the host and device memory spaces.Managed memory is accessible from all CPUs and GPUs in the system as a single,coherent memory image with a common address space.This capability enables oversubscription of device memory and can greatly simplify the task of porting applications by eliminating the need to explicitly mirror data on host and device.See Unified Memory Programming for an introduction to Unified Memory." www.nvidia.com CUDA C Programming Guide PG-02829-001_v9.2|13
Programming Model www.nvidia.com CUDA C Programming Guide PG-02829-001_v9.2 | 13 2.4. Heterogeneous Programming As illustrated by Figure 8, the CUDA programming model assumes that the CUDA threads execute on a physically separate device that operates as a coprocessor to the host running the C program. This is the case, for example, when the kernels execute on a GPU and the rest of the C program executes on a CPU. The CUDA programming model also assumes that both the host and the device maintain their own separate memory spaces in DRAM, referred to as host memory and device memory, respectively. Therefore, a program manages the global, constant, and texture memory spaces visible to kernels through calls to the CUDA runtime (described in Programming Interface). This includes device memory allocation and deallocation as well as data transfer between host and device memory. Unified Memory provides managed memory to bridge the host and device memory spaces. Managed memory is accessible from all CPUs and GPUs in the system as a single, coherent memory image with a common address space. This capability enables oversubscription of device memory and can greatly simplify the task of porting applications by eliminating the need to explicitly mirror data on host and device. See Unified Memory Programming for an introduction to Unified Memory

Programming Model C Program Sequential Execution Serial code Host Parallel kernel Device Kernel0<<<>>>(0 Grid 0 Block (0,0) B1ock(1,0) B1ock(2,0) 3333333333 3333333333 B1ock(0,1) Block (1,1) B1ock(2,1) 333333333333 3333333333 Serial code Host Device Parallel kernel Kernel1<<<>>>(0 Grid 1 B1ock(0,0) Block (1,0) 33333333 B1ock(0,1) Block(1,1) B1ock(0,2) B1ock(1,2) )》>)) 22222222 Serial code executes on the host while parallel code executes on the device. Figure 8 Heterogeneous Programming www.nvidia.com CUDA C Programming Guide PG-02829-001_v9.2|14
Programming Model www.nvidia.com CUDA C Programming Guide PG-02829-001_v9.2 | 14 Devi ce Grid 0 Block (0, 1) Block (1, 1) Block (2, 1) Block (0, 0) Block (1, 0) Block (2, 0) Host C Program Sequential Execution Serial code Parallel kernel Kernel0< < < > > > () Serial code Parallel kernel Kernel1< < < > > > () Host Devi ce Grid 1 Block (1, 1) Block (1, 0) Block (1, 2) Block (0, 1) Block (0, 0) Block (0, 2) Serial code executes on the host while parallel code executes on the device. Figure 8 Heterogeneous Programming

Programming Model 2.5.Compute Capability The compute capability of a device is represented by a version number,also sometimes called its"SM version".This version number identifies the features supported by the GPU hardware and is used by applications at runtime to determine which hardware features and/or instructions are available on the present GPU. The compute capability comprises a major revision number X and a minor revision number Y and is denoted by X.Y. Devices with the same major revision number are of the same core architecture.The major revision number is 7 for devices based on the Volta architecture,6 for devices based on the Pascal architecture,5 for devices based on the Maxwell architecture,3 for devices based on the Kepler architecture,2 for devices based on the Fermi architecture, and 1 for devices based on the Tesla architecture. The minor revision number corresponds to an incremental improvement to the core architecture,possibly including new features. CUDA-Enabled GPUs lists of all CUDA-enabled devices along with their compute capability.Compute Capabilities gives the technical specifications of each compute capability. The compute capability version of a particular GPU should not be confused with the CUDA version(e.g.,CUDA 7.5,CUDA 8,CUDA 9),which is the version of the CUDA software platform.The CUDA platform is used by application developers to create applications that run on many generations of GPU architectures,including future GPU architectures yet to be invented.While new versions of the CUDA platform often add native support for a new GPU architecture by supporting the compute capability version of that architecture,new versions of the CUDA platform typically also include software features that are independent of hardware generation. The Tesla and Fermi architectures are no longer supported starting with CUDA 7.0 and CUDA 9.0,respectively. www.nvidia.com CUDA C Programming Guide PG-02829-001_v9.2|15
Programming Model www.nvidia.com CUDA C Programming Guide PG-02829-001_v9.2 | 15 2.5. Compute Capability The compute capability of a device is represented by a version number, also sometimes called its "SM version". This version number identifies the features supported by the GPU hardware and is used by applications at runtime to determine which hardware features and/or instructions are available on the present GPU. The compute capability comprises a major revision number X and a minor revision number Y and is denoted by X.Y. Devices with the same major revision number are of the same core architecture. The major revision number is 7 for devices based on the Volta architecture, 6 for devices based on the Pascal architecture, 5 for devices based on the Maxwell architecture, 3 for devices based on the Kepler architecture, 2 for devices based on the Fermi architecture, and 1 for devices based on the Tesla architecture. The minor revision number corresponds to an incremental improvement to the core architecture, possibly including new features. CUDA-Enabled GPUs lists of all CUDA-enabled devices along with their compute capability. Compute Capabilities gives the technical specifications of each compute capability. The compute capability version of a particular GPU should not be confused with the CUDA version (e.g., CUDA 7.5, CUDA 8, CUDA 9), which is the version of the CUDA software platform. The CUDA platform is used by application developers to create applications that run on many generations of GPU architectures, including future GPU architectures yet to be invented. While new versions of the CUDA platform often add native support for a new GPU architecture by supporting the compute capability version of that architecture, new versions of the CUDA platform typically also include software features that are independent of hardware generation. The Tesla and Fermi architectures are no longer supported starting with CUDA 7.0 and CUDA 9.0, respectively

Chapter 3 PROGRAMMING INTERFACE CUDA C provides a simple path for users familiar with the C programming language to easily write programs for execution by the device. It consists of a minimal set of extensions to the C language and a runtime library. The core language extensions have been introduced in Programming Model.They allow programmers to define a kernel as a C function and use some new syntax to specify the grid and block dimension each time the function is called.A complete description of all extensions can be found in C Language Extensions.Any source file that contains some of these extensions must be compiled with nvce as outlined in Compilation with NVCC. The runtime is introduced in Compilation Workflow.It provides C functions that execute on the host to allocate and deallocate device memory,transfer data between host memory and device memory,manage systems with multiple devices,etc.A complete description of the runtime can be found in the CUDA reference manual. The runtime is built on top of a lower-level C API,the CUDA driver API,which is also accessible by the application.The driver API provides an additional level of control by exposing lower-level concepts such as CUDA contexts-the analogue of host processes for the device-and CUDA modules-the analogue of dynamically loaded libraries for the device.Most applications do not use the driver API as they do not need this additional level of control and when using the runtime,context and module management are implicit,resulting in more concise code.The driver API is introduced in Driver API and fully described in the reference manual. 3.1.Compilation with NVCC Kernels can be written using the CUDA instruction set architecture,called PTX,which is described in the PTX reference manual.It is however usually more effective to use a high-level programming language such as C.In both cases,kernels must be compiled into binary code by nvee to execute on the device. nvee is a compiler driver that simplifies the process of compiling C or PTX code:It provides simple and familiar command line options and executes them by invoking the collection of tools that implement the different compilation stages.This section gives www.nvidia.com CUDA C Programming Guide PG-02829-001_v9.2|16
www.nvidia.com CUDA C Programming Guide PG-02829-001_v9.2 | 16 Chapter 3. PROGRAMMING INTERFACE CUDA C provides a simple path for users familiar with the C programming language to easily write programs for execution by the device. It consists of a minimal set of extensions to the C language and a runtime library. The core language extensions have been introduced in Programming Model. They allow programmers to define a kernel as a C function and use some new syntax to specify the grid and block dimension each time the function is called. A complete description of all extensions can be found in C Language Extensions. Any source file that contains some of these extensions must be compiled with nvcc as outlined in Compilation with NVCC. The runtime is introduced in Compilation Workflow. It provides C functions that execute on the host to allocate and deallocate device memory, transfer data between host memory and device memory, manage systems with multiple devices, etc. A complete description of the runtime can be found in the CUDA reference manual. The runtime is built on top of a lower-level C API, the CUDA driver API, which is also accessible by the application. The driver API provides an additional level of control by exposing lower-level concepts such as CUDA contexts - the analogue of host processes for the device - and CUDA modules - the analogue of dynamically loaded libraries for the device. Most applications do not use the driver API as they do not need this additional level of control and when using the runtime, context and module management are implicit, resulting in more concise code. The driver API is introduced in Driver API and fully described in the reference manual. 3.1. Compilation with NVCC Kernels can be written using the CUDA instruction set architecture, called PTX, which is described in the PTX reference manual. It is however usually more effective to use a high-level programming language such as C. In both cases, kernels must be compiled into binary code by nvcc to execute on the device. nvcc is a compiler driver that simplifies the process of compiling C or PTX code: It provides simple and familiar command line options and executes them by invoking the collection of tools that implement the different compilation stages. This section gives