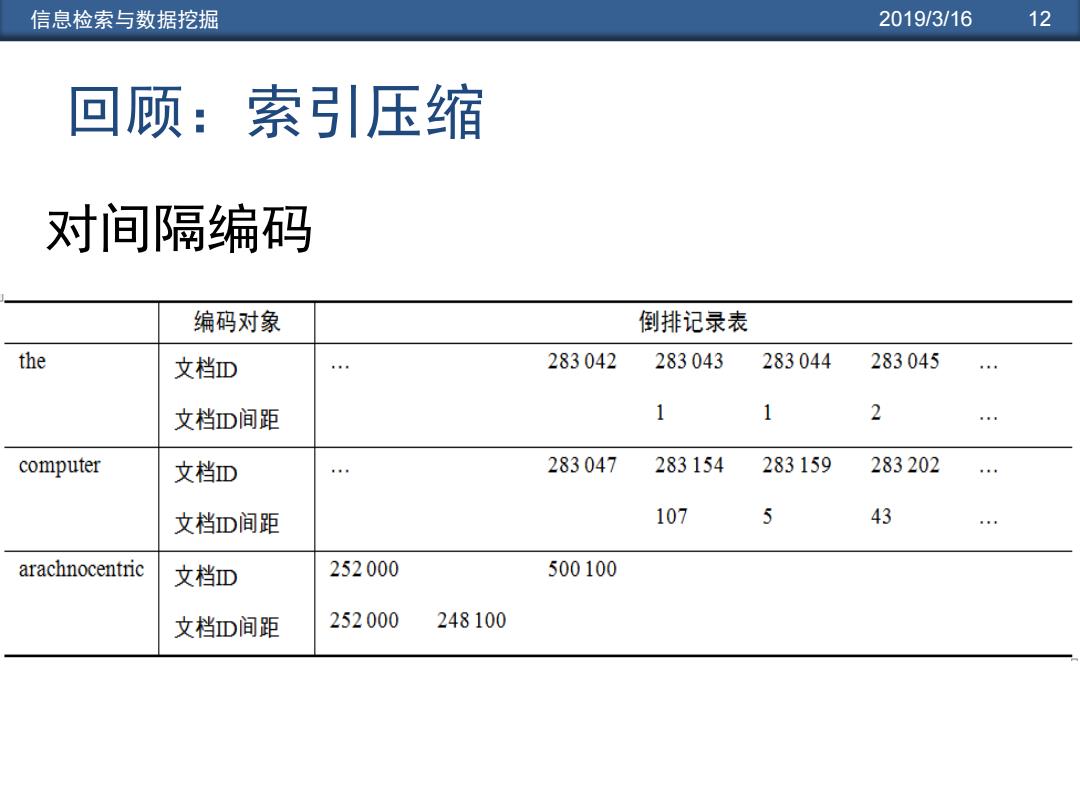
信息检索与数据挖掘 2019/3/16 12 回顾:索引压缩 对间隔编码 编码对象 倒排记录表 the 文档D 283042 283043 283044 283045 文档D间距 1 1 2 computer 文档D 283047 283154 283159 283202 文档D间距 107 5 43 arachnocentric 文档D 252000 500100 文档D间距 252000 248100
信息检索与数据挖掘 2019/3/16 12 对间隔编码 回顾:索引压缩

信息检索与数据挖掘 2019/3/16 13 回顾:索引压缩 可变字节(VB)码 ■被很多商用/研究系统所采用 ■设定一个专用位(高位)c作为延续位(continuation bit) ■如果间隔表示少于7比特,那么c置1,将间隔编入一个 字节的后7位中 ■否则:将低7位放入当前字节中,并将c置0,剩下的位 数采用同样的方法进行处理,最后一个字节的c置1(表示 结束)
信息检索与数据挖掘 2019/3/16 13 可变字节(VB)码 被很多商用/研究系统所采用 设定一个专用位 (高位) c作为延续位(continuation bit) 如果间隔表示少于7比特,那么c 置 1,将间隔编入一个 字节的后7位中 否则:将低7位放入当前字节中,并将c 置 0,剩下的位 数采用同样的方法进行处理,最后一个字节的c置1(表示 结束) 回顾:索引压缩

信息检索与数据挖掘 2019/3/16 14 回顾:索引压缩 Y编码 ■将G表示成长度(1 ength)和偏移(offset)两部分 偏移对应G的二进制编码,只不过将首部的1去掉 ■例如13→1101→101=偏移 ■长度部分给出的是偏移的位数 ■比如G=13(偏移为101),长度部分为3 长度部分采用一元编码:1110, ■于是G的丫编码就是将长度部分和偏移部分两者联接起来 得到的结果
信息检索与数据挖掘 2019/3/16 14 ϒ编码 将G 表示成长度(length)和偏移(offset)两部分 偏移对应G的二进制编码,只不过将首部的1去掉 例如 13 → 1101 → 101 = 偏移 长度部分给出的是偏移的位数 比如G=13 (偏移为 101), 长度部分为 3 长度部分采用一元编码: 1110. 于是G的ϒ编码就是将长度部分和偏移部分两者联接起来 得到的结果。 回顾:索引压缩
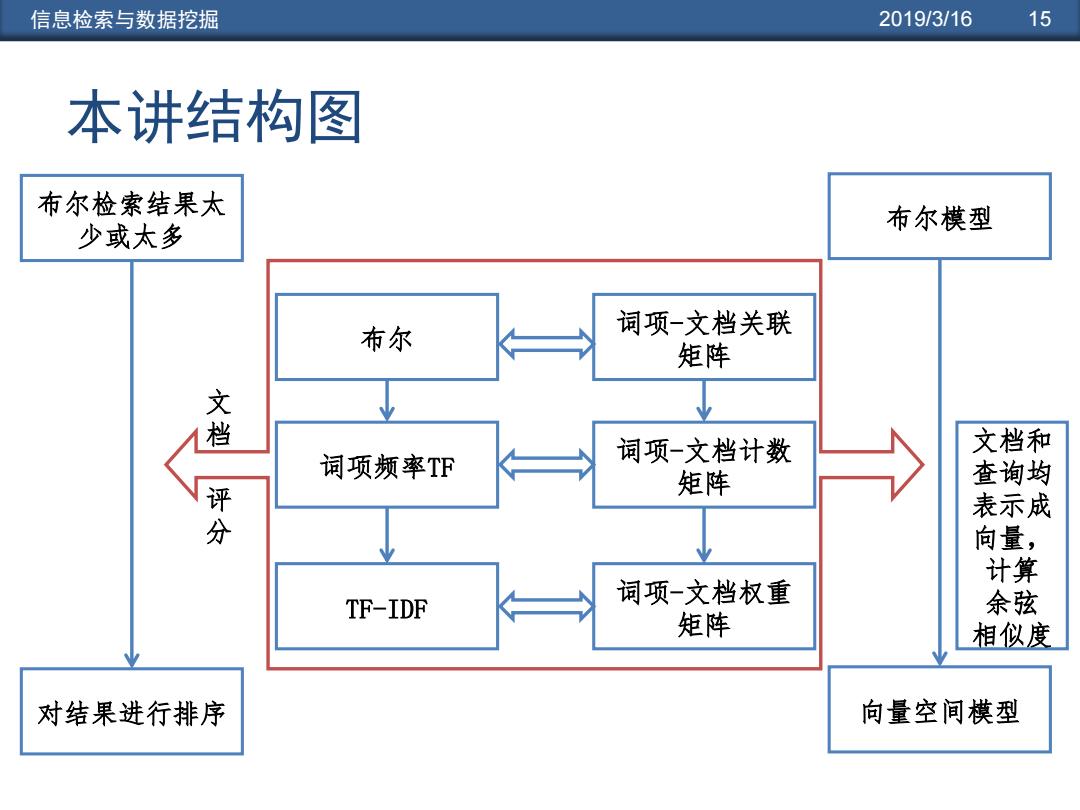
信息检索与数据挖掘 2019/3/16 15 本讲结构图 布尔检索结果太 布尔模型 少或太多 布尔 词项-文档关联 矩阵 接 词项-文档计数 文档和 词项频率TF 查询均 评 矩阵 表示成 分 向量, 计算 词项-文档权重 TF-IDF 余弦 矩阵 相似度 对结果进行排序 向量空间模型
信息检索与数据挖掘 2019/3/16 15 本讲结构图 文 档 评 分 布尔检索结果太 少或太多 对结果进行排序 词项频率TF TF-IDF 布尔 词项-文档计数 矩阵 词项-文档权重 矩阵 词项-文档关联 矩阵 布尔模型 向量空间模型 文档和 查询均 表示成 向量, 计算 余弦 相似度

信息检索与数据挖掘 2019/3/16 16 本讲提纲 1 回顾 排序式检索 3 词项频率 tf-idf权重计算 ⑤向量空间模型
信息检索与数据挖掘 2019/3/16 16 本讲提纲 ❶ 回顾 ❷ 排序式检索 ❸ 词项频率 ❹ tf-idf权重计算 ❺ 向量空间模型