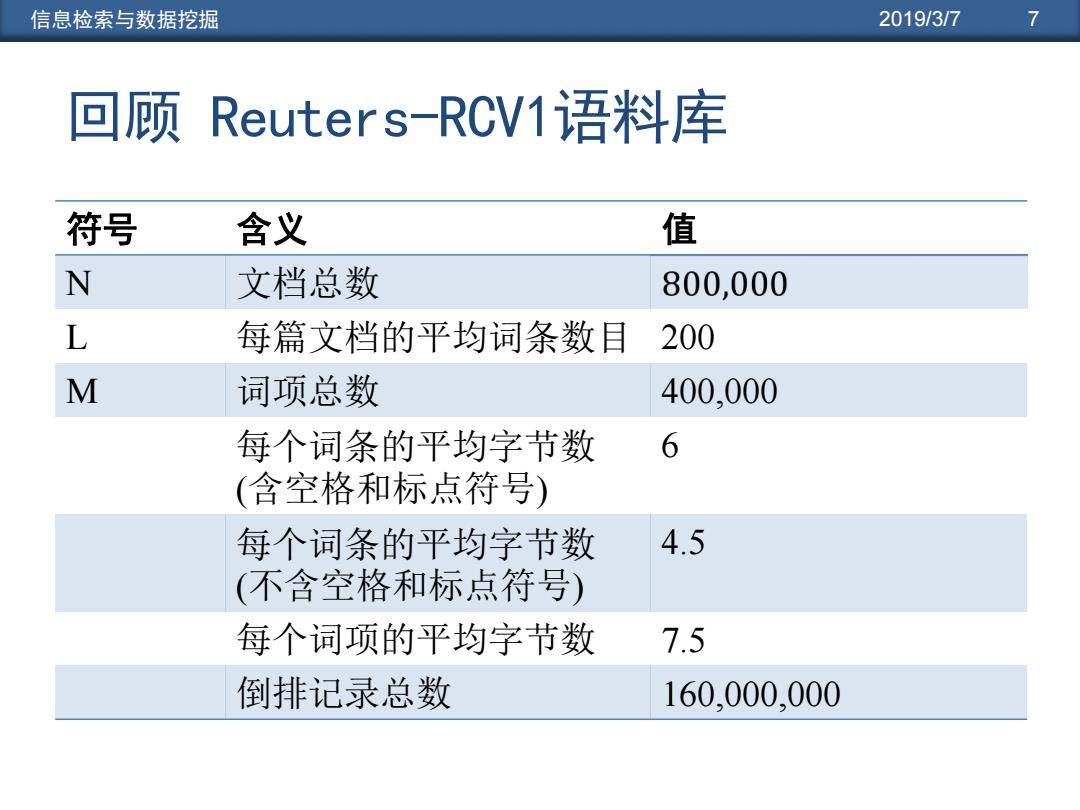
信息检索与数据挖掘 2019/3/7 7 回顾Reuters-RCV1语料库 符号 含义 值 N 文档总数 800,000 L 每篇文档的平均词条数目 200 M 词项总数 400,000 每个词条的平均字节数 6 (含空格和标点符号) 每个词条的平均字节数 4.5 (不含空格和标点符号) 每个词项的平均字节数 7.5 倒排记录总数 160,000,000
信息检索与数据挖掘 2019/3/7 7 回顾 Reuters-RCV1语料库 符号 含义 值 N 文档总数 L 每篇文档的平均词条数目 200 M 词项总数 400,000 每个词条的平均字节数 (含空格和标点符号) 6 每个词条的平均字节数 (不含空格和标点符号) 4.5 每个词项的平均字节数 7.5 倒排记录总数 160,000,000
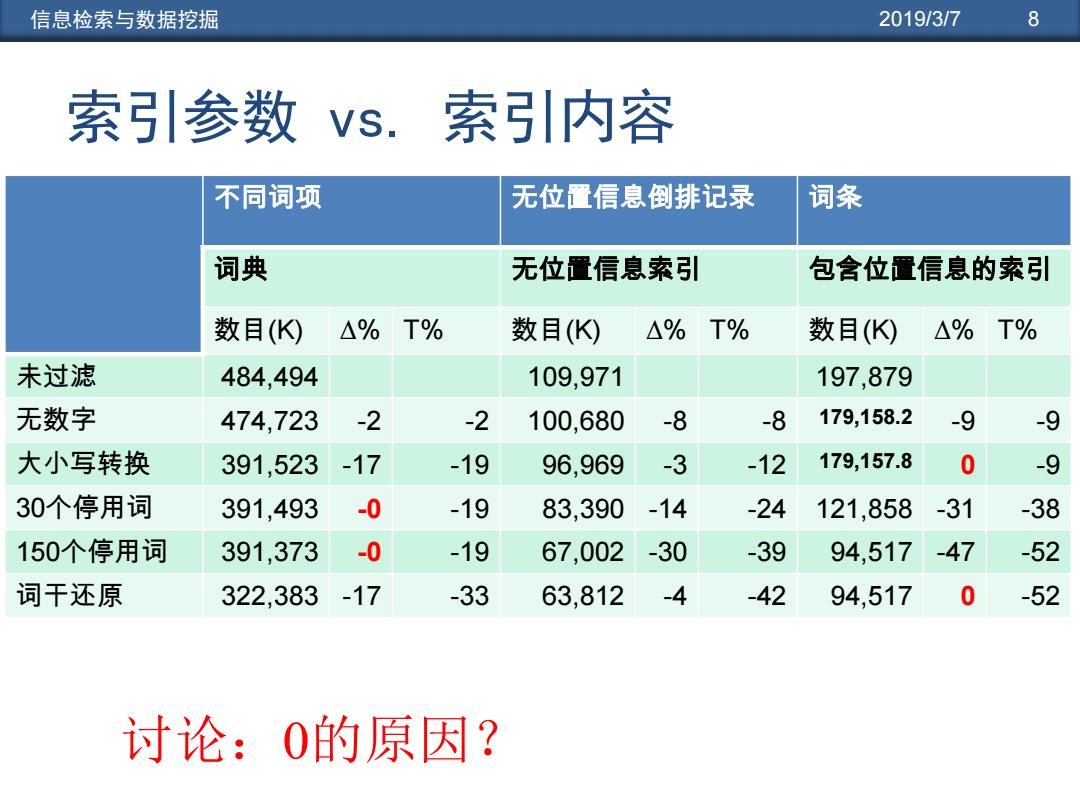
信息检索与数据挖掘 2019/3/7 8 索引参数vs.索引内容 不同词项 无位置信息倒排记录 词条 词典 无位置信息索引 包含位置信息的索引 数目(K △% T% 数目(K) △%T% 数目(K △%T% 未过滤 484,494 109,971 197,879 无数字 474,723 -2 -2 100,680 -8 -8 179,158.2 -9 -9 大小写转换 391,523 -17 -19 96,969 -3 -12 179,157.8 0 -9 30个停用词 391,493 -0 -19 83,390 -14 -24 121,858 -31 -38 150个停用词 391,373 -0 -19 67,002 -30 -39 94,517 -47 -52 词干还原 322,383-17 -33 63,812 -4 -42 94,517 0 -52 讨论:0的原因?
信息检索与数据挖掘 2019/3/7 8 索引参数 vs. 索引内容 不同词项 无位置信息倒排记录 词条 词典 无位置信息索引 包含位置信息的索引 数目(K) ∆% T% 数目(K) ∆% T% 数目(K) ∆% T% 未过滤 484,494 109,971 197,879 无数字 474,723 -2 -2 100,680 -8 -8 179,158.2 -9 -9 大小写转换 391,523 -17 -19 96,969 -3 -12 179,157.8 0 -9 30个停用词 391,493 -0 -19 83,390 -14 -24 121,858 -31 -38 150个停用词 391,373 -0 -19 67,002 -30 -39 94,517 -47 -52 词干还原 322,383 -17 -33 63,812 -4 -42 94,517 0 -52 讨论:0的原因?
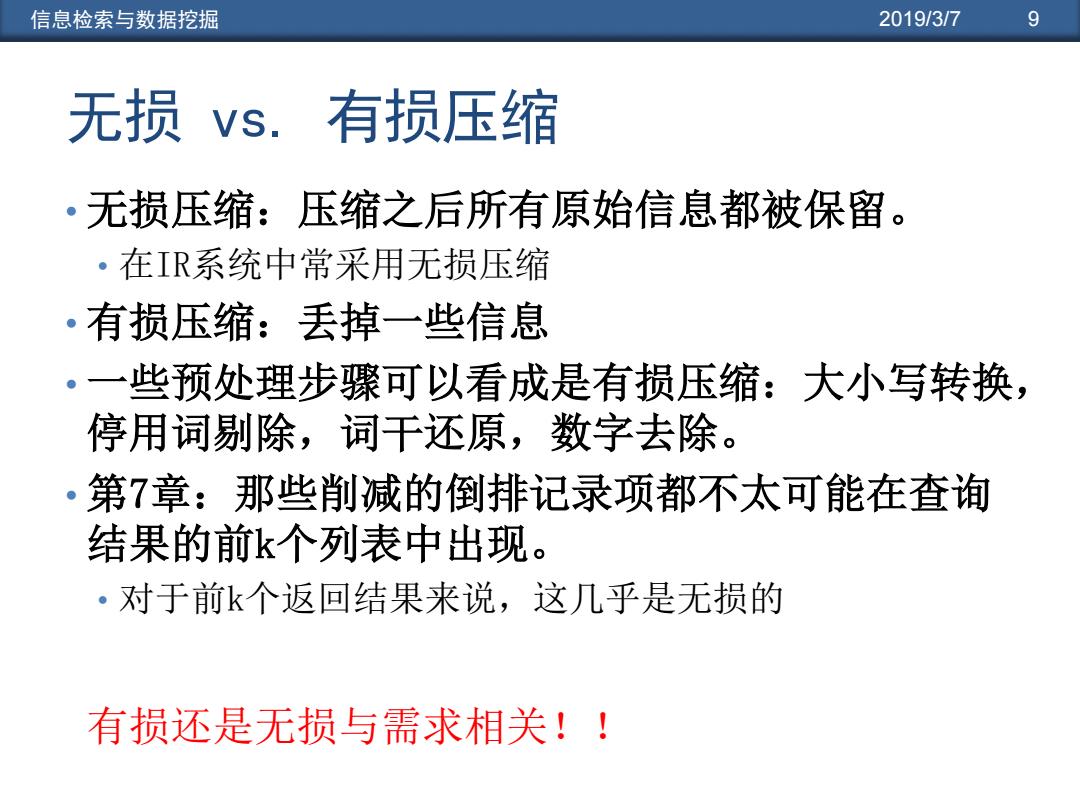
信息检索与数据挖掘 2019/3/7 9 无损vs.有损压缩 。无损压缩:压缩之后所有原始信息都被保留。 ·在IR系统中常采用无损压缩 ·有损压缩:丢掉一些信息 。一些预处理步骤可以看成是有损压缩:大小写转换, 停用词剔除,词干还原,数字去除。 ·第7章:那些削减的倒排记录项都不太可能在查询 结果的前k个列表中出现。 ·对于前k个返回结果来说,这几乎是无损的 有损还是无损与需求相关!!
信息检索与数据挖掘 2019/3/7 9 无损 vs. 有损压缩 • 无损压缩:压缩之后所有原始信息都被保留。 • 在IR系统中常采用无损压缩 • 有损压缩:丢掉一些信息 • 一些预处理步骤可以看成是有损压缩:大小写转换, 停用词剔除,词干还原,数字去除。 • 第7章:那些削减的倒排记录项都不太可能在查询 结果的前k个列表中出现。 • 对于前k个返回结果来说,这几乎是无损的 有损还是无损与需求相关!!
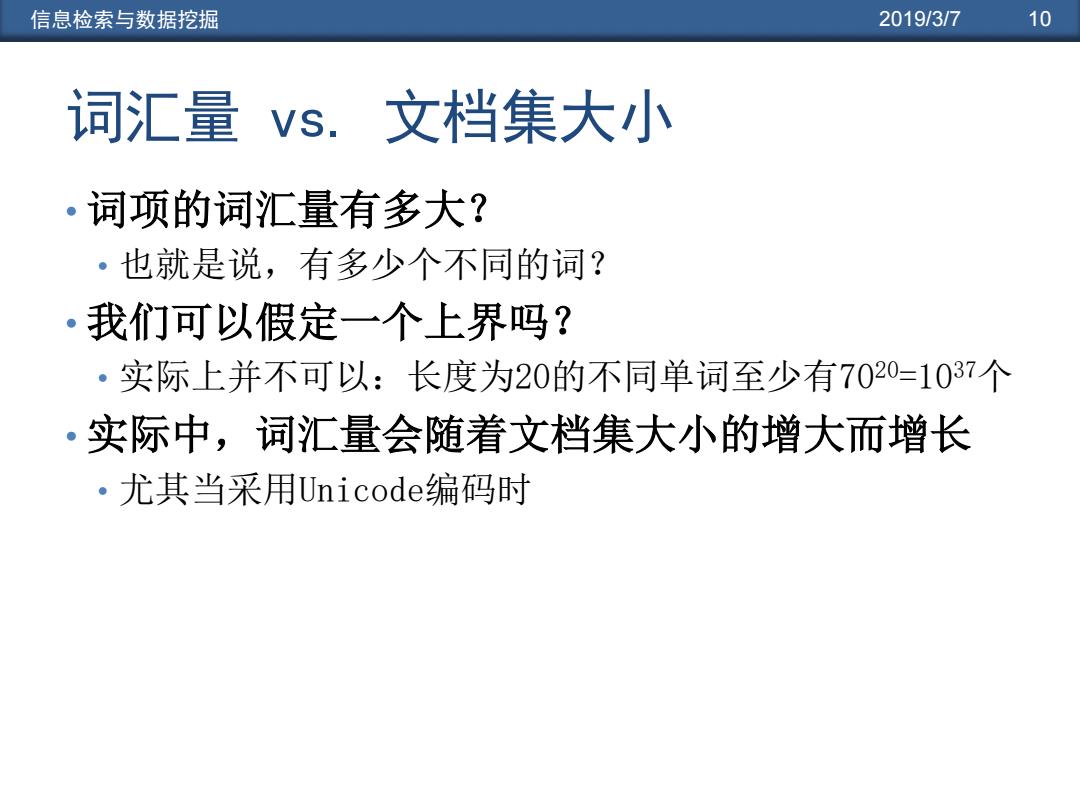
信息检索与数据挖掘 2019/3/7 10 词汇量vs.文档集大小 。词项的词汇量有多大? ·也就是说,有多少个不同的词? ·我们可以假定一个上界吗? ·实际上并不可以:长度为20的不同单词至少有7020=1037个 •实际中,词汇量会随着文档集大小的增大而增长 ·尤其当采用Unicode编码时
信息检索与数据挖掘 2019/3/7 10 词汇量 vs. 文档集大小 • 词项的词汇量有多大? • 也就是说,有多少个不同的词? • 我们可以假定一个上界吗? • 实际上并不可以:长度为20的不同单词至少有7020=1037个 • 实际中,词汇量会随着文档集大小的增大而增长 • 尤其当采用Unicode编码时
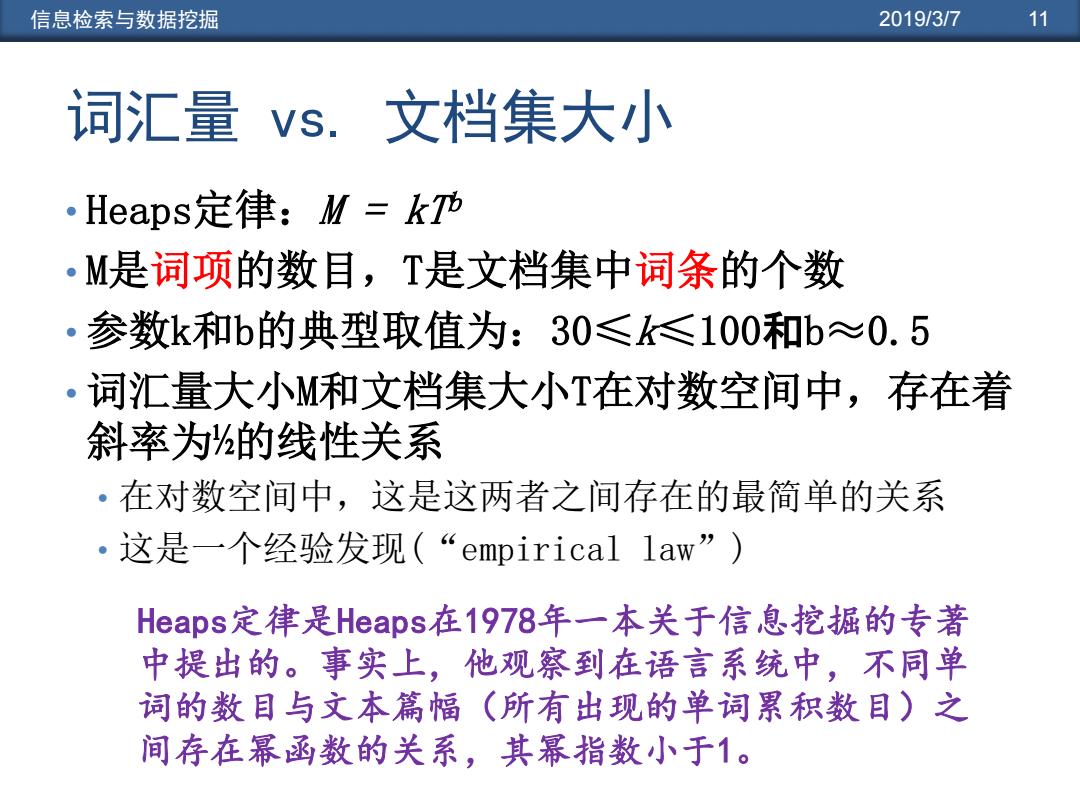
信息检索与数据挖掘 2019/3/7 11 词汇量vs.文档集大小 Heaps定律:M=kTb ·M是词项的数目,T是文档集中词条的个数 ·参数k和b的典型取值为:30≤≤100和b≈0.5 词汇量大小M和文档集大小T在对数空间中,存在着 。 斜率为的线性关系 ·在对数空间中,这是这两者之间存在的最简单的关系 ·这是一个经验发现(“empirical law”) Heaps.定律是Heaps在1978年一本关于信息挖掘的专著 中提出的。事实上,他观察到在语言系统中,不同单 词的数目与文本篇幅(所有出现的单词累积数目)之 间存在幂函数的关系,其幂指数小于1
信息检索与数据挖掘 2019/3/7 11 词汇量 vs. 文档集大小 • Heaps定律:M = kT b • M是词项的数目,T是文档集中词条的个数 • 参数k和b的典型取值为:30≤k≤100和b≈0.5 • 词汇量大小M和文档集大小T在对数空间中,存在着 斜率为½的线性关系 • 在对数空间中,这是这两者之间存在的最简单的关系 • 这是一个经验发现(“empirical law”) Heaps定律是Heaps在1978年一本关于信息挖掘的专著 中提出的。事实上,他观察到在语言系统中,不同单 词的数目与文本篇幅(所有出现的单词累积数目)之 间存在幂函数的关系,其幂指数小于1