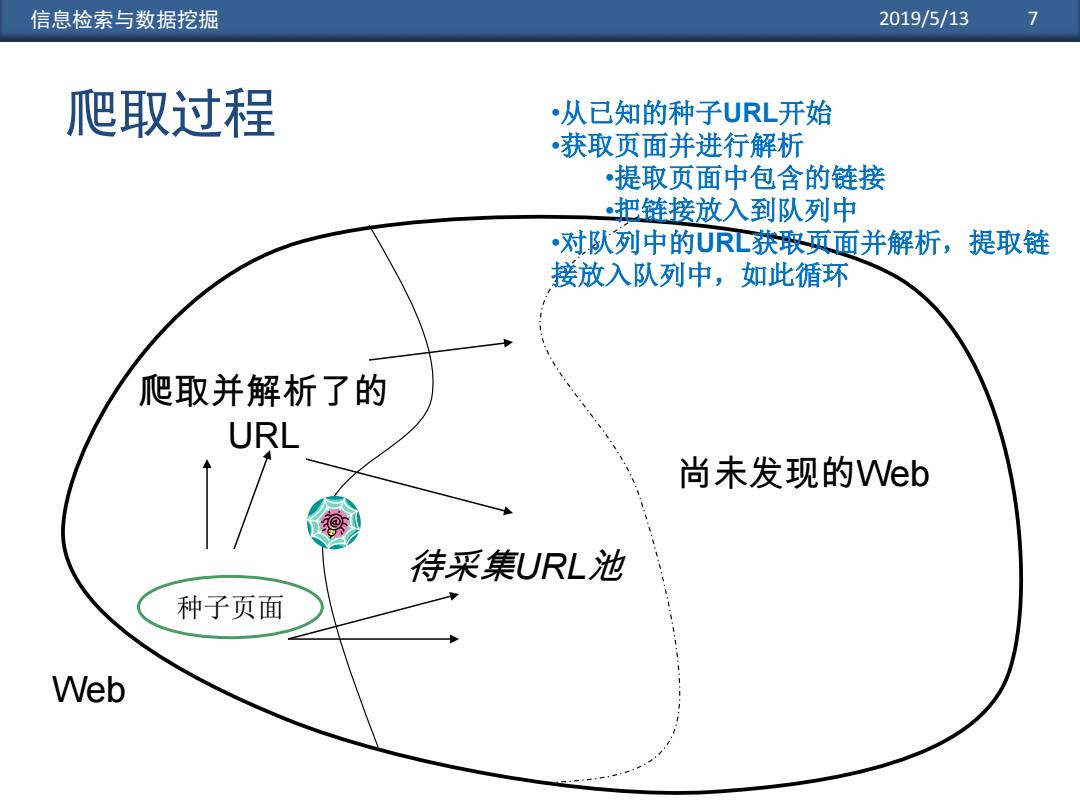
信息检索与数据挖掘 2019/5/13 7 爬取过程 从已知的种子URL开始 •获取页面并进行解析 •提取页面中包含的链接 把链接放入到队列中 •对队列中的URL获豫页面并解析,提取链 接放入队列中,如此循环 爬取并解析了的 URL 尚未发现的Web 待采集URL池 种子页面 Web
信息检索与数据挖掘 2019/5/13 7 爬取过程 Web 爬取并解析了的 URL 待采集URL池 尚未发现的Web 种子页面 •从已知的种子URL开始 •获取页面并进行解析 •提取页面中包含的链接 •把链接放入到队列中 •对队列中的URL获取页面并解析,提取链 接放入队列中,如此循环
信息检索与数据挖掘 2019/5/13 8 采集器必须具有的功能 ·礼貌性:Wb服务器有显示或隐式的策略控制采集器的访问 。只爬允许爬的内容、尊重robots.txt ·鲁棒性:能从采集器陷阱中跳出,能处理Wb服务器的其他 恶意行为 ·分布式:应该可以在多台机器上分布式运行 。可扩展性:添加更多机器后采集率应该提高 ·性能和效率:充分利用不同的系统资源,包括处理器、存储 器和网络带宽 ·优先抓取“有用的网页” ·新鲜度:对原来抓取的网页进行更新 。功能可扩展性:支持多方面的功能扩展,例如处理新的数 据格式、新的抓取协议等
信息检索与数据挖掘 2019/5/13 8 采集器必须具有的功能 • 礼貌性: Web服务器有显示或隐式的策略控制采集器的访问 • 只爬允许爬的内容、尊重 robots.txt • 鲁棒性: 能从采集器陷阱中跳出,能处理Web服务器的其他 恶意行为 • 分布式: 应该可以在多台机器上分布式运行 • 可扩展性: 添加更多机器后采集率应该提高 • 性能和效率: 充分利用不同的系统资源,包括处理器、存储 器和网络带宽 • 优先抓取“有用的网页” • 新鲜度: 对原来抓取的网页进行更新 • 功能可扩展性:支持多方面的功能扩展,例如处理新的数 据格式、新的抓取协议等

信息检索与数据挖掘 2019/5/13 9 礼貌性 Robots.txt源于1994年的协议,对爬取过程进行限制 htp:lwww.robotstxt..org/orig.html关于Robots.txt的说明 ·显式的礼貌:根据网站站长的说明,选择允许爬取 的部分进行爬取 。按robots.txt说的做,如下面写法的意思是:任何roboti都 不能访问“yoursite/temp/P”开头的网址,除了名叫 “searchengine的: □taobao.com https://www.taobao.com/robots.txt User-agent: User-agent:Baiduspider Disallow:/yoursite/temp/ Allow: /article Allow:/oshtml Disallow:/product/ User-agent:searchengine Disallow: User-Agent: Googlebot Disallow: Allow: /article Allow: /oshtml ·隐式的礼貌:即使没有特别的说明 8也应该频繁 Allow: /dianpu 的访问同一个网站 Allow: /oversea Allow: /list Disallow: User-agent:Bingbot
信息检索与数据挖掘 2019/5/13 9 礼貌性 • 显式的礼貌: 根据网站站长的说明,选择允许爬取 的部分进行爬取 • 按robots.txt说的做,如下面写法的意思是:任何robot都 不能访问 “/yoursite/temp/”开头的网址, 除了名叫 “searchengine”的: User-agent: * Disallow: /yoursite/temp/ User-agent: searchengine Disallow: • 隐式的礼貌: 即使没有特别的说明,也不应该频繁 的访问同一个网站 Robots.txt 源于1994年的协议,对爬取过程进行限制 http://www.robotstxt.org/orig.html 关于Robots.txt的说明
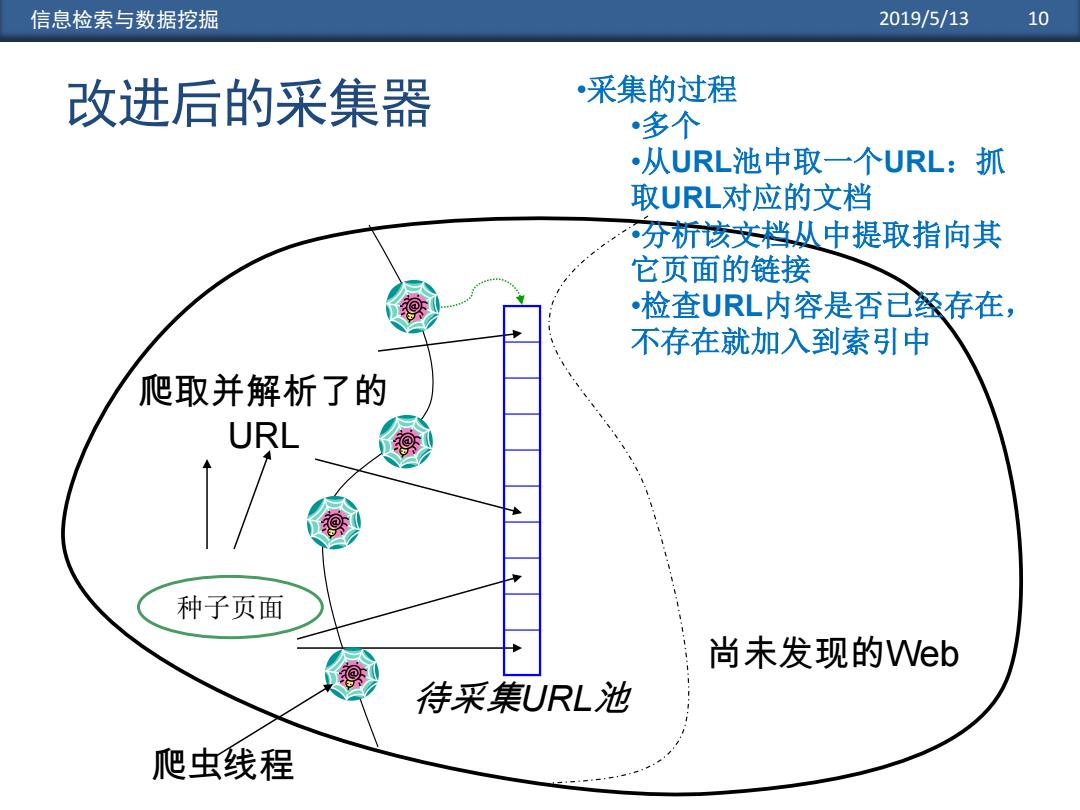
信息检索与数据挖掘 2019/5/13 10 改进后的采集器 采集的过程 多个 从URL池中取一个URL:抓 取URL对应的文档 分析该文档丛中提取指向其 它页面的链接 检查URL内容是否已经存在, 不存在就加入到索引中 爬取并解析了的 URL 种子页面 尚未发现的Web 待采集URL池 爬虫线程
信息检索与数据挖掘 2019/5/13 10 改进后的采集器 爬取并解析了的 URL 尚未发现的Web 种子页面 待采集URL池 爬虫线程 •采集的过程 •多个 •从URL池中取一个URL:抓 取URL对应的文档 •分析该文档从中提取指向其 它页面的链接 •检查URL内容是否已经存在, 不存在就加入到索引中
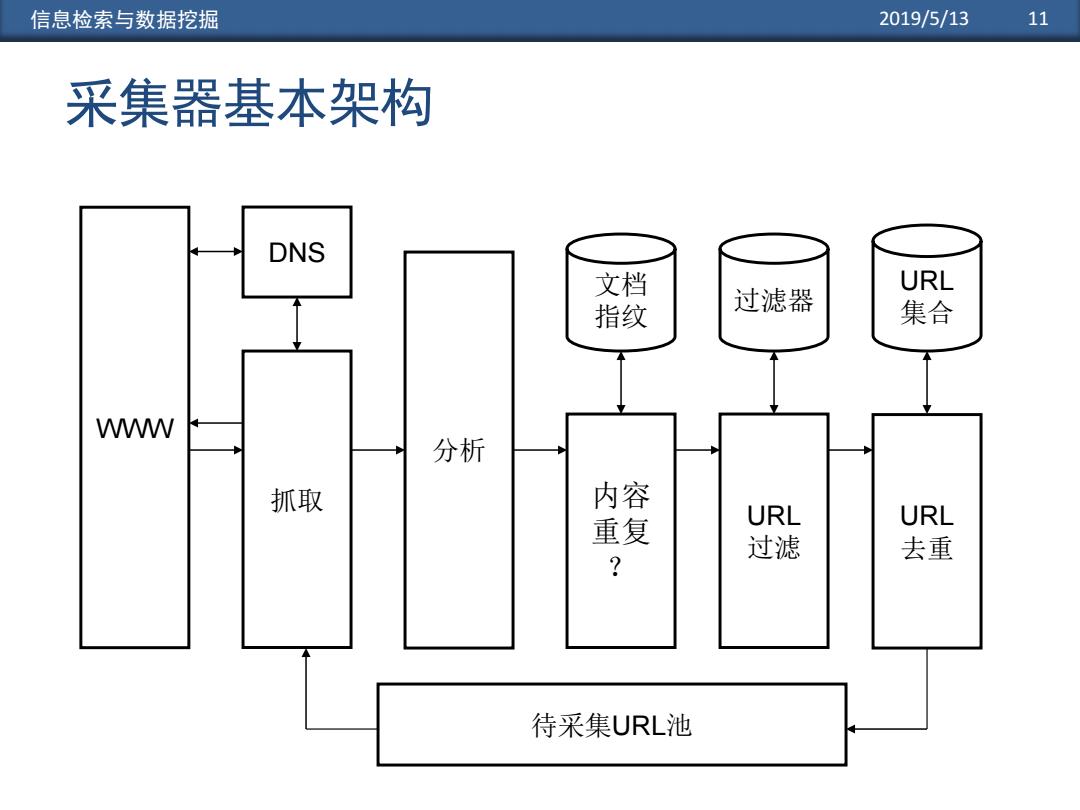
信息检索与数据挖掘 2019/5/13 11 采集器基本架构 DNS 文 URL 指纹 过滤器 集合 W 分析 抓取 内容 重复 URL URL 过滤 去重 待采集URL池
信息检索与数据挖掘 2019/5/13 11 采集器基本架构 WWW DNS 分析 内容 重复 ? 文档 指纹 URL 去重 URL 集合 待采集URL池 URL 过滤 过滤器 抓取