
CUDA编程指南4.0中文版 8 的块,索引为(xy,z)的线程D为(x+yDx+zDxDy)(译者注:这和我们使用C 数组的方式不一样,大家注意理解)。 下面的例子代码将两个长度为NN的矩阵A和B相加,然后将结果写入矩 阵C。 ∥Kernel definition global void MatAdd(float A[N][N],float B[N][N],float C[N][N]){ int i=threadldx.x; int j=threadldx.y; C[[]=A[]+BG } int main(){ /Kernel invocation with one block of NN 1 threads int numBlocks=1: dim3 threadsPerBlock(N,N); MatAdd<<<numBlocks,threadsPerBlock>>(A,B,C); 由于块内的所有线程必须存在于同一个处理器核心中且共享该核心有限的 存储器资源,因此,一个块内的线程数目是有限的。在目前的GPU上,一个线 程块可以包含多达1024个线程。 然而,一个内核可被多个同样大小的线程块执行,所以总的线程数等于每个 块内的线程数乘以线程块数。 线程块被组织成一维、二维或三维的线程网格,如图2-1所示。一个网格内 的线程块数往往由被处理的数据量而不是系统的处理器数决定,前者往往远超后 者
CUDA 编程指南 4.0 中文版 8 的块,索引为(x,y,z)的线程 ID 为(x+yDx+zDxDy)(译者注:这和我们使用 C 数组的方式不一样,大家注意理解)。 下面的例子代码将两个长度为 N*N 的矩阵 A 和 B 相加,然后将结果写入矩 阵 C。 由于块内的所有线程必须存在于同一个处理器核心中且共享该核心有限的 存储器资源,因此,一个块内的线程数目是有限的。在目前的 GPU 上,一个线 程块可以包含多达 1024 个线程。 然而,一个内核可被多个同样大小的线程块执行,所以总的线程数等于每个 块内的线程数乘以线程块数。 线程块被组织成一维、二维或三维的线程网格,如图 2-1 所示。一个网格内 的线程块数往往由被处理的数据量而不是系统的处理器数决定,前者往往远超后 者。 // Kernel definition __global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]){ int i = threadIdx.x; int j = threadIdx.y; C[i][j] = A[i][j] + B[i][j]; } int main() { ... // Kernel invocation with one block of N * N * 1 threads int numBlocks = 1; dim3 threadsPerBlock(N, N); MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C); }
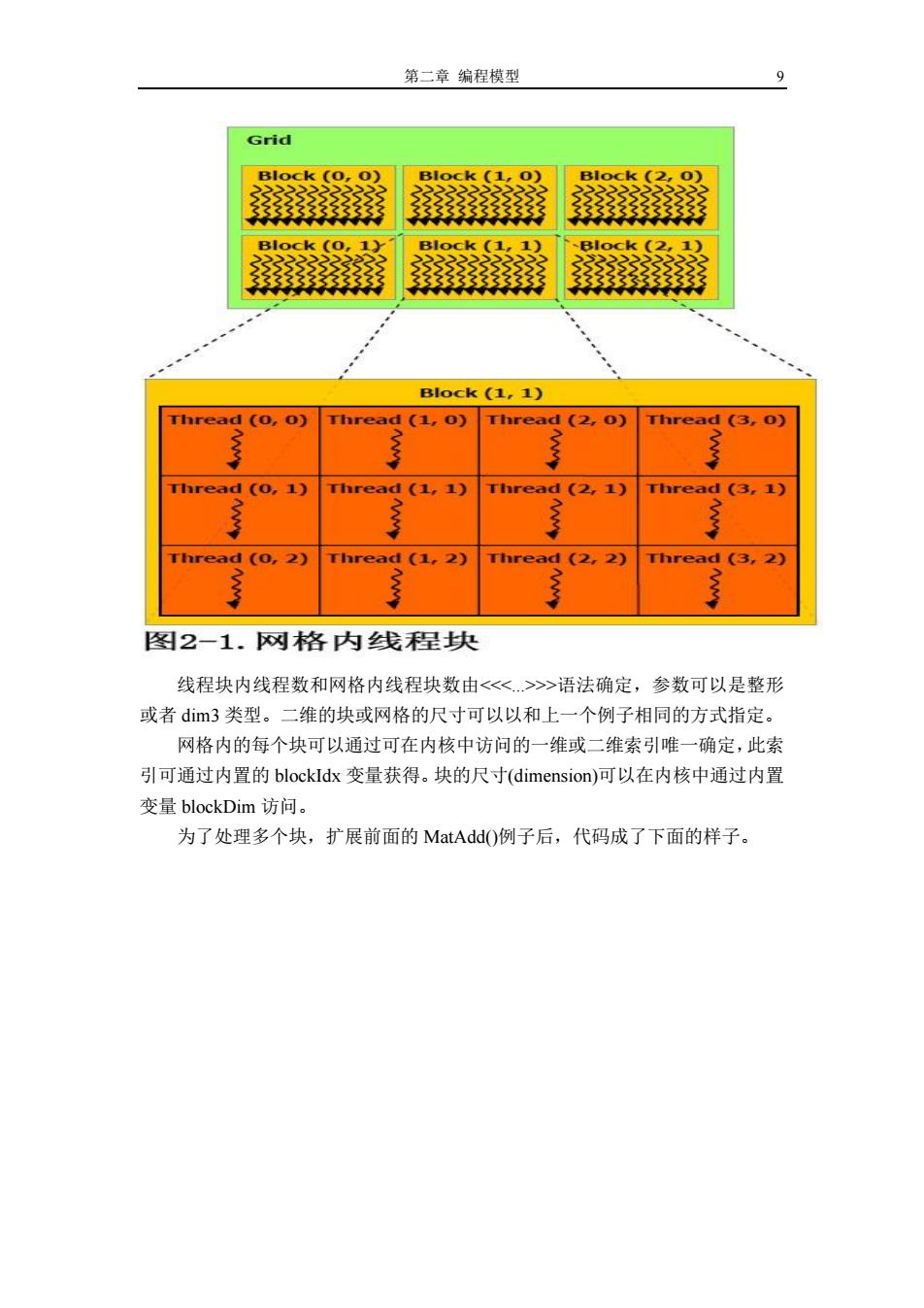
第二章编程模型 9 Grid Block (o,0) Block (1,0) Block (2,0) Block(O,1 Block (L,1) Block (2,1) Block (1,1) Thread (o,o) Thread (1,o) Thread (2,0) Thread (3,o) Thread (0,1) Thread (1,1) Thread (2,1) Thread (3,1) Thread (o,2) Thread (1,2) Thread (2,2) Thread (3,2) 图2一1.网格内线程块 线程块内线程数和网格内线程块数由<<>>语法确定,参数可以是整形 或者dim3类型。二维的块或网格的尺寸可以以和上一个例子相同的方式指定。 网格内的每个块可以通过可在内核中访问的一维或二维索引唯一确定,此索 引可通过内置的blockIdx变量获得。块的尺寸(dimension)可以在内核中通过内置 变量blockDim访问。 为了处理多个块,扩展前面的MatAddO)例子后,代码成了下面的样子
第二章 编程模型 9 线程块内线程数和网格内线程块数由<<<...>>>语法确定,参数可以是整形 或者 dim3 类型。二维的块或网格的尺寸可以以和上一个例子相同的方式指定。 网格内的每个块可以通过可在内核中访问的一维或二维索引唯一确定,此索 引可通过内置的 blockIdx 变量获得。块的尺寸(dimension)可以在内核中通过内置 变量 blockDim 访问。 为了处理多个块,扩展前面的 MatAdd()例子后,代码成了下面的样子

CUDA编程指南4.0中文版 10 ∥Kernel definition global void MatAdd(float A[N][N],float B[N][N],float C[N][N]) int i=blockldx.x blockDim.x+threadldx.x; int j=blockIdx.y blockDim.y +threadldx.y; if (i<N&&j<N) C[]=A[]+B: } int main(){ ∥Kernel invocation dim3 threadsPerBlock(16,16); dim3 numBlocks(N threadsPerBlock.x,N/threadsPerBlock.y); MatAdd<<<numBlocks,threadsPerBlock>>(A,B,C); } 一个长度为16*16(256线程)的块,虽然是强制指定,但是常见。像以前 一样,创建了内有足够的块的网格,使得一个线程处理一个矩阵元素。为简便起 见,此例假设网格每一维上的线程数可被块内对应维上的线程数整除,尽管这并 不常见。 线程块必须独立执行。而且能够以任意顺序,串行或者并行执行。这种独立 性要求使得线程块可以以任何顺序在任意数目核心上调度,如图1-4所示,保证 了程序员能够写出能够随核心数目扩展的代码(enabling programmers to write code that scales with the number of cores). 块内线程可通过共享存储器和同步执行协作,共享存储器可以共享数据,同 步执行可以协调存储器访问。更精确一点说,可以在内核中调用_syncthreads() 内置函数指明同步点;syncthreads(O起栅栏的作用,在其调用点,块内线程必 须等待,直到所以线程都到达此点才能向前执行。3.2.3节给出了一个使用共享 存储器的例子。 为了能有效协作,共享存储器要求是靠近每个处理器核心的低延迟存储器 (更像L1缓存),而且syncthreads()要是轻量级的。 2.3存储器层次 在执行期间,CUDA线程可能访问来自多个存储器空间的数据,如图2-2所 示。每个线程有私有的本地存储器。每个块有对块内所有线程可见的共享存储器, 共享存储器的生命期和块相同。所有的线程可访问同一全局存储器。 另外还有两种可被所有线程访问的只读存储器:常量和纹理存储器空间。全 局,常量和纹理存储器空间为不同的存储器用途作了优化(参看5.3.2.1节,5.3.2.4 节和5.3.2.5节)。纹理存储器还为一些特殊数据格式提供了不同的寻址模式和数
CUDA 编程指南 4.0 中文版 10 一个长度为 16*16(256 线程)的块,虽然是强制指定,但是常见。像以前 一样,创建了内有足够的块的网格,使得一个线程处理一个矩阵元素。为简便起 见,此例假设网格每一维上的线程数可被块内对应维上的线程数整除,尽管这并 不常见。 线程块必须独立执行。而且能够以任意顺序,串行或者并行执行。这种独立 性要求使得线程块可以以任何顺序在任意数目核心上调度,如图 1-4 所示,保证 了程序员能够写出能够随核心数目扩展的代码(enabling programmers to write code that scales with the number of cores)。 块内线程可通过共享存储器和同步执行协作,共享存储器可以共享数据,同 步执行可以协调存储器访问。更精确一点说,可以在内核中调用__syncthreads() 内置函数指明同步点;__syncthreads()起栅栏的作用,在其调用点,块内线程必 须等待,直到所以线程都到达此点才能向前执行。3.2.3 节给出了一个使用共享 存储器的例子。 为了能有效协作,共享存储器要求是靠近每个处理器核心的低延迟存储器 (更像 L1 缓存),而且__syncthreads()要是轻量级的。 2.3 存储器层次 在执行期间,CUDA 线程可能访问来自多个存储器空间的数据,如图 2-2 所 示。每个线程有私有的本地存储器。每个块有对块内所有线程可见的共享存储器, 共享存储器的生命期和块相同。所有的线程可访问同一全局存储器。 另外还有两种可被所有线程访问的只读存储器:常量和纹理存储器空间。全 局,常量和纹理存储器空间为不同的存储器用途作了优化(参看 5.3.2.1 节,5.3.2.4 节和 5.3.2.5 节)。纹理存储器还为一些特殊数据格式提供了不同的寻址模式和数 // Kernel definition __global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]){ int i = blockIdx.x * blockDim.x + threadIdx.x; int j = blockIdx.y * blockDim.y + threadIdx.y; if (i < N && j < N) C[i][j] = A[i][j] + B[i][j]; } int main(){ ... // Kernel invocation dim3 threadsPerBlock(16, 16); dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y); MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C); }
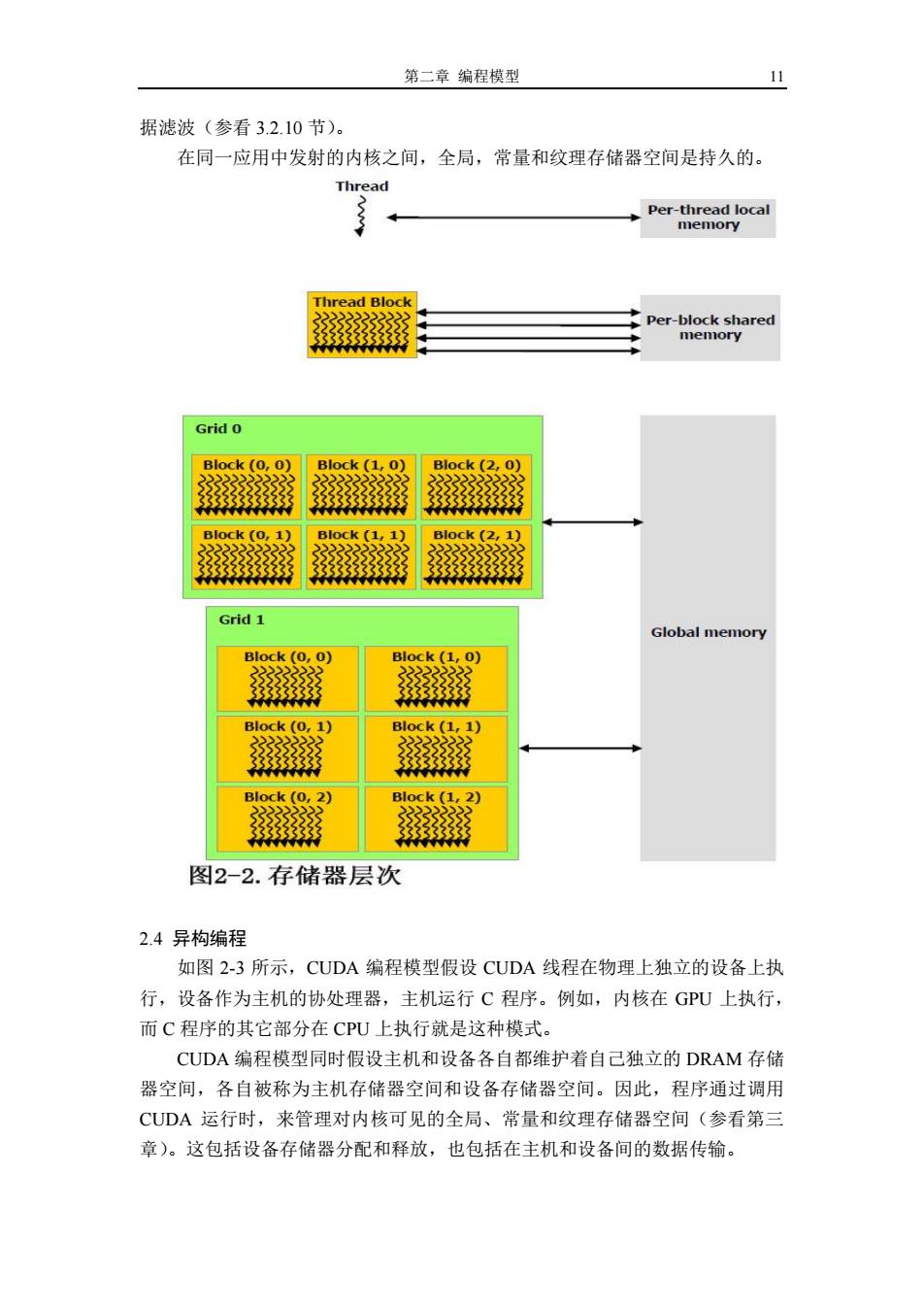
第二章编程模型 11 据滤波(参看3.2.10节)。 在同一应用中发射的内核之间,全局,常量和纹理存储器空间是持久的。 Thread Per-thread local memory Thread Block Per-block shared 333333333333 memory Grid 0 Block (0,0) Block (1,0) Block (2,0) 2222222 Block(0,1) Block (1,1) B1ock(2,1) Grid 1 Global memory Block (0,0) Block (1,0) 333333333 电 Block(0,1) Block(1,1) Block(0,2) Block (1,2) 图2-2.存储器层次 2.4异构编程 如图2-3所示,CUDA编程模型假设CUDA线程在物理上独立的设备上执 行,设备作为主机的协处理器,主机运行C程序。例如,内核在GPU上执行, 而C程序的其它部分在CPU上执行就是这种模式。 CUDA编程模型同时假设主机和设备各自都维护着自己独立的DRAM存储 器空间,各自被称为主机存储器空间和设备存储器空间。因此,程序通过调用 CUDA运行时,来管理对内核可见的全局、常量和纹理存储器空间(参看第三 章)。这包括设备存储器分配和释放,也包括在主机和设备间的数据传输
第二章 编程模型 11 据滤波(参看 3.2.10 节)。 在同一应用中发射的内核之间,全局,常量和纹理存储器空间是持久的。 2.4 异构编程 如图 2-3 所示,CUDA 编程模型假设 CUDA 线程在物理上独立的设备上执 行,设备作为主机的协处理器,主机运行 C 程序。例如,内核在 GPU 上执行, 而 C 程序的其它部分在 CPU 上执行就是这种模式。 CUDA 编程模型同时假设主机和设备各自都维护着自己独立的 DRAM 存储 器空间,各自被称为主机存储器空间和设备存储器空间。因此,程序通过调用 CUDA 运行时,来管理对内核可见的全局、常量和纹理存储器空间(参看第三 章)。这包括设备存储器分配和释放,也包括在主机和设备间的数据传输
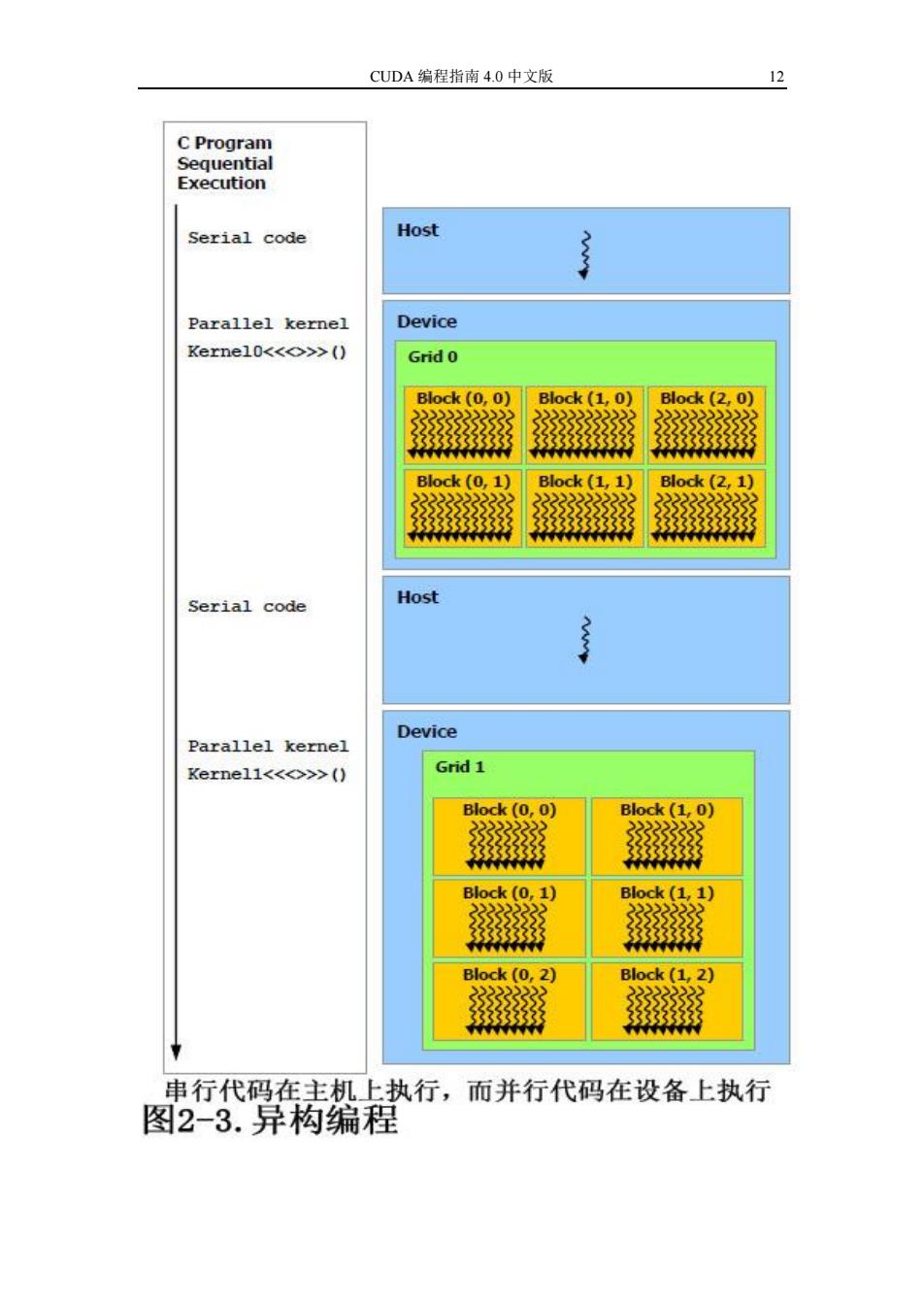
CUDA编程指南4.0中文版 12 C Program Sequential Execution Serial code Host Parallel kernel Device Kernel0<<o>>() Grid 0 Block(0.0) Block (1.0) Block(2,0) 3333333 3333333333 333333333 Block (0,1) Block(1,1) Block(2,1) 33333 Serial code Host Device Parallel kernel Kerne11<<◇>>() Grid 1 Block(0,0) Block(1,0) Block(0,1) Block (1,1) Block (0,2) Block(1,2) 22222222 串行代码在主机上执行,而并行代码在设备上执行 图2-3.异构编程
CUDA 编程指南 4.0 中文版 12