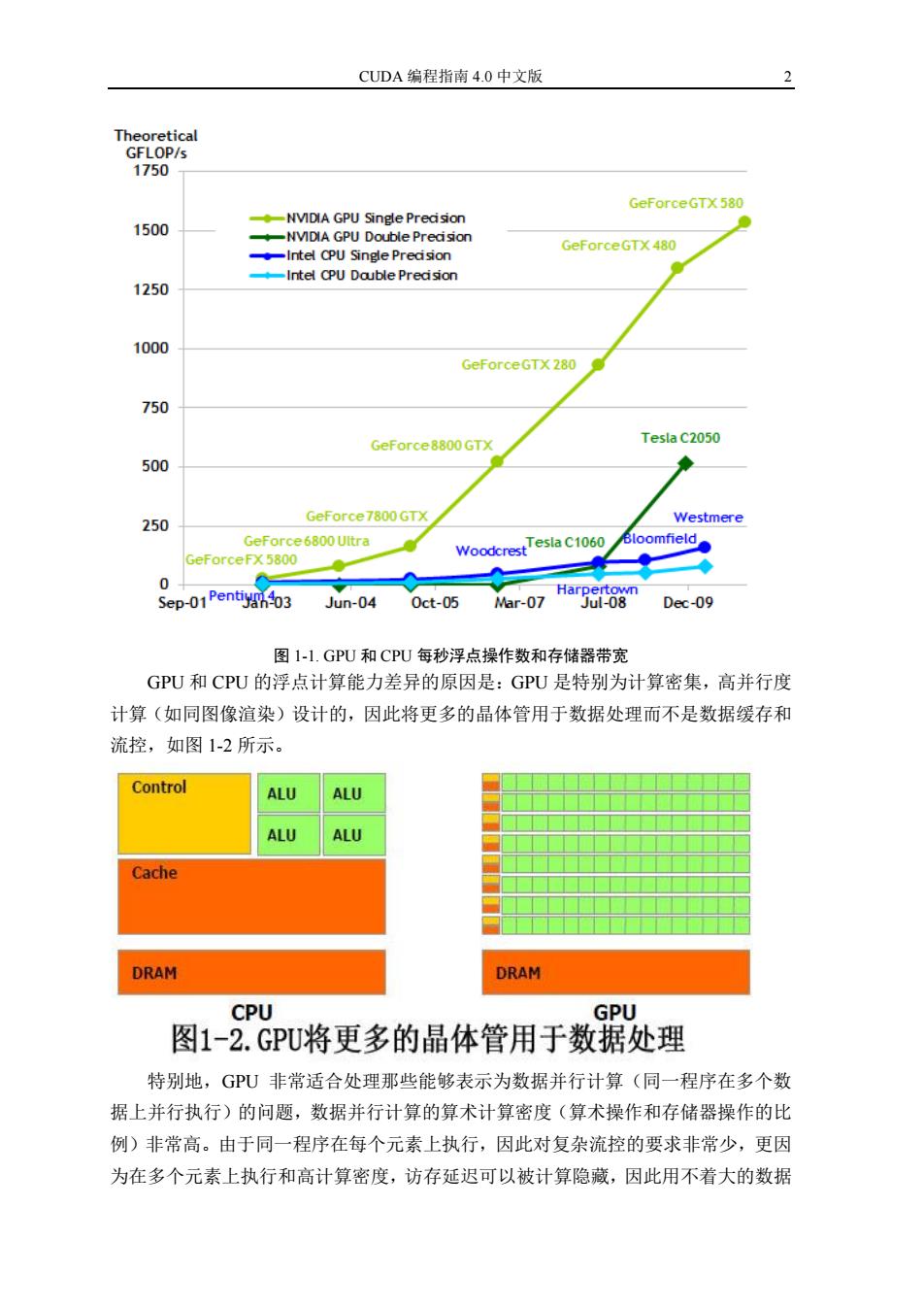
CUDA编程指南4.0中文版 3 Theoretical GFLOP/s 1750 GeForceGTX580 ◆MDIA GPU Single Preasion 1500 NVIDIA GPU Double Precision GeForceGTX480 Intel CPU Single Precision Intel CPU Double Precision 1250 1000 GeForceGTX 280 750 GeForce8800 GTX Tesla C2050 500 250 GeForce7800GTX Westmere GeForce6800 Ultra Bloomfield GeForceFX 5800 WoodcrestTesla C1060 0 Sep-01Pentiyan403 Harpertown Jun-04 0ct-05 ar-07 Jul-08 Dec-09 图1-L.GPU和CPU每秒浮点操作数和存储器带宽 GPU和CPU的浮点计算能力差异的原因是:GPU是特别为计算密集,高并行度 计算(如同图像渲染)设计的,因此将更多的晶体管用于数据处理而不是数据缓存和 流控,如图1-2所示。 Control ALU ALU ALU ALU Cache DRAM DRAM CPU GPU 图1-2.GPU将更多的晶体管用于数据处理 特别地,GPU非常适合处理那些能够表示为数据并行计算(同一程序在多个数 据上并行执行)的问题,数据并行计算的算术计算密度(算术操作和存储器操作的比 例)非常高。由于同一程序在每个元素上执行,因此对复杂流控的要求非常少,更因 为在多个元素上执行和高计算密度,访存延迟可以被计算隐藏,因此用不着大的数据
CUDA 编程指南 4.0 中文版 2 图 1-1. GPU 和 CPU 每秒浮点操作数和存储器带宽 GPU 和 CPU 的浮点计算能力差异的原因是:GPU 是特别为计算密集,高并行度 计算(如同图像渲染)设计的,因此将更多的晶体管用于数据处理而不是数据缓存和 流控,如图 1-2 所示。 特别地,GPU 非常适合处理那些能够表示为数据并行计算(同一程序在多个数 据上并行执行)的问题,数据并行计算的算术计算密度(算术操作和存储器操作的比 例)非常高。由于同一程序在每个元素上执行,因此对复杂流控的要求非常少,更因 为在多个元素上执行和高计算密度,访存延迟可以被计算隐藏,因此用不着大的数据

第一章导论 缓存。 数据并行处理将数据元素映射到并行处理的线程上。很多处理大的数据集的应用 可以使用数据并行处理模型加速。三维图像渲染处理中,大量的像素和顶点被映射到 并行线程。类似地,图像和多媒体处理应用、图像渲染的后处理、视频编解码、图像 缩放、立体视觉和模式识别能够将图像块和像素映射到并行处理的线程。实际上,除 了图像渲染和处理领域,还有很多算法已被数据并行处理加速,从普通信号处理或物 理模拟到计算金融或计算生物学。 1.2 CUDATM:一种通用并行计算架构 2006年11月,英伟达推出了CUDATM,一种基于新的并行编程模型和指令集架 构的通用计算架构,CUDA能够利用英伟达GPU的并行计算引擎比CPU更高效的 解决许多复杂计算任务。 CUDA包含一个让开发者能够使用C作为高级编程语言的软件环境。如图1-3 所示,其它的语言和应用编程接口(API)也被支持,如CUDA FORTRAN,OpenCL 和Direct Compute。 GPU Computing Applications Libraries and Middleware 0 y 下4y LAPACK R C++ OpenCL- Direct Java and Compute Fortran Python NVIDIA GPU with the CUDA Parallel Computing Architecture Fermi Architecture GeForce 500 Series GeForce 400 Serles Quadro Fermi Series Tesia 20 Serles (Compute capabilities 2.x) Tesla Architecture GeForce 200 Serles Quadro FX Series Quadro Plex Series Tesla 10 Series (Compute capabllities 1.x) GeForce8 Series Quadro NVS Series Computing 图1-3.CUDA设计为支持多种语言和应用编程接口 1.3一种可扩展的编程模型 多核CPU和众核GPU的出现,意味着主流处理器芯片现在已经是并行系统了。 更进一步的说,他们的并行度将继续以摩尔定律扩展。面临的挑战是开发透明的扩展 并行度以利用不断增加的处理器核心数的应用软件,更像三维图形应用透明的扩展他
第一章 导论 3 缓存。 数据并行处理将数据元素映射到并行处理的线程上。很多处理大的数据集的应用 可以使用数据并行处理模型加速。三维图像渲染处理中,大量的像素和顶点被映射到 并行线程。类似地,图像和多媒体处理应用、图像渲染的后处理、视频编解码、图像 缩放、立体视觉和模式识别能够将图像块和像素映射到并行处理的线程。实际上,除 了图像渲染和处理领域,还有很多算法已被数据并行处理加速,从普通信号处理或物 理模拟到计算金融或计算生物学。 1.2 CUDATM:一种通用并行计算架构 2006 年 11 月,英伟达推出了 CUDATM,一种基于新的并行编程模型和指令集架 构的通用计算架构,CUDA 能够利用英伟达 GPU 的并行计算引擎比 CPU 更高效的 解决许多复杂计算任务。 CUDA 包含一个让开发者能够使用 C 作为高级编程语言的软件环境。如图 1-3 所示,其它的语言和应用编程接口(API)也被支持,如 CUDA FORTRAN,OpenCL 和 Direct Compute。 图 1-3. CUDA 设计为支持多种语言和应用编程接口 1.3 一种可扩展的编程模型 多核 CPU 和众核 GPU 的出现,意味着主流处理器芯片现在已经是并行系统了。 更进一步的说,他们的并行度将继续以摩尔定律扩展。面临的挑战是开发透明的扩展 并行度以利用不断增加的处理器核心数的应用软件,更像三维图形应用透明的扩展他
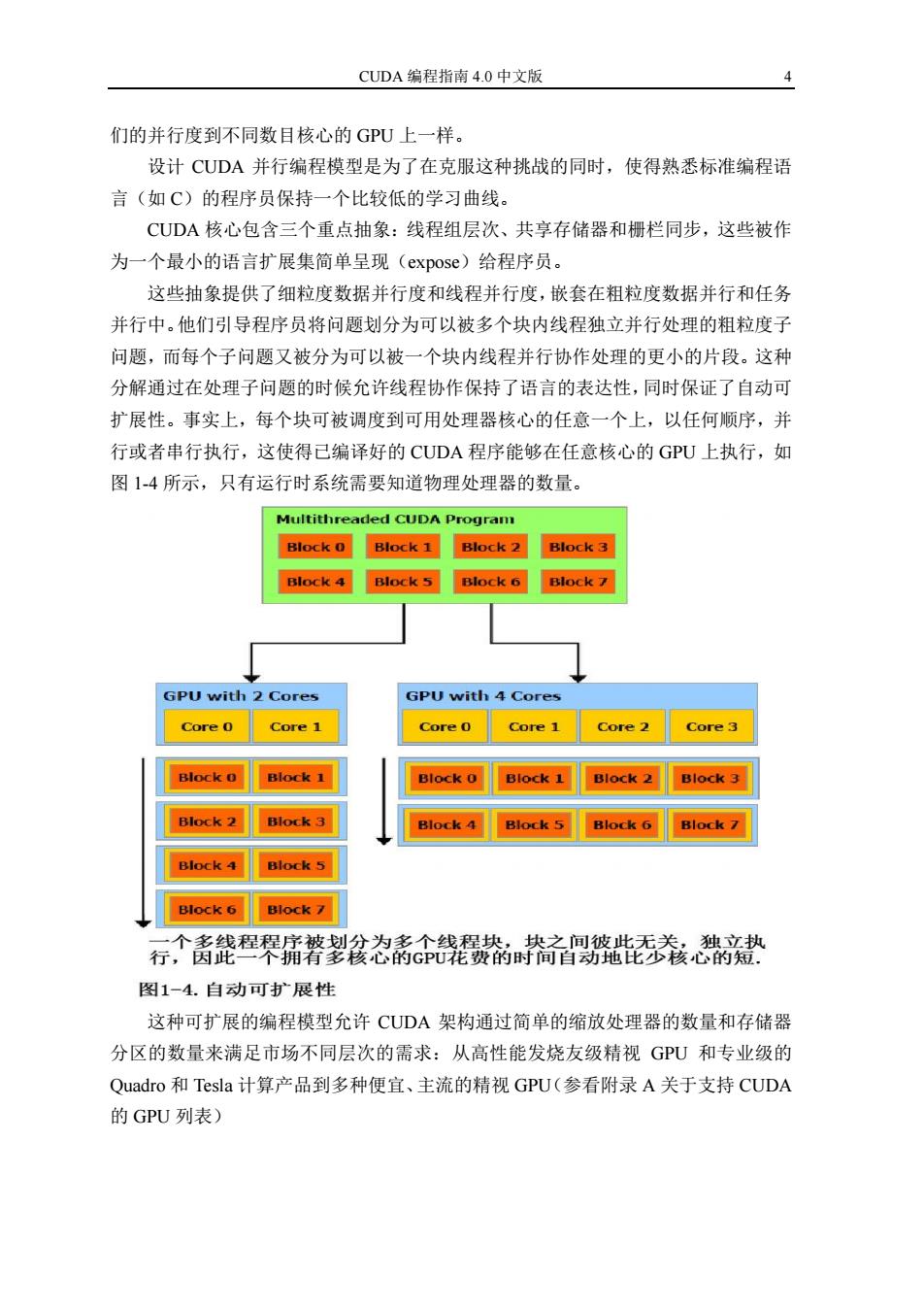
CUDA编程指南4.0中文版 们的并行度到不同数目核心的GPU上一样。 设计CUDA并行编程模型是为了在克服这种挑战的同时,使得熟悉标准编程语 言(如C)的程序员保持一个比较低的学习曲线。 CUDA核心包含三个重点抽象:线程组层次、共享存储器和栅栏同步,这些被作 为一个最小的语言扩展集简单呈现(expose)给程序员。 这些抽象提供了细粒度数据并行度和线程并行度,嵌套在粗粒度数据并行和任务 并行中。他们引导程序员将问题划分为可以被多个块内线程独立并行处理的粗粒度子 问题,而每个子问题又被分为可以被一个块内线程并行协作处理的更小的片段。这种 分解通过在处理子问题的时候允许线程协作保持了语言的表达性,同时保证了自动可 扩展性。事实上,每个块可被调度到可用处理器核心的任意一个上,以任何顺序,并 行或者串行执行,这使得己编译好的CUDA程序能够在任意核心的GPU上执行,如 图1-4所示,只有运行时系统需要知道物理处理器的数量。 Multithreaded CUDA Program Block 0 Block 1 Block 2 Block 3 Block 4 Block 5 Block 6 Block 7 GPU with 2 Cores GPU with 4 Cores Core 0 Core 1 Core0 Core 1 Core 2 Core 3 Block 0 Block 1 Block 0 Block 1 Block 2 Block 3 Block 2 Block 3 Block 4 Block 5 Block 6 Block 7 Block 4 Block 5 Block 6 Block 7 一个多线程程序被划分为多个线程块,块之间彼此无关,独立执 行,因此一个拥有多核心的GPU花费的时间自动地比少核心的短. 图1一4.自动可扩展性 这种可扩展的编程模型允许CUDA架构通过简单的缩放处理器的数量和存储器 分区的数量来满足市场不同层次的需求:从高性能发烧友级精视GPU和专业级的 Quadro和Tesla计算产品到多种便宜、主流的精视GPU(参看附录A关于支持CUDA 的GPU列表)
CUDA 编程指南 4.0 中文版 4 们的并行度到不同数目核心的 GPU 上一样。 设计 CUDA 并行编程模型是为了在克服这种挑战的同时,使得熟悉标准编程语 言(如 C)的程序员保持一个比较低的学习曲线。 CUDA 核心包含三个重点抽象:线程组层次、共享存储器和栅栏同步,这些被作 为一个最小的语言扩展集简单呈现(expose)给程序员。 这些抽象提供了细粒度数据并行度和线程并行度,嵌套在粗粒度数据并行和任务 并行中。他们引导程序员将问题划分为可以被多个块内线程独立并行处理的粗粒度子 问题,而每个子问题又被分为可以被一个块内线程并行协作处理的更小的片段。这种 分解通过在处理子问题的时候允许线程协作保持了语言的表达性,同时保证了自动可 扩展性。事实上,每个块可被调度到可用处理器核心的任意一个上,以任何顺序,并 行或者串行执行,这使得已编译好的 CUDA 程序能够在任意核心的 GPU 上执行,如 图 1-4 所示,只有运行时系统需要知道物理处理器的数量。 这种可扩展的编程模型允许 CUDA 架构通过简单的缩放处理器的数量和存储器 分区的数量来满足市场不同层次的需求:从高性能发烧友级精视 GPU 和专业级的 Quadro 和 Tesla 计算产品到多种便宜、主流的精视 GPU(参看附录 A 关于支持 CUDA 的 GPU 列表)

第一章导论 1.4文档结构 本文档包括以下各章 ■第一章、CUDA基本介绍 ■第二章、CUDA编程模型要点 ■第三章、编程接口描述 ■第四章、硬件实现描述 ■第五章、性能优化指南 ■附录A、支持CUDA的GPU列表 ■附录B、CUDA C扩展的详细说明 ■附录C、CUDA支持的数学函数列表 ■附录D、设备代码支持的C++特性列表 ■附录E、更详细的纹理存取说明 ■附录F、给出各种设备的技术规范,更多架构详细说明
第一章 导论 5 1.4 文档结构 本文档包括以下各章 第一章、CUDA 基本介绍 第二章、CUDA 编程模型要点 第三章、编程接口描述 第四章、硬件实现描述 第五章、性能优化指南 附录 A、支持 CUDA 的 GPU 列表 附录 B、CUDA C 扩展的详细说明 附录 C、CUDA 支持的数学函数列表 附录 D、设备代码支持的 C++特性列表 附录 E、更详细的纹理存取说明 附录 F、给出各种设备的技术规范,更多架构详细说明

第二章编程模型 7 第二章编程模型 本章引入了CUDA编程模型背后的主要概念,方式是概述它们是怎样使用 C语言表示的。更多的关于CUDA C的描述在第三章。 本章使用的向量相加例子的完整代码和下一个例子可在SDK中的vectorAdd 代码样本中找到。 2.1内核 CUDA通过允许程序员定义称为内核的C函数扩展了C,内核调用时会被N 个CUDA线程执行N次(译者注:这句话要好好理解,其实每个线程只执行了 一次),这和普通的C函数只执行一次不同。 内核使用global声明符定义,使用一种新<<.>>执行配置语法指定执 行某一指定内核调用的线程数(参看附录B.16)。每个执行内核的线程拥有一个 独一无二的线程ID,可以通过内置的threadIdx变量在内核中访问(译者注:这 只说明在块内是唯一的,并不一定是全局唯一的)。 下面的样本代码将两个长度为N的向量A和B相加,并将结果存入向量C 中。 //Kernel definition global void VecAdd(float*A,float*B,float*C) int i threadldx.x: C=A[+B[: } int main() //Kernel invocation with N threads VecAdd<<<1,N>>>(A,B,C); } 这里,N个线程中的每一个执行VecAdd()的一次成对加法(译者注:由于 只使用了一个块,因此线程D是唯一的)。 2.2线程层次 为简便起见,threadIdx是一个有3个组件的向量,所以线程可以使用一维, 二维,三维索引标识,形成一维,二维,三维的线程块。这提供了一种自然的方 式来调用作用在域内元素上的计算,如向量,矩阵,体元(volume)。 线程索引和线程D直接相关:对于一维的块,它们相同:对于二维长度为 (Dx,Dy)的块,线程索引为(x,y)的线程D是(x+yDx):对于三维长度为(Dx,Dy,Dz)
第二章 编程模型 7 第二章 编程模型 本章引入了 CUDA 编程模型背后的主要概念,方式是概述它们是怎样使用 C 语言表示的。更多的关于 CUDA C 的描述在第三章。 本章使用的向量相加例子的完整代码和下一个例子可在SDK中的vectorAdd 代码样本中找到。 2.1 内核 CUDA 通过允许程序员定义称为内核的 C 函数扩展了 C,内核调用时会被 N 个 CUDA 线程执行 N 次(译者注:这句话要好好理解,其实每个线程只执行了 一次),这和普通的 C 函数只执行一次不同。 内核使用__global__声明符定义,使用一种新<<<...>>>执行配置语法指定执 行某一指定内核调用的线程数(参看附录 B.16)。每个执行内核的线程拥有一个 独一无二的线程 ID,可以通过内置的 threadIdx 变量在内核中访问(译者注:这 只说明在块内是唯一的,并不一定是全局唯一的)。 下面的样本代码将两个长度为 N 的向量 A 和 B 相加,并将结果存入向量 C 中。 这里,N 个线程中的每一个执行 VecAdd()的一次成对加法(译者注:由于 只使用了一个块,因此线程 ID 是唯一的)。 2.2 线程层次 为简便起见,threadIdx 是一个有 3 个组件的向量,所以线程可以使用一维, 二维,三维索引标识,形成一维,二维,三维的线程块。这提供了一种自然的方 式来调用作用在域内元素上的计算,如向量,矩阵,体元(volume)。 线程索引和线程 ID 直接相关:对于一维的块,它们相同;对于二维长度为 (Dx,Dy)的块,线程索引为(x,y)的线程 ID 是(x+yDx);对于三维长度为(Dx,Dy,Dz) // Kernel definition __global__ void VecAdd(float* A, float* B, float* C){ int i = threadIdx.x; C[i] = A[i] + B[i]; } int main(){ ... // Kernel invocation with N threads VecAdd<<<1, N>>>(A, B, C); }