
22 大规模并行处理器编程实战 像素着色器在同一处理器上执行。 在图形流水线中,特定阶段对完全独立的数据执行大量的浮点运算,如改变三角形图 元顶点的位置或者产生像素的颜色等。作为主要应用特征的数据独立性(data independence) 是GPU和CPU的假想设计的一个重要区别。一帧在1/60秒的时间内渲染一次,可能会产 生100万个三角形图元和600万个像素。使用硬件并行性来利用数据独立性的可能性很大。 在一些图形流水线阶段中执行的特定功能会因渲染算法的不同而变化。这种变化促使 硬件设计师采用可编程的图形流水线阶段。两个特殊的可编程阶段如下:顶点着色器和像 素着色器。顶点着色器程序将三角形图元的顶点坐标映射到屏幕上,并改变它们的位置、 颜色或方向。通常,一个顶点着色线程读取一个用四维浮点坐标(x,y,z,w)表示的顶点 位置,并计算出这个顶点的三维浮点坐标(x,y,z)在屏幕上的位置。几何着色器程序对由 多个顶点定义的几何图元(primitive))进行操作,改变这些图元或者生成附加的几何图元。 顶点着色器程序和几何着色器程序都在图形流水线的顶点着色(VS/T&L)阶段执行。 每个着色程序负责计算RGBA(Red Green Blue Alpha,RGBA)的浮点值,在像素样本 (x,y)图像位置上渲染图像时要用到这些颜色的浮点值。这些程序在图形流水线的着色阶 段执行。对于三种图形着色程序,程序实例能并行执行,因为每个阶段都是工作在独立的 数据上,并产生独立的结果,且相互之间没有任何副作用。正是这种特点促使设计方案从 可编程流水线阶段向大规模并行处理器上转移。 图2-4是一个可编程流水线的示例,它要用到顶点处理器和片元(像素)处理器。可编 程顶点处理器执行那些为顶点着色阶段设计的程序,而可编程片元(fragment)处理器执行那 些为像素着色阶段设计的程序。这些可编程的图形流水线由数十个固定功能的阶段组成, 每一个功能阶段比可编程处理器更加高效地执行明确定义的任务,从而从可编程性中获益 不少。例如,在顶点处理阶段和像素(片元)处理阶段之间有一个光栅处理器(光栅化与插值)。 它是一个复杂的状态机,用来确定哪些像素(及部分)处在每个几何图元的边界上。总之, 为了在渲染算法中平衡极端性能和用户控件,设计了用于结合可编程阶段和固定功能阶段 的技术。 普通的渲染算法能执行单个几何图元的输入,并采用高度一致的方式访问其他存储器 资源。也就是说,这些算法往往可以同时访问连续存储器的位置,如所有相邻三角形图元 或所有相邻像素点。因此,这些算法对存储器带宽的利用率相当高,而且对存储器延时不 敏感。再结合一个计算能力有限的像素着色器的工作负载,这些特点引导着GPU沿不同 于CPU的方向发展。特别是,CPU的芯片面积由缓存决定,而GPU的芯片面积则由浮 点数据通路和固定功能逻辑决定。GPU存储器接口更重视带宽而不是延时(大规模并行执 行会隐藏延时)。事实上,GPU带宽己经超出CPU带宽许多倍,在最近的设计中已经超 过100GB/s
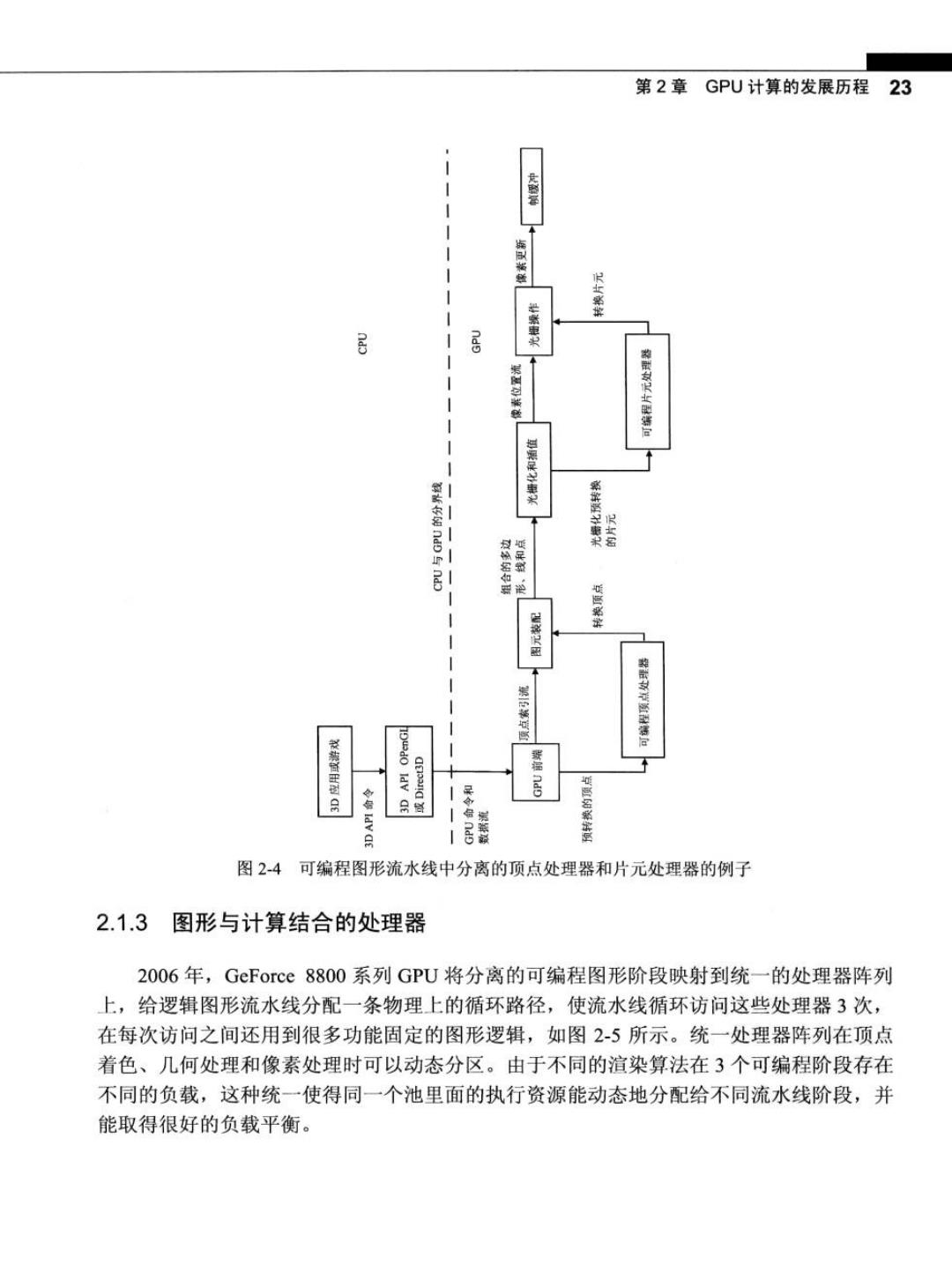
第2章GPU计算的发展历程 23 品 居 ldv 月 居 图2-4可编程图形流水线中分离的顶点处理器和片元处理器的例子 2.1.3图形与计算结合的处理器 2006年,GeForce8800系列GPU将分离的可编程图形阶段映射到统一的处理器阵列 上,给逻辑图形流水线分配一条物理上的循环路径,使流水线循环访问这些处理器3次, 在每次访问之间还用到很多功能固定的图形逻辑,如图2-5所示。统一处理器阵列在顶点 着色、几何处理和像素处理时可以动态分区。由于不同的渲染算法在3个可编程阶段存在 不同的负载,这种统一使得同一个池里面的执行资源能动态地分配给不同流水线阶段,并 能取得很好的负载平衡
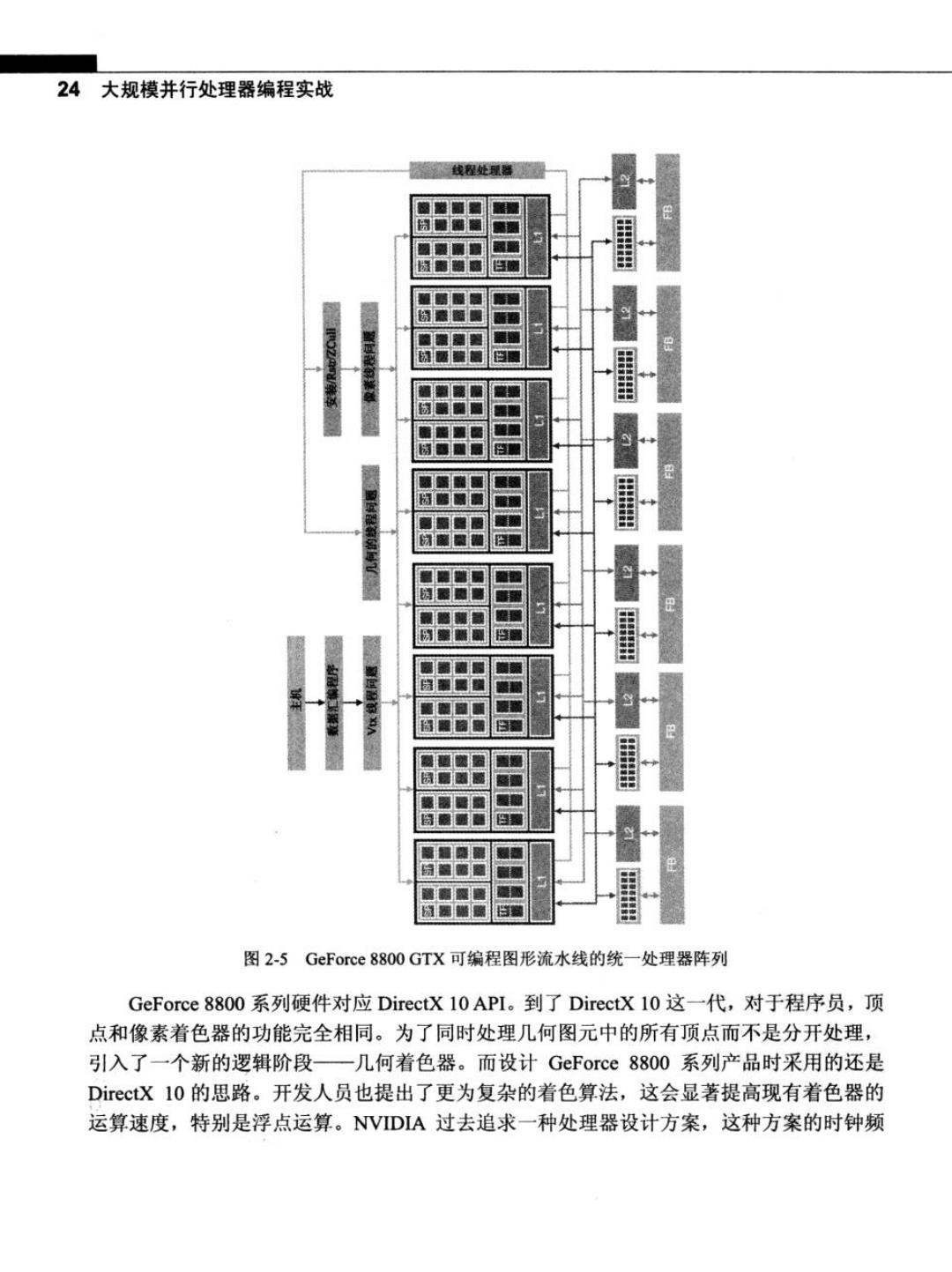
24大规模并行处理器编程实战 战程处理燃 图2-5 GeForce8800GTX可编程图形流水线的统一处理器阵列 GeForce8800系列硬件对应DirectX10API。到了DirectX 10这一代,对于程序员,顶 点和像素着色器的功能完全相同。为了同时处理几何图元中的所有顶点而不是分开处理, 引入了一个新的逻辑阶段一几何着色器。而设计GeForce8800系列产品时采用的还是 DirectX 10的思路。开发人员也提出了更为复杂的着色算法,这会显著提高现有着色器的 运算速度,特别是浮点运算。NVIDIA过去追求一种处理器设计方案,这种方案的时钟频

第2章GPU计算的发展历程25 率比标准单元方法中允许的要高,目的是尽可能提高单位面积上预期操作的吞吐量。但实 质上这种高时钟频率要求在工程上付出更多努力,因此鉴于新的几何阶段,选择设计一个 处理器阵列而不是两个或3个处理器,这是有好处的。在接受统一处理器的工程技术挑战 的同时,通过在处理器阵列的线程上进行负载均衡并提高逻辑流水线的流动性,并寻求单 处理器设计的优点是一项非常值得做的工程。这种设计方案为用于通用数值计算的可编程 GPU处理器阵列的产生铺平了道路。 2.1.4GPU:一个中间步骤 当GPU硬件设计朝着更多统一处理器的方向发展时,它们已经越来越像高性能并行 计算机。早在DirectX9的GPU上市时,一些研究人员已经注意到GPU的原始性能增长轨 迹,并开始探索使用GPU来解决密集计算型科学问题和工程问题。但DirectX9系列的GPU 在设计时仅仅是为了匹配图形API的特点。要访问计算资源,程序员只有把自己的问题强 制转化成本地图形操作,才可以通过调用OpenGL或DirectX API启动计算过程。例如, 要同时运行一个计算函数的多个实例,要把计算过程写成像素着色器的形式。输入数据的 集合必须先存储在纹理图像中,再以三角形图元的形式提交给GPU(根据需要会剪辑成矩 形)。经过光栅操作后的数据强制转化为像素集的形式输出。 事实上,GPU处理器阵列和帧缓冲存储器接口是为处理图形数据而设计的,事实证明 对通用数值应用程序限制条件太多。特别是,着色器程序的数据是以单个像素的形式输出 的,它们在存储器中的位置是事先指定的。因此,图形处理器阵列设计时的存储器读写能 力非常有限。通过图2-6可以看出早期的可编程着色处理器阵列访问存储器的能力有限, 着色器程序员要用纹理才能访问输入数据在随机存储器中的位置。更重要的是,着色器即 使已经计算好存储器的地址也没法执行写操作,这也称为对存储器的随机分散操作(scatter operation)。把结果写入存储器中的唯一途径是把结果输出成像素的颜色值,通过配置帧缓 冲操作阶段把结果写入(或者混合,根据需要)到二维的帧缓冲区中。 此外,在一次计算完成后要把结果传递给下一次计算时,得到这种结果的唯一途径是 把所有并行结果写入到一个像素帧缓冲区中,然后作为纹理映射输入,把帧缓冲区用于下 一个计算阶段的像素片元着色器。其中也没有用户自定义的数据类型,很多数据不得不用 一元、二元或四元向量数组来存储。因此,在这个时代把通用计算映射到GPU上是一件比 较棘手的事情然而,坚韧不拔的研究人员不遗余力地在这方面进行研究,实现了一些有 用的应用实例。这个领域被称作“GPGPU”,意思是在GPU上进行通用计算
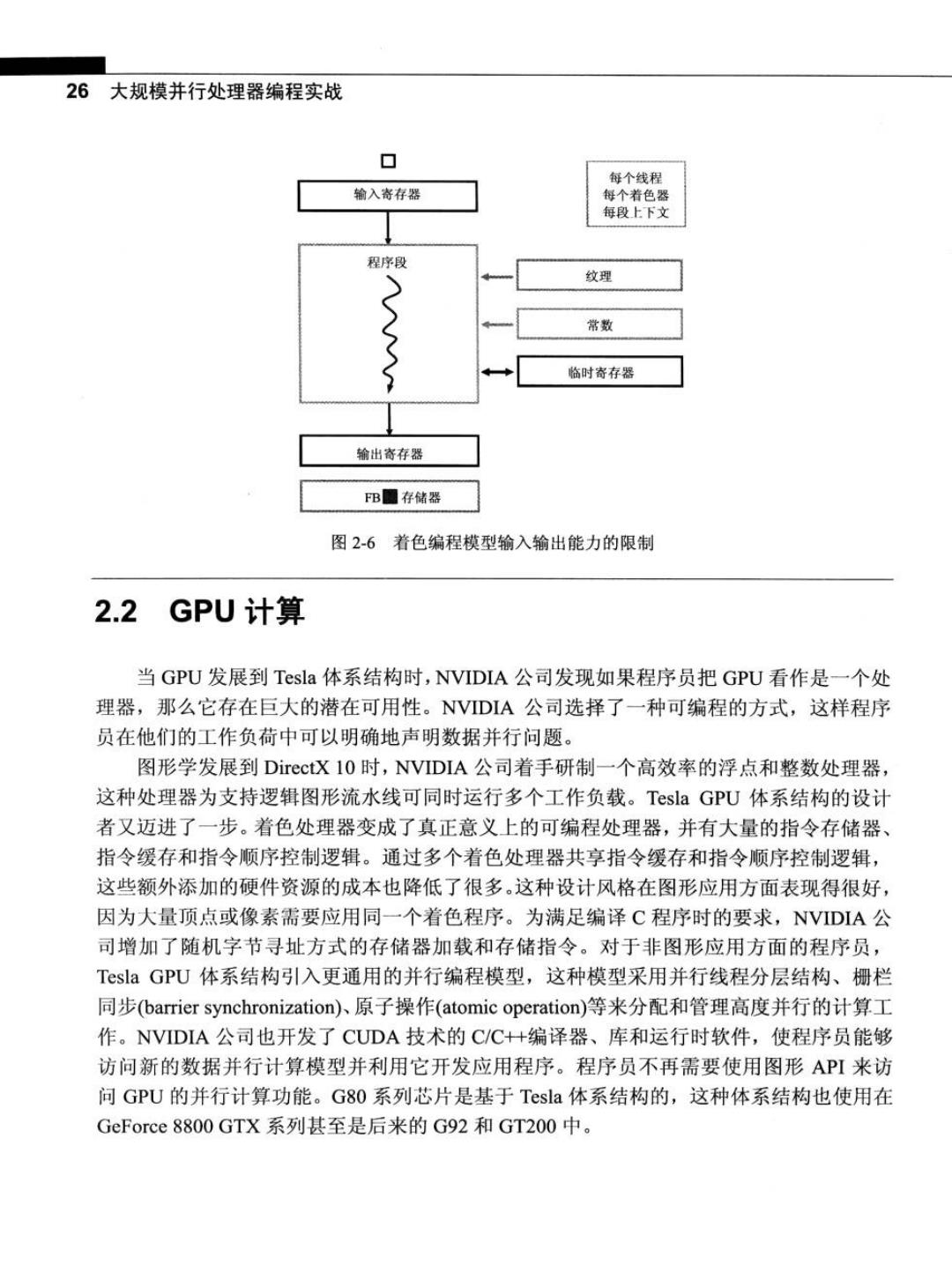
26大规模并行处理器编程实战 口 每个线程 输入寄存器 每个着色器 每段上下文 程序段 纹理 常数 S 临时寄存器 输出寄存器 FB圈存储器 图2-6着色编程模型输入输出能力的限制 2.2 GPU计算 当GPU发展到Tesla体系结构时,NVIDIA公司发现如果程序员把GPU看作是一个处 理器,那么它存在巨大的潜在可用性。NVIDIA公司选择了一种可编程的方式,这样程序 员在他们的工作负荷中可以明确地声明数据并行问题。 图形学发展到DirectX 10时,NVIDIA公司着手研制一个高效率的浮点和整数处理器, 这种处理器为支持逻辑图形流水线可同时运行多个工作负载。Tesla GPU体系结构的设计 者又迈进了一步。着色处理器变成了真正意义上的可编程处理器,并有大量的指令存储器、 指令缓存和指令顺序控制逻辑。通过多个着色处理器共享指令缓存和指令顺序控制逻辑, 这些额外添加的硬件资源的成本也降低了很多。这种设计风格在图形应用方面表现得很好, 因为大量顶点或像素需要应用同一个着色程序。为满足编译C程序时的要求,NVIDIA公 司增加了随机字节寻址方式的存储器加载和存储指令。对于非图形应用方面的程序员, Tesla GPU体系结构引入更通用的并行编程模型,这种模型采用并行线程分层结构、栅栏 同步(barrier synchronization)原子操作(atomic operation)等来分配和管理高度并行的计算工 作。NVIDIA公司也开发了CUDA技术的C/C++编译器、库和运行时软件,使程序员能够 访问新的数据并行计算模型并利用它开发应用程序。程序员不再需要使用图形API来访 问GPU的并行计算功能。G80系列芯片是基于Tesla体系结构的,这种体系结构也使用在 GeForce8800GTX系列甚至是后来的G92和GT200中