
CHAPTER GPU计算的发展历程 2 本章内容: ·图形流水线的发展 ·固定功能的图形流水线时代 ·可编程实时图形的发展 ·图形与计算结合的处理器 ·GPU:一个中间步骤 GPU计算 ·可扩展的GPU 。 发展近况 ● 未来发展趋势 概述 对于CUDA和OpenCL程序员,GPU是用C语言编写的、经过扩展的大规模并行数 值计算处理器。读者不需要理解图形学算法或图形学领域的术语,仍然能在处理器上进行 程序设计。但如果了解这些处理器的图形继承性,则更容易理解目前主要计算模式的优缺 点,特别是发展历程有助于理解现代可编程GPU的主要体系结构设计理念:大规模多线程、 与CPU比相对较小的缓存、以带宽为中心的存储器接口设计。了解GPU的发展历程也有 助于把握GPU作为计算设备未来发展的趋势

18大规模并行处理器编程实战 2.1 图形流水线的发展 3D图形流水线硬件始于20世纪80年代初昂贵的大型系统,然后到小型工作站,再发 展到20世纪90年代中后期的PC加速器。在此期间,在性能需求的驱动下图形子系统的 价格从$50000降到了$200,而性能也从每秒5000万像素提高到每秒10亿像素,从每秒 10万顶点(vertice)到每秒1000万顶点。虽然这些进步与半导体设备特征尺寸的不断缩小有 一定的关系,但同时也源于图形算法和硬件设计的改进,算法改进现代GPU决定了固有的 硬件性能。 驱使图形硬件性能的飞速提高的原因主要有高质量产品的市场需求,以及实时计算的 应用需求。例如,在电子游戏程序中,人们要求渲染越来越复杂的场景,甚至要在每秒60 帧的速度不断提高的游戏分辨率。在过去的30年里,图形体系结构在不断的发展演化,从 最初用一个简单的流水线来设计线框图,到后来为实现高度并行化而采用多个深度并行流 水线渲染3D场景的复杂交互意象。同时,许多相关的硬件功能也变得更加复杂,且支持 用户编程。 2.1.1固定功能的图形流水线时代 从20世纪80年代初到20世纪90年代末,图形硬件中性能最好的是固定功能流水线, 但它虽然可配置却不能真正实现可编程。在同一时期内,主要图形应用程序API库也开始 流行。API是一种标准化的软件层(即库函数的集合),它支持应用程序(如游戏)使用软件或 硬件的服务和功能。例如,游戏可以使用API来发送命令给图形处理单元,在显示器上绘 制某种对象。例如,微软就提供了一个具有多媒体功能的专用API一一DirectX,DirectX 中的组件Direct.3D提供了对图形处理器进行编程的接口函数。另一个主要的API是 OpenGL,它是由多个供应商支持的开放性标准API,主要用于专业的工作站应用软件。 DirectX的第7代产品采用的正是这种固定功能的图形流水线。 图2-1给出了NVIDIA公司早期生产的GeForce系列固定功能图形流水线的GPU的一 个示例。主机接口接收来自CPU的图形界面的命令和数据。这些命令通过调用API函数 来实现应用程序想要的功能。主机接口通常包括一个专门的DMA(Direct Memory Access, 直接内存访问)硬件,高效地把大量数据在主机系统内存和图形流水线之间来回传输。主机 接口在执行指令时还把状态和结果数据反馈回来
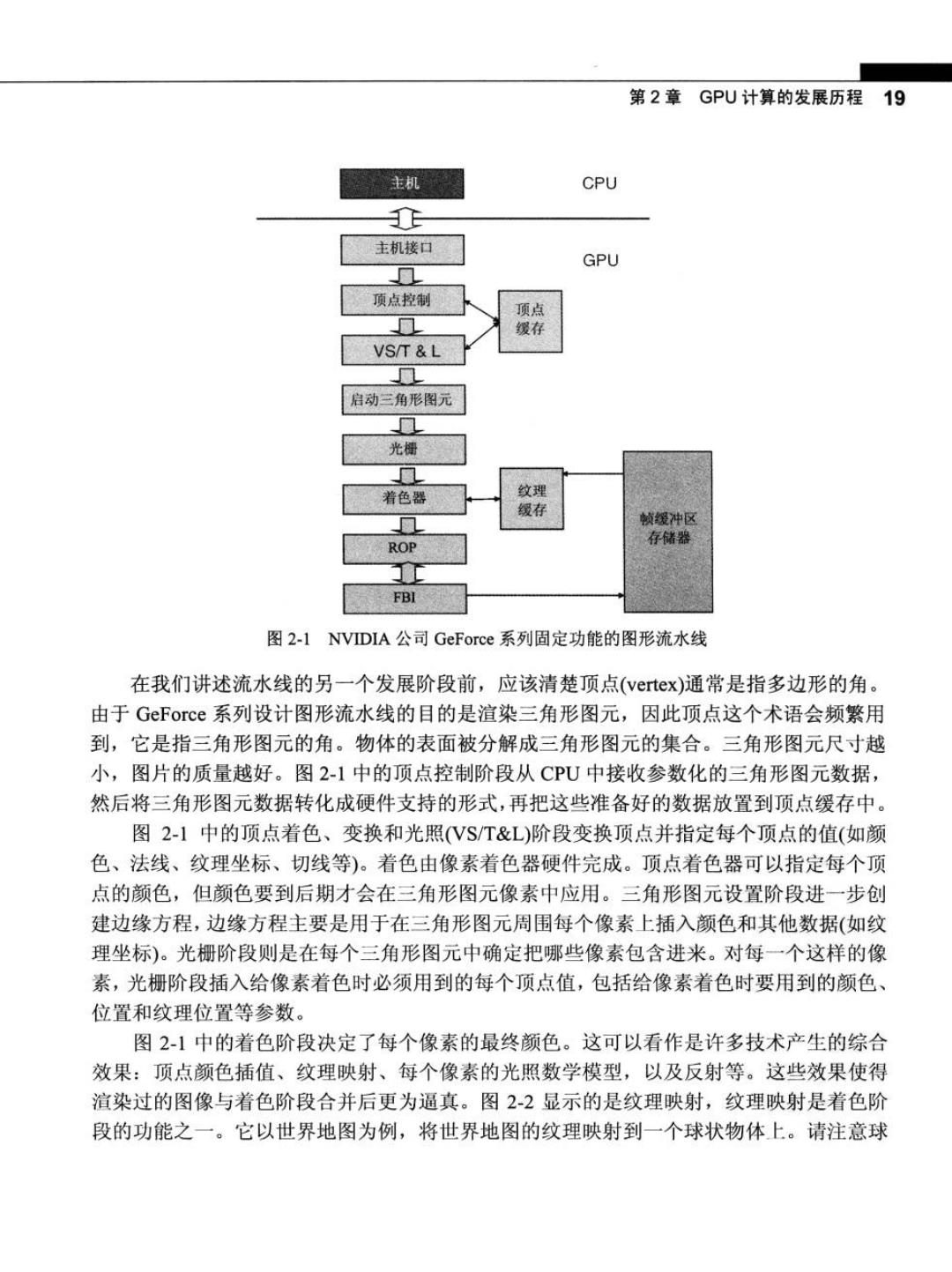
第2章GPU计算的发展历程19 主机 CPU JE 主机接口 GPU 0 顶点控制 顶点 ▣ 缓存 VS/T L 0 启动三角形图元 ▣ 光栅 0 着色器 纹理 缀存 见 帧缓冲区 存储器 ROP FBI 图2-1 NVIDIA公司GeForce系列固定功能的图形流水线 在我们讲述流水线的另一个发展阶段前,应该清楚顶点(vertex)通常是指多边形的角。 由于GeForce系列设计图形流水线的目的是渲染三角形图元,因此顶点这个术语会频繁用 到,它是指三角形图元的角。物体的表面被分解成三角形图元的集合。三角形图元尺寸越 小,图片的质量越好。图2-1中的顶点控制阶段从CPU中接收参数化的三角形图元数据, 然后将三角形图元数据转化成硬件支持的形式,再把这些准备好的数据放置到顶点缓存中。 图2-】中的顶点着色、变换和光照(VS/T&L)阶段变换顶点并指定每个顶点的值(如颜 色、法线、纹理坐标、切线等)。着色由像素着色器硬件完成。顶点着色器可以指定每个顶 点的颜色,但颜色要到后期才会在三角形图元像素中应用。三角形图元设置阶段进一步创 建边缘方程,边缘方程主要是用于在三角形图元周围每个像素上插入颜色和其他数据(如纹 理坐标)。光栅阶段则是在每个三角形图元中确定把哪些像素包含进来。对每一个这样的像 素,光栅阶段插入给像素着色时必须用到的每个顶点值,包括给像素着色时要用到的颜色、 位置和纹理位置等参数。 图2-1中的着色阶段决定了每个像素的最终颜色。这可以看作是许多技术产生的综合 效果:顶点颜色插值、纹理映射、每个像素的光照数学模型,以及反射等。这些效果使得 渲染过的图像与着色阶段合并后更为逼真。图2-2显示的是纹理映射,纹理映射是着色阶 段的功能之一。它以世界地图为例,将世界地图的纹理映射到一个球状物体上。请注意球

20大规模并行处理器编程实战 状物体表面用无数三角形图元的集合来描述。尽管着色阶段必须执行小部分坐标变换的计 算,目的是标识纹理点的精确坐标,以便将描述球状物体的三角形图元着色,但是图像所 覆盖像素的全部数目要求着色阶段在每帧中进行大量的坐标变换计算。 Vn 没有纹理的球体 纹理图像 纹理图像 有纹理的球体 图22纹理映射的示例:在一个球状物体上绘制一幅世界地图纹理图像 图2-2中的ROP(Raster OPeration,光栅操作)阶段对像素执行最后的光栅操作。它执 行颜色光栅操作时通过对重叠或者邻接物体颜色的混合达到透明与反走样的效果。这一阶 段还根据给定的视角确定可见物体并剔除那些被遮挡的像素。一个像素被遮挡是指在给定 的视角下被其他物体的像素阻挡。 图2-3显示的是消除锯齿的操作(ROP阶段的操作之一)。请注意3个黑色背景的相邻 三角形图元。假设在消除锯齿输出时,每个像素要么是其中一个物体的颜色要么是背景色。 由于分辨率有限,使得图像边缘看起来参差不齐,且物体的形状也变形了。出现这种现象 的原因是很多像素是不同物体或者是物体与背景混合而成的。将这些像素强制转换成一个 物体的颜色导致物体的边缘扭曲。消除锯齿操作是对所有物体的颜色和与像素重叠的部分 背景进行混合或者是线性组合,给每个像素赋予一种颜色。每个物体对像素点颜色的影响 由物体重叠像素的多少决定。 最后,图2-l中的FBI(Frame Buffer Interface,帧缓冲区接口)阶段主要管理存储器对

第2章GPU计算的发展历程21 帧缓冲区存储器显示的读写操作。对于高分辨率的显示器,访问帧缓冲区时对带宽的要 求非常高。目前有两种策略可以到达高要求的带宽。第一种是图形流水线通常使用专用 存储器提供比系统内存更高的带宽。第二种是FBI同时管理多个存储器通道,这些通道 与多个存储库连接。多通道和专用存储器结构的有机结合能给帧缓冲区提供比同时期系统 内存更高的带宽。这种高存储器带宽技术一直沿用至今,并己经成为现代GU设计中的主 要特点。 三角形几何图元 锯齿 消除锯齿 图2-3消除锯齿操作的例子 近20年来,硬件的不断更新换代和API的相应更新逐渐提高了图形流水线不同阶段 的水平。虽然图形流水线技术每个阶段都会引进额外的硬件资源和配置,开发人员也变得 越来越娴熟,且对新特点的要求比能理应提供的内置固定功能更多。显而易见,下一步就 是把图形流水线阶段中的某些部分转移到可编程处理器上去。 2.1.2 可编程实时图形流水线的发展 2001年,NVIDIA公司的GeForce3系列产品第一次真正实现了通用着色器可编程性。 它向应用程序开发人员提供了浮点顶点引擎(VST&L阶段)中的专用内部指令集。与之相 匹配的是微软发布的DirectX8和OpenGL的顶点着色器扩展。后来的GPU,发展到DirectX 9时,扩展了像素着色阶段的通用可编程性和浮点运算功能,并能从顶点着色阶段中获取 纹理。2002年,ATI推出Radeon900系列产品,它的主要特点是配备一个24位可编程的 浮点像素着色处理器,它可以用DirectX9和OpenGL编程。GeForce FX增加了32位的浮 点像素处理器。这些可编程的像素着色处理器只是向统一不同阶段的功能发展的一般趋势 的一部分,应用程序的程序员可以看到这种趋势。GeForce6800和7800系列使用分离的处 理器对顶点和像素进行处理。2005年初,XBox360引入了统一处理器GPU,允许顶点和