
6 大规模并行处理器编程实战 与电子工程师协会(Institute of Electrical and Electronics Engineers,IEEE)关于浮点运算的标 准。这个标准表明即使使用不同供应商开发的处理器,程序运行的最终结果也是可以预测 的。早期开发的GPU并不是很符合EEE的浮点运算标准,但自从引进G80以来,GPU 进入了新纪元,从而这种情况得到改变。第7章将讨论,目前GPU已经符合EEE提出的 浮点运算标准,且达到了可以和CPU相媲美的水准。因此,我们可以预计越来越多的数值 计算应用程序将移植到GPU上,并得到与CPU等价的结果。GPU的浮点运算单元上仍然 存在的一个问题是目前还只支持单精度的浮点运算。实际应用程序要求的双精度浮点运算 在GPU上还没法执行。然而,最近的GPU中已经能进行双精度的浮点运算,只不过运算 速度只有单精度浮点运算的一半,高端CPU内核也能达到这个水准。这使得GPU更加广 泛地应用于数值计算应用领域。 直到2006年,程序员使用这些图形芯片仍然很不方便,因为程序员如果想要使用它, 就必须会调用图形应用编程接口(Application Programming Interface,AP)函数来访问处理 器内核,这意味着要用OpenGL或Direct.3D技术对这些图形芯片进行编程。这种技术称为 GPGPU,这是基于GPU的通用编程(General-purpose Programming using a Graphics Processing Unit,GPGPU的缩写形式。即使是在高性能的编程环境下,使用API也极大地限制了底层 代码的开发速度。API的使用也极大地限制了实际上为图形芯片编写的应用程序的种类。 这是为什么只有少数人能够掌握这种技术,使用这些芯片来实现有限应用程序的性能:因 此,这些局限性导致该技术并没有得到广泛的应用。然而,这项技术激起人们在这一研究 领域的兴趣并取得了可喜的成绩。 2007年,NVIDIA发布了CUDA技术。因为NVIDIA公司实际上利用硅片面积来简化 并行程序设计,所以这一技术不仅推动了软件行业的发展,也推动了硬件行业的发展。在 专门为并行计算设计的G80系列和后继芯片中,CUDA程序不再借助于图形接口。与以前 不同的是,为满足广大开发人员便捷使用的需求,CUDA技术采用一种新的通用并行编程 接口。此外,因为所有其他软件层也重新进行了设计,所以程序员可以使用自己熟悉的C /C+编程工具。一些学生在做实验时试图使用基于OpenGL的编程接口,他们在实践中深 深地体会到通用并行编程接口的优势,因为不需要使用图形API就可以顺利地完成应用程 序的计算

第1章引 言7 1.2 现代GPU的体系结构 图1-3是一个基于CUDA技术的典型GPU体系结构。这种体系结构由一个高度线程 化的多核流处理器(Streaming Multiprocessor,SM)阵列组成。在图1-3中,两个SM形成一 个构建块,然而,在基于CUDA技术的GPU的每一代之间,每个构建块中SM的数量可 能不同。此外,图l-3中的每个SM又包含多个流处理器(Streaming Processor,SP),它们 之间共享控制逻辑和指令缓存。每个GPU都带4GB字节的图形双数据速率(Graphics Double Data Rate,GDDR)DRAM,在图l-3中称为全局存储器(global memory)。GPU中的 这些GDDR DRAM完全不同于CPU体系中安装在主板上的系统DRAM,它们主要是用于 图形处理的帧缓冲区存储器。在图形应用程序中,它们用来保存视频图像和用于3D渲染 的纹理信息:而对于计算,它们可以提供非常高的带宽和芯片外的存储器,尽管比典型系 统存储器的延迟要长。大规模并行应用程序通常通过高带宽来弥补时延。 采用CUDA体系结构的G80其存储器带宽可以达到86.4GB/s,并配备8GB/s的通信 带宽与CPU之间进行通信。CUDA应用程序从系统内存中传输数据的带宽和将数据上传 回系统内存中的带宽都可以达到4GB/s,从而使得总带宽可以达到8GB/S。通信带宽要远 低于存储器带宽,因此看起来似乎是瓶颈问题。但是,PCI Express的带宽可以与系统内存 中CPU前端总线的带宽相媲美,因此通信带宽实际上并不是一个瓶颈问题。将来在系统内 存中CPU总线带宽增长的同时,通信带宽也会随之增长。 大规模并行G80芯片有128个SP(16个SM,每个SM包括8个SP)。每个SP都有一 个MAD(Multiply--ADd)单元和一个附加的乘法单元.这128个SP运行时的总速度达到500 gigaflops。此外,特殊功能单元可以执行如平方根(SQuare RooT,.SQRT)之类的浮点函数以 及超越函数。在GT200中有240个SP,计算速度已经超过1 teraflops。因为SP采用大规 模线程方式,所以它一次可运行成千上万个线程。一个组织良好的应用程序在这种芯片上 一次可同时运行5000~12000个线程。多核CPU也支持多线程,但同时运行的线程数量取 决于CPU中内核的数量,如Intel的CPU可以同时运行两个或4个线程。G80芯片中的每 个SM都可以同时运行768个线程,因此整个芯片可以同时运行12000个线程。最近生产 的GT200的每个SM中可以同时运行1024个线程,因此整个芯片可以同时运行30000个 线程。因此,GPU硬件的快速发展极大地促进了并行水平的提高。当开发GPU并行计算 应用程序时,这种并行水平显得尤为重要
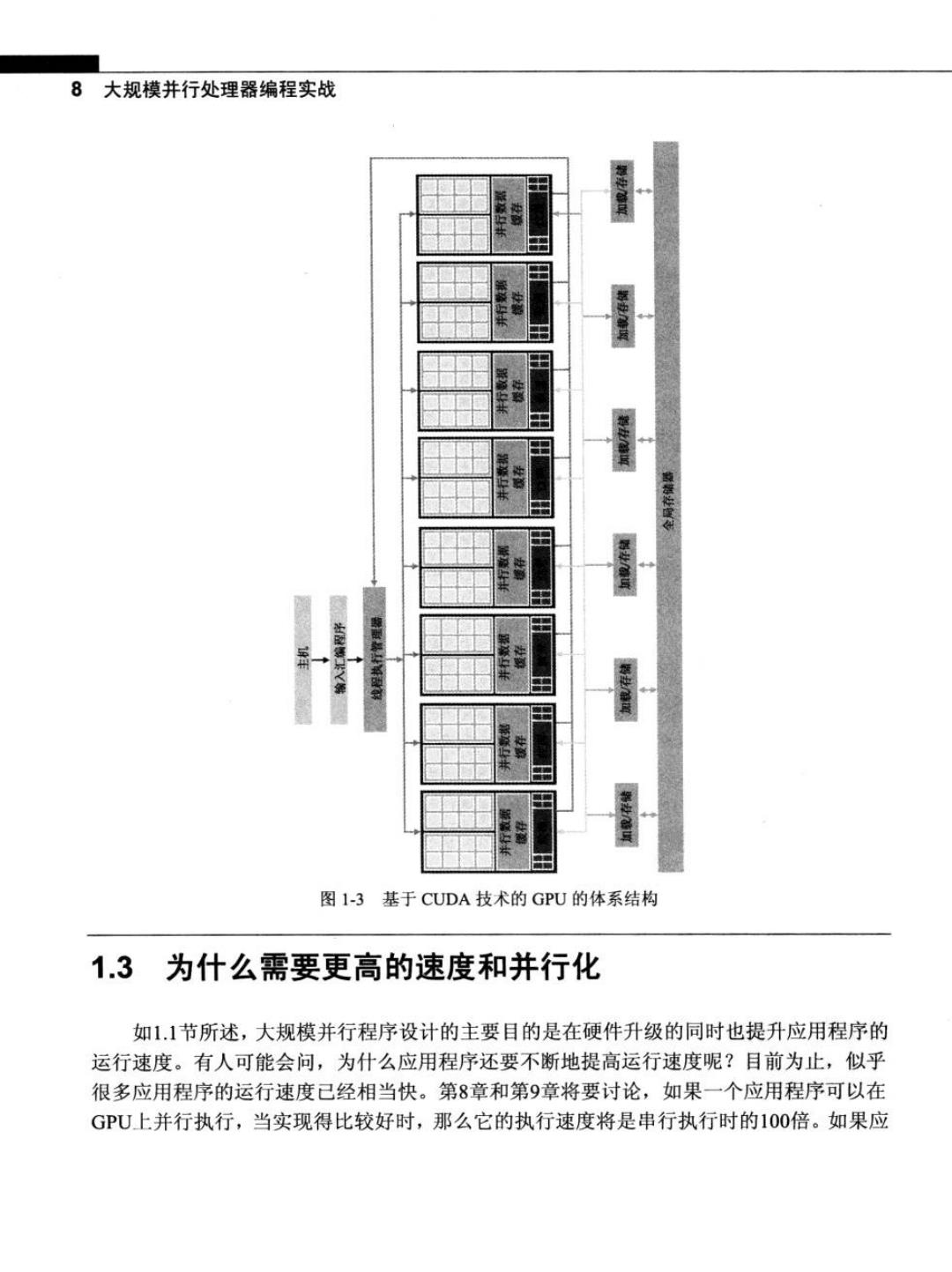
8大规模并行处理器编程实战 出 图1-3基于CUDA技术的GPU的体系结构 1.3为什么需要更高的速度和并行化 如1.1节所述,大规模并行程序设计的主要目的是在硬件升级的同时也提升应用程序的 运行速度。有人可能会问,为什么应用程序还要不断地提高运行速度呢?目前为止,似乎 很多应用程序的运行速度已经相当快。第8章和第9章将要讨论,如果一个应用程序可以在 GPU上并行执行,当实现得比较好时,那么它的执行速度将是串行执行时的100倍。如果应

第1章引言9 用程序包括数据并行性,则它通常很容易在几个小时之内以10倍的速度完成大量的工作量。 有关这方面的知识,请读者关注后续章节! 目前,尽管很多计算应用能满足要求,但将来具有广泛前景的还是超级计算应用 (supercomputing application),或者称为超级应用(superapplication)。例如,生物学领域的研 究工作已经达到了分子水平。显微镜在分子生物学领域里可以说是最重要的仪器,它在过 去通常依赖于光学仪器或电子仪器。虽然我们使用这些光学仪器或者电子仪器可以在分子 水平研究领域中开展一定的工作,但毕竟还是受限制的。要想突破这种限制,我们应该将 生物学和计算模型有机地结合起来,用计算机模拟传统仪器下观察到的分子活动与边界条 件。从计算机的模拟中,我们可以测量更为详细的数据,检验更多的假设,而传统仪器很 难完成这些工作。如果提高计算速度,这种模拟的优越性会变得更加明显,甚至可以在可 接受的响应时间内模拟生态系统的规模和生物体反应时间的长短。这些改进将在科学和医 学领域中产生巨大的影响。 至于在诸如视频和音频编码及操作等方面的应用,最明显的是目前的数字高清晰度电 视(Digital High-Definition Television,HDTV)与传统的美国国家电视系统委员会National Television System Committee,NTSC)电视进行比较。一旦我们体验了数字高清晰度电视带 来的唯美画面,再观看传统的电视就会觉得很难接受。但是,数字高清晰度电视的处理过 程很复杂,且是一个非常并行的过程,也是三维成像和可视化的过程。今后,新的功能(如 视图合成和低分辨率视频的高清晰度显示等)融入电视产业时对计算能力的要求会更高。 除此之外,高速计算也会改善用户界面,使其变得更友好。如苹果公司生产的Phoe 手机,其界面非常人性化。虽然Phone手机只有一个很小的用户窗口,但与其他手机相比, 其人性化的触摸屏设计更容易吸引用户。毫无疑问,这些设备今后的版本将会采用包括更 高清晰度、三维视角、语音和基于计算机视觉的界面等技术,而这些新技术的应用对计算 速度的要求会更高。 高速计算在消费电子游戏行业的应用也很广泛。不妨想象一下,传统的赛车游戏采用 一组简单的预设场景。因此,即使赛车遇到了障碍物也不会停下来,而只有游戏分数会变 化。游戏者赛车的车轮不会弯曲也不会损坏,而且不影响驾驶,不管是车轮碰撞,还是甚 至少了一个车轮。随着计算速度的不断提升,赛车游戏可以基于动态模拟,而不再是基于 预设场景。今后,我们会看到更多的这种逼真效果一交通事故会损坏车轮,游戏者的在 线驾驶体验也会变得越来越真实。众所周知,现实建模与物理效应的仿真都需要大量的计 算能力。 上文提到的所有这些应用无非是对现实世界不同方式、不同层次的模拟,而这些模拟 过程都会处理大量数据,很多计算工作都可以在数据的不同部分采用并行方式,尽管在某 些点上需要进行数据融合。日常从事这方面应用的开发人员早已掌握这些技术。因此,虽

10大规模并行处理器编程实战 然存在不同粒度(granularity)的并行性问题,但编程模型不应该阻碍并行实现技术,而且应 该适当地管理数据传递。CUDA技术包含了这种编程模型,硬件的支持也方便于并行实现。 我们的目标是教会应用程序开发人员管理并行执行和传递数据的基本技术。 并行化这些超级应用到底能达到多少倍的加速呢?这取决于应用程序可并行化的部 分。,一方面,如果花在可并行部分的时间占整个应用程序执行时间的30%,那么将并行部 分加速100倍,总的执行时间也只能减少29.7%。整个应用程序的加速只有1.4倍。事实 上,在并行部分中无限地加速也只能减少比30%更少的执行时间,总加速也不会超过1.43 倍。另一方面,如果并行部分的执行时间占整个应用程序执行时间的99%,则将并行部分 加速100倍,就可以将总执行时间降低到原来的1.99%,这使得整个应用程序的加速达到 了50倍。因此,重要的是将应用程序的绝大部分都在大规模并行处理器上并行执行,可以 更为有效地提高执行速度。 研究人员在一些应用程序中己经取得了加速超过100倍的良好成绩,但这只是在增强 的算法得到了大量优化和调整后,从而使应用程序超过99.9%的执行时间都花在并行执行 部分上。一般来说,应用程序直接并行化可能会导致存储器(DRAM)带宽达到饱和,使得 加速只能达到10倍。解决途径在于如何突破存储器带宽的限制,这需要进行某种转换以便 用专门的GPU芯片上存储器显著减少访问DRAM的次数。然而,如果要想突破这些限制, 则还需要对代码进行进一步的优化,如限制片上存储器的容量。总之,本书的一个重要目 标是帮助读者深入理解这些优化过程并熟练掌握它们。 请记住加速水平是否超过CPU执行能力也能反映CPU是否适合该应用程序。在某些 应用程序中,CPU执行得很好,从而导致用GPU很难提升性能。大多数应用程序的某些 部分利用CPU来执行效果会更好。因此,读者应该给CPU一个公平的执行机会,并确保 代码以如下方式编写,即GPU作为CPU执行时的补充。因此,读者要恰当地利用CPU/GPU 异构系统的并行计算能力。这些都是CUDA编程模型需要解决的问题,本书后面会进一步 解释。 图1-4说明了一个典型应用程序的关键部分。这个应用程序的很大一部分代码都是串 行执行的,串行部分好比桃子的桃核,试图将并行计算技术应用到这些部分上就如同敲开 桃核一样困难一感觉上也很不好。这些部分很难并行化。而CPU在这些部分中执行性能 更好。好的方面是,尽管这些部分有大段代码,但它们的执行时间在超级应用的执行时间 中所占的比例很小。 接下来讨论桃肉部分。这些部分很容易并行化,与早期的图形应用程序类似。例如, 目前大部分的医学成像应用程序仍然运行在微处理器集群系统和专用硬件相结合的平台 上。GPU在成本和规模方面都占优势,可以显著提高这些应用程序的质量。如图1-4所示, 早期GPGPU只占小部分果肉,这类似于未来10年内小部分最热门的应用。我们会看到