
CHAPTER 引 言 1 本章内容: 。GPU与并行计算机 ● 现代GPU的体系结构 。为什么需要更高的速度和并行化 ·并行编程语言与模型 ·综合目标 ·本书的组织结构 概述 近20年来,基于单个中央处理单元(Central Processing Unit,CPU)的微处理器,如Intel 的奔腾(Pentium)系列和AMD的皓龙(Opteron)系列,很好地推动了计算机应用程序的性能 提升和成本降低。正是这些微处理器,使得桌面计算机的浮点运算可以达到每秒十亿次 (Giga FLoating-point OPerations per Second,GFLOPS),而集群服务器甚至可以达到几百 GFLOPS。一方面,性能的飞速提升使应用软件行业提供更多功能强大的、用户界面友好 的、可用性更高的软件成为可能。另一方面,用户一旦适应了这些改进,对性能的需求也 会不断地提升。这在计算机行业形成了一个很好的良性循环。 在这种用户需求的驱动下,很多软件开发人员在底层靠硬件性能的提升来提高应用程 序的运行速度;处理器每更新一代,软件的运行速度也会相应地变得更快。然而,自2003 年以来,由于能耗和散热问题限制了时钟频率的提高和单CPU在每个时钟周期中的执行能 力,因此光靠硬件性能的提升来提高应用程序的运行速度已经远远不够。实际上,所有微

2大规模并行处理器编程实战 处理器供应商已经转变了处理器的处理模型,即在每个芯片中采用多个处理单元(称为处理 器内核,Processor Core)提升处理能力,这种转变在软件开发人员社区中产生了巨大的影响 [Sutter,20051. 从传统意义上来讲,绝大部分软件应用程序都是用串行方式编写的,冯·诺依曼(o Neumann)早在1945年的开创性报告中已经描述过这一观点。这些串行程序的顺序执行过 程符合人们的顺序思维习惯,容易被人们理解。从计算机发展史上看,每产生一代新的微 处理器,计算机用户习惯性地期待程序的运行变得更加快速,但用户的这种期待从现在起 变得很难实现。一个串行程序只能在其中一个微处理器内核中运行,目前的运行速度已经 到达一个瓶颈阶段,很难再有所突破。运行速度的限制使得应用程序开发人员很难随着引 入新一代微处理器而在其软件中引进新的特性与功能,从而阻碍了整个计算机行业的发展 进程。 而每一代微处理器产生的同时也会对应用软件的性能提出更高的要求,于是并行程序 应运而生,它采用多线程协作的执行方式使程序运行更加快速。这种新的设计方式(并行程 序设计)的发展极大地推动了产业的进步,甚至称为“并行革命(concurrency revolution)” [Sutter,2005]。现在运用并行程序设计已经不足为奇,并行程序在高性能计算领域已经发 展了近十年。但这些并行程序只能在昂贵的大型计算机上运行,而只有少数高端的应用程 序值得用这么昂贵的计算机,因此也只有少数开发人员能运用并行程序设计。既然新的微 处理器都是并行计算机,并行程序就应该随之得到广泛的应用,从而开发出更多的并行应 用程序。这需要大量的软件开发人员掌握并行程序设计,这也正是本书的出发点。 1.1 GPU与并行计算机 自2003年以来,半导体行业在设计微处理器时形成了两个主要方向[Hwu,2008]。多 核(multicore)方向试图把串行程序移植在多核上,运行时仍然能保持串行程序的执行速度。 多核时代从双核处理器开始,内核的数量大致随半导体生产工艺的改进而翻倍。目前多核 处理器最好的例子就是Intel公司生产的酷睿i7系列微处理器,它的处理器有4个内核, 每个内核都是独立的、多指令流出的微处理器,每个内核能执行x86指令集中的所有指令: 每个处理器由两个硬件线程来支持超线程,这种设计使得串行程序的执行速度得以最大化。 相比之下,众核(many-core)方向则更侧重于执行并行应用程序时的吞吐量。众核由大
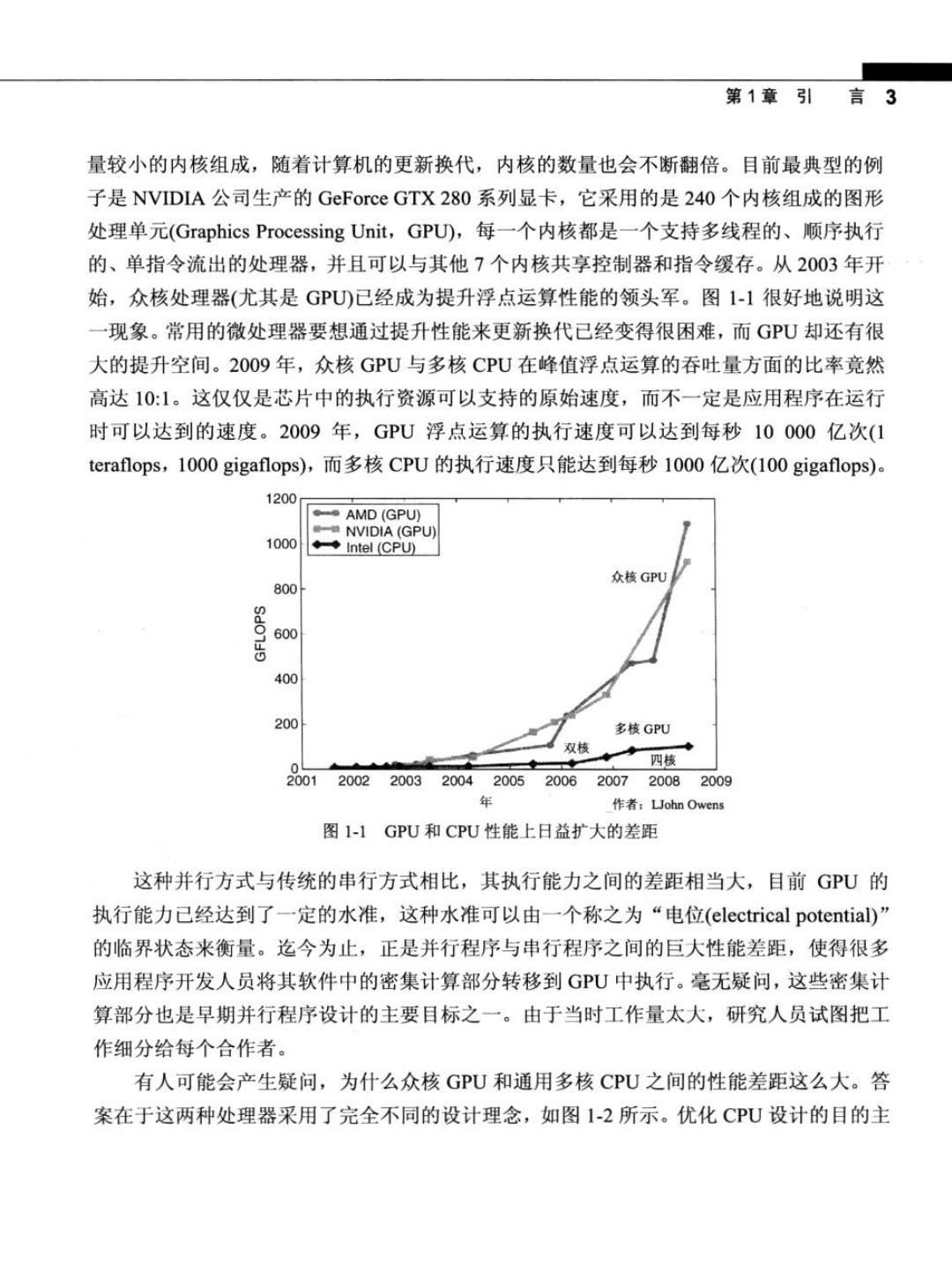
第1章引言3 量较小的内核组成,随着计算机的更新换代,内核的数量也会不断翻倍。目前最典型的例 子是NVIDIA公司生产的GeForce GTX280系列显卡,它采用的是240个内核组成的图形 处理单元(Graphics Processing Unit,GPU,每一个内核都是一个支持多线程的、顺序执行 的、单指令流出的处理器,并且可以与其他7个内核共享控制器和指令缓存。从2003年开 始,众核处理器(尤其是GPU)已经成为提升浮点运算性能的领头军。图1-1很好地说明这 一现象。常用的微处理器要想通过提升性能来更新换代已经变得很困难,而GPU却还有很 大的提升空间。20O9年,众核GPU与多核CPU在峰值浮点运算的吞吐量方面的比率竟然 高达10:1。这仅仅是芯片中的执行资源可以支持的原始速度,而不一定是应用程序在运行 时可以达到的速度。2009年,GPU浮点运算的执行速度可以达到每秒10000亿次(1 teraflops,1000 gigaflops),而多核CPU的执行速度只能达到每秒1000亿次(100 gigaflops)。 1200 AMD(GPU) NVIDIA(GPU) 1000 ◆◆Intel(CPU) 众核GPU 800 600 400 200 多核GPU 双核 0 四核 001 2002 2003 2004200520062007 20082009 作者:John Owens 图1-1GPU和CPU性能上日益扩大的差距 这种并行方式与传统的串行方式相比,其执行能力之间的差距相当大,目前GPU的 执行能力已经达到了一定的水准,这种水准可以由一个称之为“电位(electrical potential)” 的临界状态来衡量。迄今为止,正是并行程序与串行程序之间的巨大性能差距,使得很多 应用程序开发人员将其软件中的密集计算部分转移到GPU中执行。毫无疑问,这些密集计 算部分也是早期并行程序设计的主要目标之一。由于当时工作量太大,研究人员试图把工 作细分给每个合作者。 有人可能会产生疑问,为什么众核GPU和通用多核CPU之间的性能差距这么大。答 案在于这两种处理器采用了完全不同的设计理念,如图1-2所示。优化CPU设计的目的主

4大规模并行处理器编程实战 要是为了提高串行代码的性能,它采用复杂的控制逻辑,用指令来控制单线程可执行程序 的并行执行,即便这些程序不按顺序执行,至少也是可串行执行的。更重要的是,CPU采 用大型缓存,一方面可以减少访问复杂应用程序的指令和数据时产生的延时,另一方面还 能够节约带宽。无论是缓存还是控制逻辑,都不利于提升峰值计算速度。2009年,多核微 处理器一般采用4个大型处理器内核,这是为了提升串行代码的性能,达到更新换代的 目的。 除了上述问题外,内存带宽是另一个重要的问题。目前,GPU的芯片带宽是CPU芯 片带宽的10倍左右。2006年末,GeForce的8800GTX显卡(或者称为G80)在从动态随机 存取存储器(DRAM)中读写数据的速度达到了85GB/s。考虑到帧缓冲区的要求和松弛的内 存模型这两个方面一很多系统软件、应用程序和/O设备访问内存的方式一通用处理 器要同时满足早期操作系统、应用程序和/O设备的需求,从而很难在带宽方面有所突破。 相反,由于GPU采用简单的存储器模型和较少的传统限制,设计人员很容易实现更高的带 宽。最近NVIDIA推出的GT200系列芯片的显存带宽达到了150GB/s。在未来3年内,因 为微处理器系统的内存带宽都不会超过50GB/s,所以CPU在内存带宽方面仍然处于劣势 地位。 ALU ALU 控制器 ALU ALU DRAM 图1-2CPU和GPU不同的设计理念 飞速发展的视频游戏产业极大地推动了GPU的设计理念的发展,因为迫于巨大的经 济压力,要想使游戏实现更为逼真的图形效果,就要能够对每个视频帧执行大量浮点计算。 这种需求促使GU的供应商寻找各种方法来提高性能和降低成本,生产专门用于浮点计算 的产品。到目前为止,GPU普遍都采用多线程来提升运算速度与吞吐量。硬件充分利用因 为等待访问内存而产生较长延时的大量线程,从而减少了控制逻辑中需要执行的线程,极 大地简化了控制逻辑。小型缓存则可以满足应用程序中多线程对带宽的要求,访问相同内

第1章引 言5 存数据的多个线程没有必要全部访问DRAM存储器,而是从小型缓存中直接读取。因此, GPU可以更多地专注于提升浮点计算能力。 GPU负责大规模的密集型数据并行计算,而CPU则负责执行不适合数据并行的计算。 因此,需要综合考虑GPU和CPU的优缺点,使大多数应用程序能同时使用GPU和CPU, 既能用CPU执行应用程序中的需要串行执行的部分,又能用GPU进行高密集并行计算。 2007年,NVIDIA推出CUDA(Compute Unified Device Architecture,统一计算设备架构)这 一编程模型,是想在应用程序中充分利用CPU和GPU各自的优点。 另一个要点是,应用程序开发人员在选择何种处理器来运行他们的应用软件时,性能 不是唯一的决定因素。许多其他因素甚至更为重要。首先,选择的处理器必须在市场上有 很大的占有额,这是选择安装处理器的首要条件。原因很简单,软件开发的目的是满足众 多客户的需求,开发成本需要由客户支付。用市场上少见的处理器开发的应用程序很难得 到客户的认可。这也正是客户为什么不选择传统的并行计算系统,而选择通用的微处理器 系统。只有极少数由政府部门和大公司资助的在早期并行计算系统上开发的应用程序获得 成功。这种情况随着众核CPU的出现有所改变。由于GPU已经在PC市场上普及,数以 亿计的GPU已售出,几乎所有的PC上都有GPU。到目前为止,G80处理器以及后继产品 已经成功售出超过200万。这还是第一次因为市场上有如此多的并行产品而使得大规模并 行计算变得可行。存在这样庞大的市场对于应用程序开发人员充满了巨大的经济吸引力。 其他重要的决定因素还包括很容易获得GPU,并且GPU的实用性很强。到2006年为 止,并行软件应用程序通常运行在数据中心服务器或者部门的集群服务器上,但这种特殊 的执行环境往往限制了并行应用程序的使用。例如,在医学影像系统中,所发表的论文是 基于64个结点的集群服务器,而基于磁共振成像(MRI)机器的临床应用都依托于PC和特 殊硬件加速器结合的平台。原因很简单,一些大公司,如通用电气(GE)和西门子(Siemens), 没有把磁共振成像技术和集群服务器有机地结合起来应用于临床中,而这在学术领域内的 应用却相当广泛。事实上,国家卫生研究所National Institutes of Health,NHD曾一度拒绝 资助并行编程项目在医学中的应用,他们觉得并行软件的影响是有限的,因为大规模的集 群服务器在临床中根本难以成功运行。通用电气公司由于在这方面有了技术的突破,现在 己经申请到NH的研究基金,主要研究GPU在MRI方面的应用。 在选择处理器时要考虑的另一个重要因素是执行高密度计算应用程序时要符合电气 L.要获得关于GPU计算发展和CUDA创建方面的背景知识,请参阅第2章