信息检索与数据挖掘 2019/4/28 19 全局浏览的例子:京东 0 D.森 多快好省 超陆战队 搜索 里我的物车 金融年团机械键盘吃货节荷减领券品质联盟童书节6晚息毕业基金 全部向品分类 服装城 美妆馆 美食 全球购 闪购 团购 夺宝岛 金融 智能 潮货达人必进! 家用电器 京东快报 更多) 手机数码、京东通信 电脑、办公 特南戴尔控一体西病千减百 家居、家具家装厨具 517 [公告1京东启动空净节渠道优势明显 男装女装内衣珠宝 [特图DK家庭医生买一赠 个护化妆 鞋靴、箱包、钟表奢侈品 手抢动绣 电信日 245 [公告吉SEPHORA丝芙兰独家入驻克东 [特图京东红酒节千万元礼券狂送 运动户外 全场白条免息 生活服务 汽车、汽车用品 会员免费抽奖 iPhone 6 母婴、玩具乐器 4799抢肾6 回 X @ ⑧ 话典 机票 电是票 游置 食品饮科类、生鲜 营养保健 ¥4799 彩 國 卧 0 图书、音像数字商品 彩票 团购 酒店 水电煤 彩票旅行、充值、票务 g 自 马 理财众等白条保验 ①23456 众等 保险 财 白条 手机大抢劫 京东吃货节 初夏新风潮 大牌9.9元起 4799抢肾6 99元5斤 自营大牌1折起 好货天天抢 全场白条免息 授桃首发 低价起防 品牌团购精选 今日推荐 闪购⊙ 团购心
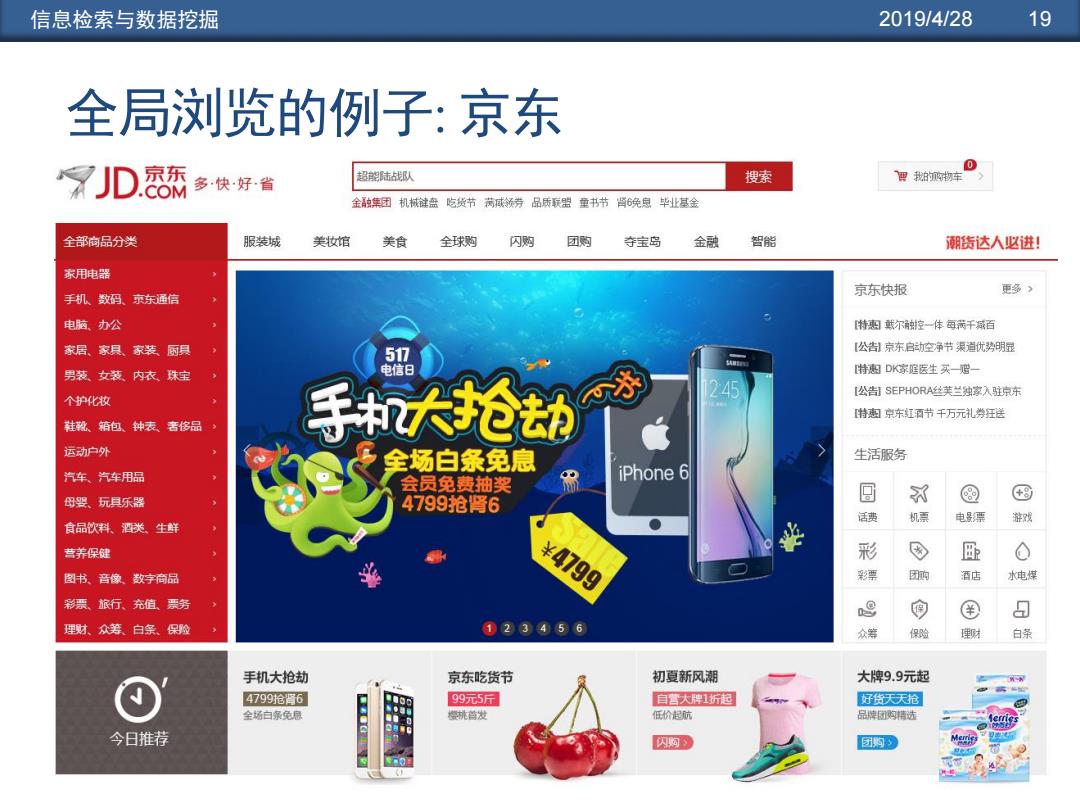
信息检索与数据挖掘 2019/4/28 19 全局浏览的例子: 京东

信息检索与数据挖掘 2019/4/28 20 全局浏览的例子:Google News 每G0ogle新闻 X ← → news.google.com 四☆≡☑0 Google 进 新闻 中回China)版 精商版一 个性化 典点新间 焦点新闻 个性化设晋Google新闻 Anhui.Hefei 新华社披露雄安新区决策纪实:将制定全新住房政策 为您推荐 为您推荐 一制网·3小前G 国际港台 4月初的白洋淀,绿柳蜜婆,碧波荡漾,放眼水鸟嬉戏,听闻娃声一片,漾带崇拥分淀泊,调干依斗里京华一河 国际港台 北安新县白洋淀凉亭上的这副橙联,在这个春天里,与位于东北方向100多公里的首都北京,有了… 内地 内地 习近平总书记对中央双治局的六个新要求人民网 财经 财经 娱乐 娱乐 科技 科技 体肯 体育 中方回应是香会考虑对朝鲜进行石油制裁 满动加任编新试主型 + 浪网,3小时前 例加:天之学、新天格兰发四者,被信 总理部署这项改革:让你在家门口就看上“好医生” 调整新闻媒体的引用顿率 第,48分种明 整京新可兴体的钥用 万钢:打造中国创新驱动助力工程2.0版 搜到 新液网-小时回 基层抓落实必须善用“绣花”功夫 凤厚网 ww.gsthe0y.n-6小时前 中国新河网 韩正:以更品扬精神状态抓推进抓落实 经济参考报 人民网-小时雨 保行 设置主置帮助 为您推荐》 沃尔玛合肥当年8家如今剩1独苗员工:停业来得很突然 Anhui,Hefei的天气 新该网-22小时前 今天 周五 沃尔玛合把再关两店当年8家如今剩一独苗每经记者查道坤每经编辑文多全球零售巨头沃尔玛再次对安微合肥区域门店 周六 周日 进行调整。就在4月11日,位于合把的沃尔玛 0 2 易 对合配市兴网?是引否 25°12 26°14 2818 23°16
信息检索与数据挖掘 2019/4/28 20 全局浏览的例子: Google News

信息检索与数据挖掘 2019/4/28 21 文档聚类用于提高召回率 ·可以实现将文档集中的文档进行聚类 ·当文档d和查询匹配时,也返回包含d的簇所包含的 其它文档 ·我们希望通过上述做法,在输入查询“car时,也 能够返回包含“automobile'的文档 ·由于聚类算法会把包含“car的文档和包含 “automobile?”的文档聚在一起 ·两种文档都包含诸如“parts'”、“dealer'”、 “mercedes'和“road trip”之类的词语
信息检索与数据挖掘 2019/4/28 21 文档聚类用于提高召回率 • 可以实现将文档集中的文档进行聚类 • 当文档d和查询匹配时,也返回包含d的簇所包含的 其它文档 • 我们希望通过上述做法,在输入查询“car“时,也 能够返回包含 “automobile”的文档 • 由于聚类算法会把包含 “car”的文档和包含 “automobile”的文档聚在一起 • 两种文档都包含诸如 “parts”、 “dealer”、 “mercedes”和“road trip”之类的词语

信息检索与数据挖掘 201360286.222 聚类要解决的基本问题 Representation for clustering Document representation Vector space?Normalization? Centroids aren't length normalized Need a notion of similarity/distance How many clusters? ·Fixed a priori? Completely data driven? ·Avoid“trivial''clusters-too large or small If a cluster's too large,then for navigation purposes you've wasted an extra user click without whittling down the set of documents much
信息检索与数据挖掘 2019/4/28 22 聚类要解决的基本问题 • Representation for clustering • Document representation • Vector space? Normalization? • Centroids aren’t length normalized • Need a notion of similarity/distance • How many clusters? • Fixed a priori? • Completely data driven? • Avoid “trivial” clusters - too large or small • If a cluster's too large, then for navigation purposes you've wasted an extra user click without whittling down the set of documents much. Sec. 16.2

信息检索与数据挖掘 2019/4/28 23 聚类的形式化描述 ·硬扁平聚类的目标可以定义如下: ·给定 ·()一系列文档D=d,,dw, ·()期望的簇数目K, ·(ii用于评估聚类质量的目标函数(objective function), 。计算一个分配映射y:D→1,,K好,该分配下的目标函 数值极小化或者极大化。大部分情况下,我们要求是一 个满射,也就是说,K个簇中的每一个都不为空。 ·目标函数通常基于文档的相似度或者距离来定义。 下面我们将看到,K-均值算法的目标是最小化文档 和其所在簇的质心的平均距离
信息检索与数据挖掘 2019/4/28 23 聚类的形式化描述 • 硬扁平聚类的目标可以定义如下: • 给定 • (i) 一系列文档D = {d1 , …, dN }, • (ii) 期望的簇数目K , • (iii)用于评估聚类质量的目标函数(objective function), • 计算一个分配映射γ : D → {1, …, K},该分配下的目标函 数值极小化或者极大化。大部分情况下,我们要求γ 是一 个满射,也就是说,K 个簇中的每一个都不为空。 • 目标函数通常基于文档的相似度或者距离来定义。 下面我们将看到,K-均值算法的目标是最小化文档 和其所在簇的质心的平均距离