
信息检索与数据挖掘 2019/3/31 17 词袋模型与事件独立性 。词袋模型:不考虑词在文档中出现的顺序。 “John is quicker than Mary”和“Mary is quicker than John”的表示结果一样 词袋模型是向量空间模型的假设 ·两事件独立:事件A、B,若P(AB)=P(A)P(B),则 称A、B独立 ·三事件独立:事件ABC,若满足P(AB)=P(A)P(B), P(AC)=P(A)P(C),P(BC)=P(B)P(C), P(ABC)=P(A)P(B)P(C),则称A、B、C独立 ·多事件独立:两两独立、三三独立、四四独立
信息检索与数据挖掘 2019/3/31 17 词袋模型与事件独立性 • 词袋模型:不考虑词在文档中出现的顺序。 “John is quicker than Mary ” 和“Mary is quicker than John ”的表示结果一样 • 两事件独立:事件A、B,若P(AB)=P(A)P(B),则 称A 、B独立 • 三事件独立:事件A B C,若满足P(AB)=P(A)P(B), P(AC)=P(A)P(C),P(BC)=P(B)P(C), P(ABC)=P(A)P(B)P(C),则称A、B、C独立 • 多事件独立:两两独立、三三独立、四四独立…. 词袋模型是向量空间模型的假设
信息检索与数据挖掘 2019/3/31 18 键盘布局与条件概率 字母 A B C D E F G H I 频率 0.063 0.0105 0.023 0.035 0.105 0.0221 0.011 0.047 0.054 字母 J K L M N 0 P Q R 频率 0.001 0.003 0.029 0.021 0.059 0.0644 0.0175 0.001 0.053 字母 S T U W X Y Z 空格 频率 0.052 0.071 0.0215 0.008 0.012 0.002 0.012 0.001 0.2 功能键区 状态指示区 Esc 2 F3 F4 F10 11 Num Caps Sorol Back 9 3 Gt 主键盘区 控制键区 数字键区
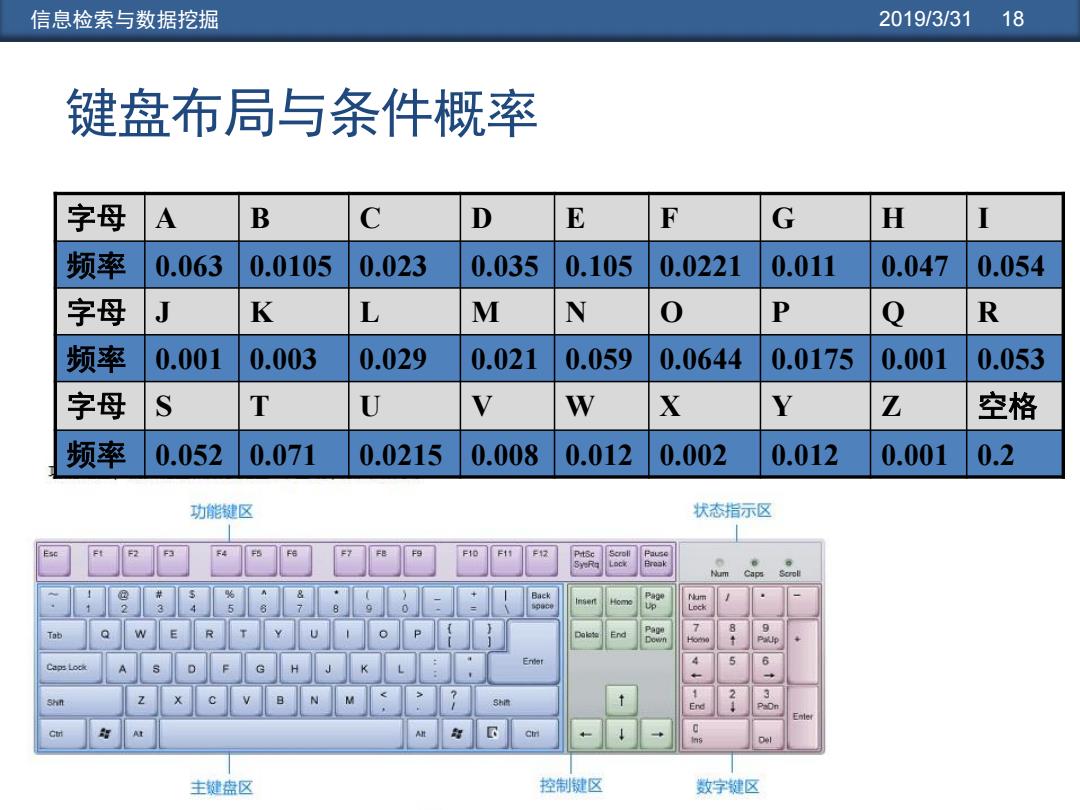
信息检索与数据挖掘 2019/3/31 18 键盘布局与条件概率 字母 A B C D E F G H I 频率 0.063 0.0105 0.023 0.035 0.105 0.0221 0.011 0.047 0.054 字母 J K L M N O P Q R 频率 0.001 0.003 0.029 0.021 0.059 0.0644 0.0175 0.001 0.053 字母 S T U V W X Y Z 空格 频率 0.052 0.071 0.0215 0.008 0.012 0.002 0.012 0.001 0.2

信息检索与数据挖掘 2019/3/3119 乘法公式、全概率公式和贝叶斯公式 乘法公式: ·P(AB)=P(A)P(BA) .P(A A2...An)=P(AP(A2A)..P(AA1...An-1) ·全概率公式:A1A2.A是整个样本空间的一个划分 P(B)=∑P(4)P(B1A) ·贝叶斯公式:AA2An是整个样本空间的一个划分 P(4,B)= P(4A)P(B\A),U=1,,m) P(BIA)P(A) ∑P(4)P(BIA) P(AB) P(B) i
信息检索与数据挖掘 2019/3/31 19 乘法公式、全概率公式和贝叶斯公式 1 ( ) ( ) ( | ) n i i i P B P A P B A = • 乘法公式: • P(AB)=P(A)P(B|A) • P(A1A2…An )=P(A1 )P(A2 |A1 )...P(An |A1…An-1 ) • 全概率公式:A1A2…An是整个样本空间的一个划分 • 贝叶斯公式: A1A2…An是整个样本空间的一个划分 1 ( ) ( | ) ( | ) ,( 1,..., ) ( ) ( | ) j j j n i i i P A P B A P A B j n P A P B A

信息检索与数据挖掘 2019/3/31 20 随机变量 ·随机变量:若随机试验的各种可能的结果都能用一 个变量的取值(或范围)来表示,则称这个变量 为随机变量,常用X、Y、Z来表示 ·(离散型随机变量):掷一颗骰子,可能出现的点数X(可 能取值1、2、3、4、5、6) ·(连续型随机变量):北京地区的温度(-15~45)
信息检索与数据挖掘 2019/3/31 20 随机变量 • 随机变量:若随机试验的各种可能的结果都能用一 个 变量的取值(或范围)来表示,则称这个变量 为随机变量,常用X、Y、Z来表示 • (离散型随机变量):掷一颗骰子,可能出现的点数X (可 能取值1、2、3、4、5、6) • (连续型随机变量):北京地区的温度(-15~45)

信息检索与数据挖掘 2019/3/31 21 概率检索模型 概率检索模型是通过概率的方法将查询和文档联系 起来 定义3个随机变量R、Q、D:相关度R={0,1},查 询Q={q,q2…},文档D={d,d2,…},则可以通过 计算条件概率P(R=1I2=q,D=d来度量文档和查询 的相关度。 .概率模型包括一系列模型,如Logistic Regression( 回归)模型及最经典的二值独立概率模型BM、 BM25模型等等(还有贝叶斯网络模型)。 ·1998出现的基于统计语言建模的信息检索模型本质 上也是概率模型的一种
信息检索与数据挖掘 2019/3/31 21 概率检索模型 • 概率检索模型是通过概率的方法将查询和文档联系 起来 • 定义3个随机变量R、Q、D:相关度R={0,1},查 询Q={q1 ,q2 ,…},文档D={d1 ,d2 ,…},则可以通过 计算条件概率P(R=1|Q=q,D=d)来度量文档和查询 的相关度。 • 概率模型包括一系列模型,如Logistic Regression( 回归)模型及最经典的二值独立概率模型BIM、 BM25模型等等(还有贝叶斯网络模型)。 • 1998出现的基于统计语言建模的信息检索模型本质 上也是概率模型的一种