
信息检索与数据挖掘 2019/3/316 回顾:词项-文档关联矩阵 Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth Antony 7 1 0 0 0 1 Brutus 1 1 0 1 0 0 Caesar 1 1 0 1 Calpurnia 0 1 0 Cleopatra 1 0 0 0 mercy 1 worser 0 1 1 1 0 ·每个文档用一个二维向量表示∈{0,1}M ·布尔检索的本质 ·将查询q中出现的词项对应行取出做布尔运算
信息检索与数据挖掘 2019/3/31 6 回顾:词项-文档关联矩阵 • 每个文档用一个二维向量表示∈{0,1}|V| • 布尔检索的本质 • 将查询q中出现的词项对应行取出做布尔运算 Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth Antony 1 1 0 0 0 1 Brutus 1 1 0 1 0 0 Caesar 1 1 0 1 1 1 Calpurnia 0 1 0 0 0 0 Cleopatra 1 0 0 0 0 0 mercy 1 0 1 1 1 1 worser 1 0 1 1 1 0
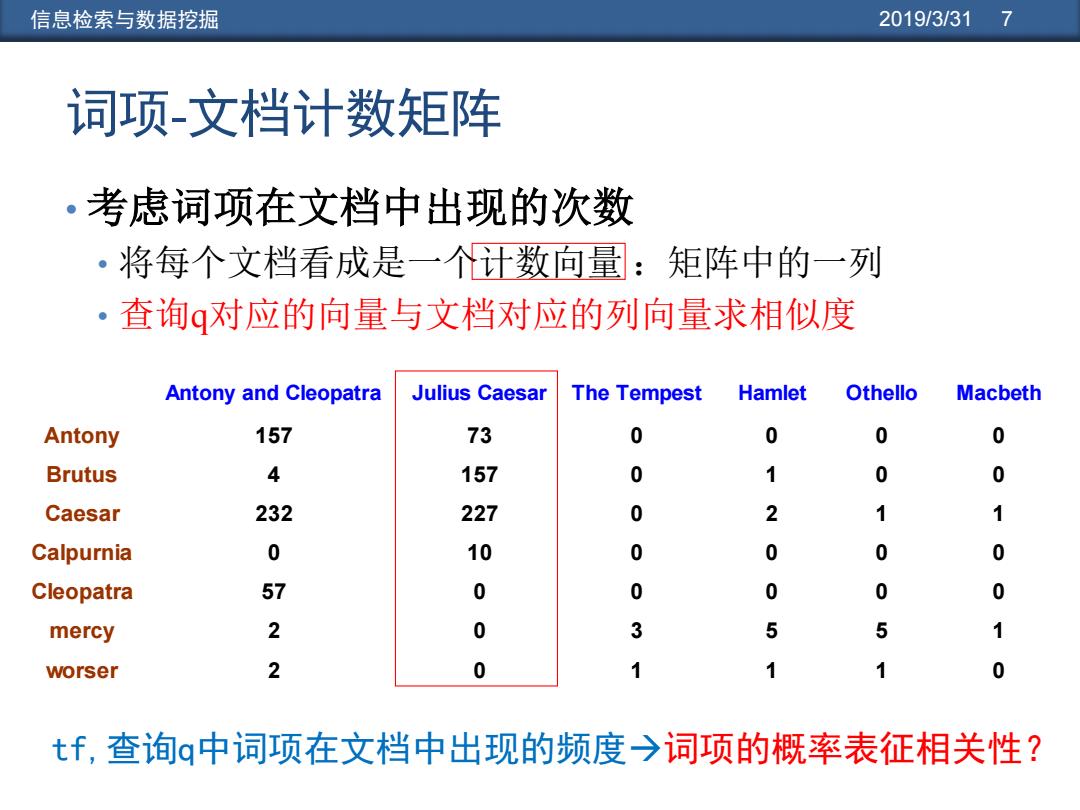
信息检索与数据挖掘 2019/3/31 7 词项-文档计数矩阵 ·考虑词项在文档中出现的次数 ·将每个文档看成是一个计数向量:矩阵中的一列 ·查询q对应的向量与文档对应的列向量求相似度 Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth Antony 157 73 0 0 0 0 Brutus 4 157 0 1 0 0 Caesar 232 227 0 2 1 Calpurnia 0 10 0 0 0 Cleopatra 57 0 0 0 0 0 mercy 2 0 3 5 5 1 worser 2 0 1 1 1 0 tf,查询q中词项在文档中出现的频度→词项的概率表征相关性?
信息检索与数据挖掘 2019/3/31 7 词项-文档计数矩阵 • 考虑词项在文档中出现的次数 • 将每个文档看成是一个计数向量 :矩阵中的一列 • 查询q对应的向量与文档对应的列向量求相似度 Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth Antony 157 73 0 0 0 0 Brutus 4 157 0 1 0 0 Caesar 232 227 0 2 1 1 Calpurnia 0 10 0 0 0 0 Cleopatra 57 0 0 0 0 0 mercy 2 0 3 5 5 1 worser 2 0 1 1 1 0 tf,查询q中词项在文档中出现的频度词项的概率表征相关性?

信息检索与数据挖掘 2019/3/318 二值→计数→权重矩阵(tf-idf值) Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth Antony 5.25 3.18 0 0 0 0.35 Brutus 1.21 6.1 0 1 0 0 Caesar 8.59 2.54 0 1.51 0.25 0 Calpurnia 0 1.54 0 0 0 0 Cleopatra 2.85 0 0 0 0 0 mercy 1.51 0 1.9 0.12 5.25 0.88 worser 1.37 0 0.11 4.15 0.25 1.95 ·每个文档可看成一个向量,其中每个分量对于词典 中一个词项,分量值为对于词项的tf-idf值 t「,查询g中词项在文档中出现的频度→词项的概率表征相关性? idf,罕见词的idf高而高频词的ⅰdf低→根据语言学修正词项的概率
信息检索与数据挖掘 2019/3/31 8 二值→ 计数 → 权重矩阵( tf-idf值) • 每个文档可看成一个向量,其中每个分量对于词典 中一个词项,分量值为对于词项的tf-idf值 Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth Antony 5.25 3.18 0 0 0 0.35 Brutus 1.21 6.1 0 1 0 0 Caesar 8.59 2.54 0 1.51 0.25 0 Calpurnia 0 1.54 0 0 0 0 Cleopatra 2.85 0 0 0 0 0 mercy 1.51 0 1.9 0.12 5.25 0.88 worser 1.37 0 0.11 4.15 0.25 1.95 tf,查询q中词项在文档中出现的频度词项的概率表征相关性? idf,罕见词的idf高而高频词的idf低根据语言学修正词项的概率
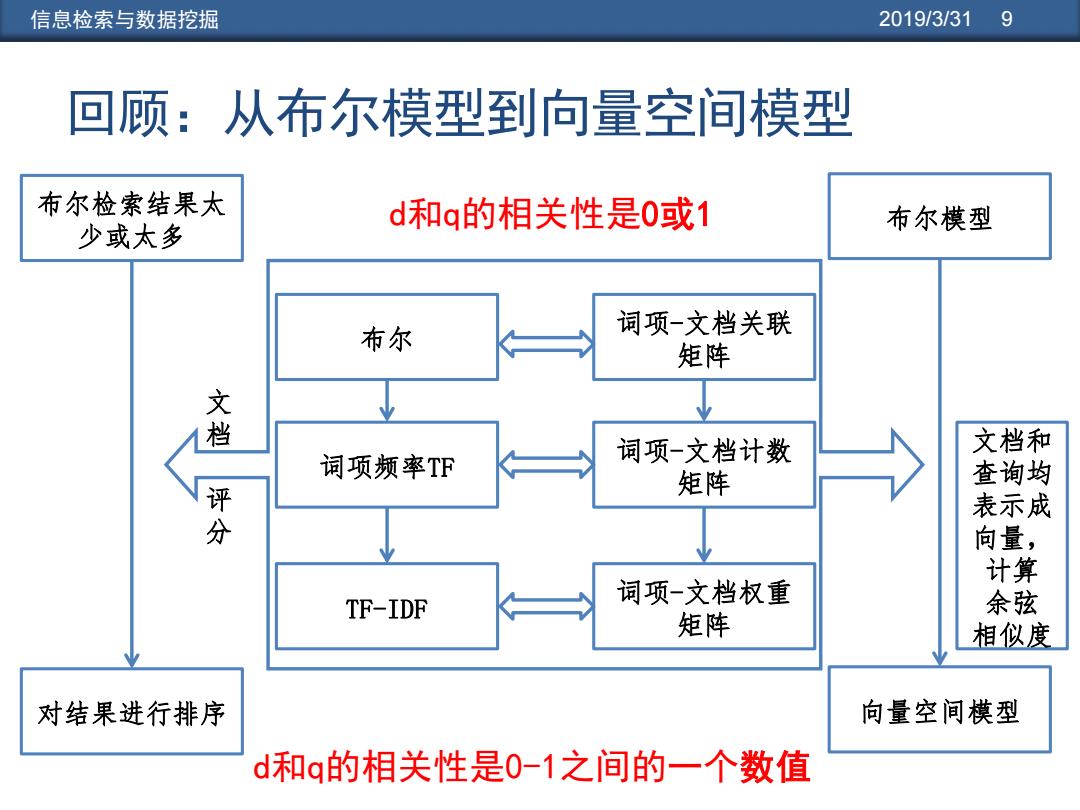
信息检索与数据挖掘 2019/3/319 回顾:从布尔模型到向量空间模型 布尔检索结果太 d和q的相关性是0或1 布尔模型 少或太多 布尔 词项-文档关联 矩阵 音 词项频率TF 词项-文档计数 文档和 查询均 矩阵 表示成 分 向量, 计算 词项-文档权重 TF-IDF 余弦 矩阵 相似度 对结果进行排序 向量空间模型 d和q的相关性是0-1之间的一个数值
信息检索与数据挖掘 2019/3/31 9 回顾:从布尔模型到向量空间模型 文 档 评 分 布尔检索结果太 少或太多 对结果进行排序 词项频率TF TF-IDF 布尔 词项-文档计数 矩阵 词项-文档权重 矩阵 词项-文档关联 矩阵 布尔模型 向量空间模型 文档和 查询均 表示成 向量, 计算 余弦 相似度 d和q的相关性是0或1 d和q的相关性是0-1之间的一个数值
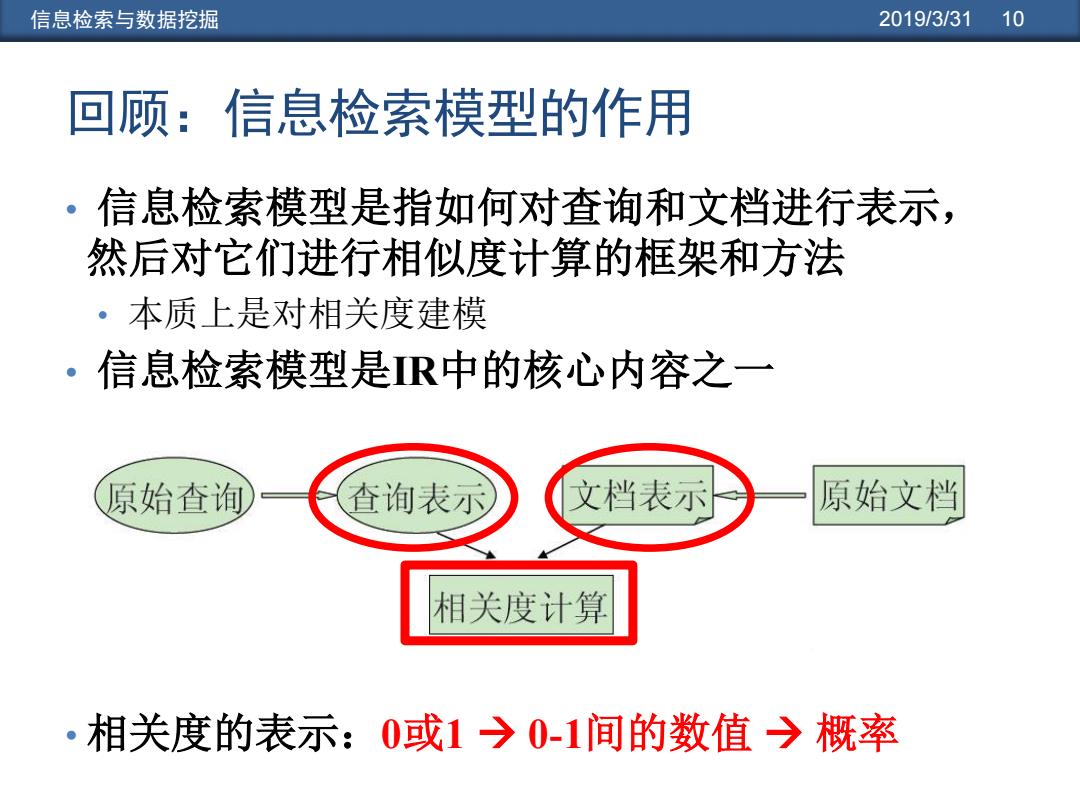
信息检索与数据挖掘 2019/3/31 10 回顾:信息检索模型的作用 信息检索模型是指如何对查询和文档进行表示, 。 然后对它们进行相似度计算的框架和方法 。本质上是对相关度建模 。信息检索模型是R中的核心内容之一 原始查询 查询表示 文档表示 原始文档 相关度计算 •相关度的表示:0或1→0-1间的数值→概率
信息检索与数据挖掘 2019/3/31 10 回顾:信息检索模型的作用 • 信息检索模型是指如何对查询和文档进行表示, 然后对它们进行相似度计算的框架和方法 • 本质上是对相关度建模 • 信息检索模型是IR中的核心内容之一 • 相关度的表示:0或1 0-1间的数值 概率