
第8卷第3期 智能系统学报 Vol.8 No.3 2013年6月 CAAI Transactions on Intelligent Systems Jun.2013 D0I:10.3969/i.issn.1673-4785.201211023 网络出版地址:http://www.cnki.net/kcms/detail/23.1538.TP.20130515.0927.005.html 引入复述技术的统计机器翻译研究综述 胡金铭2,史晓东12,苏劲松3,陈毅东12 (1.厦门大学信息科学与技术学院,福建厦门361005:2.厦门大学福建省仿脑智能系统重点实验室,福建厦门 361005;3.厦门大学软件学院,福建厦门361005) 摘要:基于对引入复述技术的统计机器翻译研究现状的分析,提出具有研究价值的课题方向.首先归纳了复述的概 念,总结了引入复述技术的统计机器翻译各类方法.然后对复述知识在统计机器翻译中的模型训练、参数调整、待译 语句改写和机器翻译自动评测等方面应用的主流方法进行了概括、比较和分析,说明了复述与统计机器翻译是紧密 相关的,强调了复述在统计机器翻译应用中的关键问题是复述的正确性和多样性最后指出提高复述资源的精确度、 建立复述与机器翻译的联合模型、采用新方法解决稀疏问题等是有待进一步研究的课题。 关键词:复述技术:机器翻译:统计机器翻译 中图分类号:TP391文献标志码:A文章编号:1673-4785(2013)03-0199-09 中文引用格式:胡金铭,史晓东,苏劲松,等.引入复述技术的统计机器翻译研究综述[J].智能系统学报,2013,8(3):199-207 英文引用格式:HU Jinming,SHI Xiaodong,SU Jinsong,etal.A survey of statistical machine translation using paraphrasing tech nology[J].CAAI Transactions on Intelligent Systems,2013,8(3):199-207. A survey of statistical machine translation using paraphrasing technology HU Jinming'2,SHI Xiaodong'2,SU Jinsong,CHEN Yidong'2 (1.School of Information Science and Engineering,Xiamen University,Xiamen 361005,China;2.Fujian Key Laboratory of the Brain-like Intelligent Systems,Xiamen University,Xiamen 361005,China;3.College of Software,Xiamen University,Xiamen 361005,China) Abstract:In this paper,the research team discussed possible new prospective research directions of paraphrasing technology in statistical machine translation (SMT),based on reviews of state-of-the-art technology.First the re- search team introduced the concept of paraphrases,and next a summarization of the latest progress utilizing para- phrasing technology in SMT was conducted.Finally,conclusions were drawn,data was compared and an analysis of the main issues of incorporating paraphrases into SMT,including translation model training,parameter tuning,in- put sentences rewriting and machine translation evaluation was performed.The results proved that there is an inher- ent connection between paraphrasing and SMT.The results also point out that the correctness and diversity of para- phrasing are the key issues to apply paraphrasing to SMT.It was highly noted that the improvement in the quality of paraphrasing resource,the establishment of a joint model of paraphrasing and machine translation and the new pro- posed approach to solve data sparseness are problems which need further study. Keywords:paraphrasing technology;machine translation;statistical machine translation 机器翻译(machine translation,MT)是利用计算 翻译.它属于计算语言学(computational linguistics) 机程序,实现从一种自然语言到另一种自然语言的 的范畴.经过数十年的研究,机器翻译在理论和实践 方面都有了较大的进步.从方法论的角度来看,目前 收稿日期:2012-11-16.网络出版日期:2013-05-15. 的主流研究使用基于统计的方法.统计机器翻译 基金项目:国家科技支撑计划资助项目(2012BAH14F03):国家自然 科学基金资助项目(60573189,61005052):福建省自然科 (statistical machine translation,SMT)是通过对大量 学基金资助项目(20060043) 通信作者:史晓东.E-mail:mandel@xmu.cdu.cn 双语平行语料库的统计分析来构建统计翻译模型
第 8 卷第 3 期 智 能 系 统 学 报 Vol.8 №.3 2013 年 6 月 CAAI Transactions on Intelligent Systems Jun. 2013 DOI:10.3969 / j.issn.1673⁃4785.201211023 网络出版地址:http: / / www.cnki.net / kcms/ detail / 23.1538.TP.20130515.0927.005.html 引入复述技术的统计机器翻译研究综述 胡金铭1,2 ,史晓东1,2 ,苏劲松3 ,陈毅东1,2 (1.厦门大学 信息科学与技术学院,福建 厦门 361005; 2.厦门大学 福建省仿脑智能系统重点实验室,福建 厦门 361005; 3.厦门大学 软件学院,福建 厦门 361005) 摘 要:基于对引入复述技术的统计机器翻译研究现状的分析,提出具有研究价值的课题方向.首先归纳了复述的概 念,总结了引入复述技术的统计机器翻译各类方法.然后对复述知识在统计机器翻译中的模型训练、参数调整、待译 语句改写和机器翻译自动评测等方面应用的主流方法进行了概括、比较和分析,说明了复述与统计机器翻译是紧密 相关的,强调了复述在统计机器翻译应用中的关键问题是复述的正确性和多样性.最后指出提高复述资源的精确度、 建立复述与机器翻译的联合模型、采用新方法解决稀疏问题等是有待进一步研究的课题. 关键词:复述技术;机器翻译;统计机器翻译 中图分类号: TP391 文献标志码:A 文章编号:1673⁃4785(2013)03⁃0199⁃09 中文引用格式:胡金铭,史晓东,苏劲松,等.引入复述技术的统计机器翻译研究综述[J].智能系统学报, 2013, 8(3): 199⁃207. 英文引用格式:HU Jinming, SHI Xiaodong, SU Jinsong, et al. A survey of statistical machine translation using paraphrasing tech⁃ nology[J]. CAAI Transactions on Intelligent Systems, 2013, 8(3): 199⁃207. A survey of statistical machine translation using paraphrasing technology HU Jinming 1,2 , SHI Xiaodong 1,2 , SU Jinsong 3 , CHEN Yidong 1,2 (1. School of Information Science and Engineering, Xiamen University, Xiamen 361005, China; 2. Fujian Key Laboratory of the Brain⁃like Intelligent Systems, Xiamen University, Xiamen 361005, China; 3. College of Software, Xiamen University, Xiamen 361005, China) Abstract:In this paper, the research team discussed possible new prospective research directions of paraphrasing technology in statistical machine translation ( SMT), based on reviews of state⁃of⁃the⁃art technology. First the re⁃ search team introduced the concept of paraphrases, and next a summarization of the latest progress utilizing para⁃ phrasing technology in SMT was conducted. Finally, conclusions were drawn, data was compared and an analysis of the main issues of incorporating paraphrases into SMT, including translation model training, parameter tuning, in⁃ put sentences rewriting and machine translation evaluation was performed. The results proved that there is an inher⁃ ent connection between paraphrasing and SMT. The results also point out that the correctness and diversity of para⁃ phrasing are the key issues to apply paraphrasing to SMT. It was highly noted that the improvement in the quality of paraphrasing resource, the establishment of a joint model of paraphrasing and machine translation and the new pro⁃ posed approach to solve data sparseness are problems which need further study. Keywords:paraphrasing technology; machine translation; statistical machine translation 收稿日期:2012⁃11⁃16. 网络出版日期:2013⁃05⁃15. 基金项目:国家科技支撑计划资助项目(2012BAH14F03);国家自然 科学基金资助项目( 60573189,61005052);福建省自然科 学基金资助项目(2006J0043). 通信作者:史晓东. E⁃mail:mandel@ xmu.edu.cn. 机器翻译(machine translation, MT)是利用计算 机程序,实现从一种自然语言到另一种自然语言的 翻译.它属于计算语言学( computational linguistics) 的范畴.经过数十年的研究,机器翻译在理论和实践 方面都有了较大的进步.从方法论的角度来看,目前 的主流研究使用基于统计的方法. 统计机器翻译 (statistical machine translation, SMT)是通过对大量 双语平行语料库的统计分析来构建统计翻译模型

·200· 能系统学报 第8卷 并使用该模型进行翻译.早期的研究使用噪声信道 模型风,当前的主流统计模型是对数线性模型) 1复述在统计机器翻译中的研究现状 对数线性模型由若干特征组成,每个特征都反映了 近年来,许多学者将复述应用到信息抽取、文本 翻译概率的一个方面,该模型由于可以包含更多的 生成、自动问答、自动文摘等多个相关研究领域中, 反映翻译概率的信息而受到了广泛关注.从事机器 如图1所示,对复述在自然语言处理的部分子课题 翻译研究的学者正尝试将不同的语言学、统计学特 中的文献资料做粗略统计(数据来自Google学术搜 征加人到对数线性模型中,使翻译系统更加强大.而 索),可见,其中讨论得最为广泛的是复述在机器翻 反映语言多样性的复述技术(paraphrasing technolo- 译研究中的应用. gies)也被用来改善机器翻译的效果. 随着自然语言处理各项底层技术的不断成熟和 其他 发展,复述(paraphrases)作为自然语言处理中一种 自动文摘, 9% 机器翻译 非常普遍的现象,受到了越来越多研究者的关注.刘 9% 31% 挺4)、赵世奇[)等国内学者也都对复述技术研究进 行了详细综述很多学者试图给复述一个精确的定 27% 义,早在20世纪80年代,语言学家Halliday和De 自动问答 18% Beaugrande等认为复述是“概念上的近似等价”,但 6% 信息抽取 互为复述的2个语言片段的可替换程度(inter- changeability)始终没有确切的标准[6-].Barzilay 文本生成 等[]把复述看作传达相同信息的可替换形式 图1复述在自然语言处理子课题的应用统计 Glickman等[o]则认为复述现象反映了语言多变性 Fig.1 Statistics of using paraphrases in sub-subject of NLP 的核心,复述是对应到相同意义的等价表达.鉴于上 复述是单语同义文本的表达形式转换,而机器 述观点,笔者认为复述就是在同一种语言内有相同 翻译则是跨语言同义文本的表达形式转换.它们的 语义但有不同表达形式的语言片段,它反映了人类 共通性也使得机器翻译中的理论和方法可以用于解 语言的灵活多样性,同时也为自然语言处理的研究 决复述问题,因此有基于MT的复述生成方法[)」 难点提供了更多的解决方法 同样,复述技术也可以解决机器翻译问题 统计机器翻译的实质是对大规模的双语语料进 在21世纪初,机器翻译中基于统计方法逐渐趋 行统计,提取有助于文本翻译的规则这些规则使得 于主导地位.在研究过程中,越来越多的学者发现语 翻译系统可以较好地处理字面上的直译,但其并没 料资源不足会极大影响统计翻译系统的翻译质量, 有真正意义上的意译能力,即无法翻译未知文本.随 复述便成为了一个解决办法.复述可以从更为广泛 着时间的推进,科技发展、知识增长,语言也在不断 的语料中获取,如同义词词典、单语可比语料、单语 地进化,不可能存在包含所有语言现象的语料库.然 平行语料等,更多的单语知识可以改善翻译系统性 而,复述技术可以将未知文本片段转化成语料库中 能.从方法角度上讲,将复述引入到统计机器翻译的 出现的同义表述:那么,适时地引入复述技术便可以 研究集中在改进其4个阶段,引入到前3个阶段是 提高翻译系统的性能。 为了提升翻译效果,而对于自动评测主要是为了提 目前由于统计机器翻译的研究热点是对数线性 升机器评价和人工评价的一致性.为了更直观地对 模型,因此将复述技术引入统计机器翻译的研究也 比前3种途径翻译效果的提升程度,图2列出了各 多数围绕对数线型模型展开.基于对数线性模型的 方法在BLEU值上的提升比.因为各学者选取的实 统计机器翻译大致可以分为4个阶段:翻译模型的 验数据并不一致,结果对比可能略有出入.但从图2 训练、特征参数的调整、译文的搜索解码、翻译质量 中可以发现,对待译语句的改写可以更好地提升翻 的自动评价.本文介绍了复述与统计机器翻译的概 译质量(图中的参数调整部分,因为数据都来自 念,并对复述技术与统计机器翻译中各个阶段内容 Madnani的研究,故命名为“年份.人工参考译文数 的联系进行概述,最后对引入复述技术的统计机器 量”,“H”前的数字表示开发集的人工参考译文数 翻译研究进展及前沿课题进行分析评述,概括并凝 量).下面从4个方面分别介绍引入复述的统计机器 练出具有研究价值的课题方向,希望对统计机器翻 翻译研究的国内外发展现状」 译领域的研究有所神益
并使用该模型进行翻译.早期的研究使用噪声信道 模型[1⁃2] ,当前的主流统计模型是对数线性模型[3] . 对数线性模型由若干特征组成,每个特征都反映了 翻译概率的一个方面,该模型由于可以包含更多的 反映翻译概率的信息而受到了广泛关注.从事机器 翻译研究的学者正尝试将不同的语言学、统计学特 征加入到对数线性模型中,使翻译系统更加强大.而 反映语言多样性的复述技术( paraphrasing technolo⁃ gies)也被用来改善机器翻译的效果. 随着自然语言处理各项底层技术的不断成熟和 发展,复述( paraphrases)作为自然语言处理中一种 非常普遍的现象,受到了越来越多研究者的关注.刘 挺[4] 、赵世奇[5]等国内学者也都对复述技术研究进 行了详细综述.很多学者试图给复述一个精确的定 义,早在 20 世纪 80 年代,语言学家 Halliday 和 De Beaugrande 等认为复述是“概念上的近似等价”,但 互为复述的 2 个语言片段的可替换程度 ( inter⁃ changeability) 始 终 没 有 确 切 的 标 准[6⁃7] . Barzilay 等[8⁃9]把复述看作传达相同信息的可替换形式. Glickman 等[10]则认为复述现象反映了语言多变性 的核心,复述是对应到相同意义的等价表达.鉴于上 述观点,笔者认为复述就是在同一种语言内有相同 语义但有不同表达形式的语言片段,它反映了人类 语言的灵活多样性,同时也为自然语言处理的研究 难点提供了更多的解决方法. 统计机器翻译的实质是对大规模的双语语料进 行统计,提取有助于文本翻译的规则.这些规则使得 翻译系统可以较好地处理字面上的直译,但其并没 有真正意义上的意译能力,即无法翻译未知文本.随 着时间的推进,科技发展、知识增长,语言也在不断 地进化,不可能存在包含所有语言现象的语料库.然 而,复述技术可以将未知文本片段转化成语料库中 出现的同义表述;那么,适时地引入复述技术便可以 提高翻译系统的性能. 目前由于统计机器翻译的研究热点是对数线性 模型,因此将复述技术引入统计机器翻译的研究也 多数围绕对数线型模型展开.基于对数线性模型的 统计机器翻译大致可以分为 4 个阶段:翻译模型的 训练、特征参数的调整、译文的搜索解码、翻译质量 的自动评价.本文介绍了复述与统计机器翻译的概 念,并对复述技术与统计机器翻译中各个阶段内容 的联系进行概述,最后对引入复述技术的统计机器 翻译研究进展及前沿课题进行分析评述,概括并凝 练出具有研究价值的课题方向,希望对统计机器翻 译领域的研究有所裨益. 1 复述在统计机器翻译中的研究现状 近年来,许多学者将复述应用到信息抽取、文本 生成、自动问答、自动文摘等多个相关研究领域中. 如图 1 所示,对复述在自然语言处理的部分子课题 中的文献资料做粗略统计(数据来自 Google 学术搜 索),可见,其中讨论得最为广泛的是复述在机器翻 译研究中的应用. 图 1 复述在自然语言处理子课题的应用统计 Fig.1 Statistics of using paraphrases in sub⁃subject of NLP 复述是单语同义文本的表达形式转换,而机器 翻译则是跨语言同义文本的表达形式转换.它们的 共通性也使得机器翻译中的理论和方法可以用于解 决复述问题,因此有基于 MT 的复述生成方法[11⁃13] . 同样,复述技术也可以解决机器翻译问题. 在 21 世纪初,机器翻译中基于统计方法逐渐趋 于主导地位.在研究过程中,越来越多的学者发现语 料资源不足会极大影响统计翻译系统的翻译质量, 复述便成为了一个解决办法.复述可以从更为广泛 的语料中获取,如同义词词典、单语可比语料、单语 平行语料等,更多的单语知识可以改善翻译系统性 能.从方法角度上讲,将复述引入到统计机器翻译的 研究集中在改进其 4 个阶段,引入到前 3 个阶段是 为了提升翻译效果,而对于自动评测主要是为了提 升机器评价和人工评价的一致性.为了更直观地对 比前 3 种途径翻译效果的提升程度,图 2 列出了各 方法在 BLEU 值上的提升比.因为各学者选取的实 验数据并不一致,结果对比可能略有出入.但从图 2 中可以发现,对待译语句的改写可以更好地提升翻 译质量( 图中的参数调整部分,因为数据都来自 Madnani 的研究,故命名为“年份.人工参考译文数 量”,“H” 前的数字表示开发集的人工参考译文数 量).下面从 4 个方面分别介绍引入复述的统计机器 翻译研究的国内外发展现状. ·200· 智 能 系 统 学 报 第 8 卷

第3期 胡金铭,等:引入复述技术的统计机器翻译研究综述 ·201· (2)所示: 三 Pre(elf月=P(eIC(e))×P(C(e)ICf))= 6 三 #(e)x#(c(e),cD) (2) 尊 三 #C(e)#C(f) 式中:C(e)、C()分别代表目标端和源端的短语类 研究者认为复述片段含义相同,不应分别进行概率 0 估计,应对同类短语一并计算.可以验证,当P为0 模型训练 参数调整 语句改写 时,Ppc不为O.所以当e出现的频次很小时,Pc会有 图2各方法效果对比 更好的概率估计.他提出了利用基于短语共现次数 Fig.2 Comparison with BLEU on various methods 和基于词序的2种相似度计算来进行短语聚类的方 法,获得了很好的效果 1.1复述改善模型训练 Max针对短语概率估计提出了2个观点:1)一 训练数据不足会引起数据稀疏,引入复述知识, 个合适的短语需要更多地参与到概率估计:2)复述 对已有的训练数据或者规则表进行处理可以改善这 可以用来优化概率估计).他利用源端∫的上下文 一问题.通常有2种途径:1)对训练数据的平行句对 相似度的计算代替传统的频次统计,上下文相似度 生成复述从而扩充训练数据的规模:2)利用短语间 偏低的短语,其概率的估计也会较低,则相应译文可 的复述关系平滑翻译模型的概率估计使其更加 取度降低.如式(3)所示: 准确. 以 sim(Cont(f),Cont(f)) 统计机器翻译的模型训练是通过大规模的双语 Pom(e;I f)= 平行语料获得.由于语言的多样性,训练集不能覆盖 sim(Cont(f),Cont(f)) 所有的语言现象,对稀有语种而言尤为明显.当无法 (3) 直接获得更多训练语料时,研究者利用复述技术扩 充训练集的规模,提高模型的覆盖率.基本思想是对 w以 sim(Cont(f),Cont(p)) 双语平行句对(f,)的源端f生成句法等价的句级 P(e:I A= sim(Cont(f月,Cont(pk)) 复述fPP与目标端e重新组合构成新句对(fP,e) (4) 加入到训练集中.Bond针对词序、时态等语言学现 象并结合句法信息生成复述I4).Nakov则对名词短 式中:f是测试集中待译的源短语,f是∫在训练集 语进行复述,首先识别句中的名词短语,利用人 中出现的第k个特例,e,表示f的所有可能译文,e 是f的特定译文,Cont(f)是指f的上下文.P通过 为定义的包含句法信息的复述规则,仅当句子中发 比较测试语句中短语f的上下文与译文为e:的特例 现符合复述转换规则结构的名词短语时才生成复 f的上下文的相似度,来估计e:是f译文的概率.式 述.Nakov不但扩充训练集,还对已训练的规则表进 (4)利用复述对式(3)进行补充,作为另一个特征加 行类似实验,结果表明对短语表进行复述并没有对 训练数据进行复述的效果好.这是因为规则表是经 入到模型中p:是f的复述,〈P:,e:〉是训练集中的短 语对.同样,考虑上下文信息来估计e:是f译文的概 过分词、对齐等前序步骤后得到,其中已含有噪声; 率.式(3)解决了Max提出的第1个问题,使上下文 同时对规则表复述没有考虑句法信息及上下文信 信息更接近短语主导概率的估计,式(4)则缓解了 息,新生成的翻译规则可能并不合理。 上下文种类较少带来的数据稀疏问题, 短语概率作为SMT的一个非常重要的特征,传 1.2复述提高调参效果 统方法使用最大似然估计,通过词频的累加来计算, 目前统计机器翻译的参数调整大多采用最小错 如式(1)所示,式中#表示频次统计.这种方法的不足 误率训练方法[18].通常使用基于n元组匹配的 之处是,当短语出现次数较少时,其概率估计会出现 BLEU]等评测指标作为最小错误率.因此在调参 较大误差.Kuhn和Max引入复述技术来进行平滑翻 过程中所使用的开发集规模越大、多样性越强、参考 译模型概率估计的研究。 译文数量越多,n元组匹配的准确性就越高,调参的 #(f,e:) PRF(e:IA)=- (1) 效果也就越好.基于这个思想,Madnani引入复述知 ∑#(f,e) 识,对开发集的参考译文进行扩展,来增加参考译文 Kuhn利用短语聚类来进行平滑处理o],如式 的多样性2).首先,利用层次短语系统训练出双语
图 2 各方法效果对比 Fig.2 Comparison with BLEU on various methods 1.1 复述改善模型训练 训练数据不足会引起数据稀疏,引入复述知识, 对已有的训练数据或者规则表进行处理可以改善这 一问题.通常有 2 种途径:1)对训练数据的平行句对 生成复述从而扩充训练数据的规模;2)利用短语间 的复述关系平滑翻译模型的概率估计使其更加 准确. 统计机器翻译的模型训练是通过大规模的双语 平行语料获得.由于语言的多样性,训练集不能覆盖 所有的语言现象,对稀有语种而言尤为明显.当无法 直接获得更多训练语料时,研究者利用复述技术扩 充训练集的规模,提高模型的覆盖率.基本思想是对 双语平行句对( f,e)的源端 f 生成句法等价的句级 复述 f’,f’与目标端 e 重新组合构成新句对( f’,e) 加入到训练集中.Bond 针对词序、时态等语言学现 象并结合句法信息生成复述[14] .Nakov 则对名词短 语进行复述[15] ,首先识别句中的名词短语,利用人 为定义的包含句法信息的复述规则,仅当句子中发 现符合复述转换规则结构的名词短语时才生成复 述.Nakov 不但扩充训练集,还对已训练的规则表进 行类似实验,结果表明对短语表进行复述并没有对 训练数据进行复述的效果好.这是因为规则表是经 过分词、对齐等前序步骤后得到,其中已含有噪声; 同时对规则表复述没有考虑句法信息及上下文信 息,新生成的翻译规则可能并不合理. 短语概率作为 SMT 的一个非常重要的特征,传 统方法使用最大似然估计,通过词频的累加来计算, 如式(1)所示,式中#表示频次统计.这种方法的不足 之处是,当短语出现次数较少时,其概率估计会出现 较大误差.Kuhn 和 Max 引入复述技术来进行平滑翻 译模型概率估计的研究. PRF(ei | f) = #(f,ei) ∑j #(f,ej) . (1) Kuhn 利用短语聚类来进行平滑处理[16] ,如式 (2)所示: PPC(e | f) = P(e | C(e)) × P(C(e) | C(f)) = #(e) #C(e) × #(C(e),C(f)) #C(f) . (2) 式中:C(e)、C(f)分别代表目标端和源端的短语类. 研究者认为复述片段含义相同,不应分别进行概率 估计,应对同类短语一并计算.可以验证,当 PRF为 0 时,PPC不为 0.所以当 e 出现的频次很小时,PPC会有 更好的概率估计.他提出了利用基于短语共现次数 和基于词序的 2 种相似度计算来进行短语聚类的方 法,获得了很好的效果. Max 针对短语概率估计提出了 2 个观点:1)一 个合适的短语需要更多地参与到概率估计;2)复述 可以用来优化概率估计[17] .他利用源端 f 的上下文 相似度的计算代替传统的频次统计,上下文相似度 偏低的短语,其概率的估计也会较低,则相应译文可 取度降低.如式(3)所示: Pcont(ei | f) = ∑〈f k ,e i 〉 sim(Cont(f),Cont(f k)) ∑〈f k ,e j 〉 sim(Cont(f),Cont(f k)) . (3) Ppara(ei | f) = ∑〈p k ,e i 〉 sim(Cont(f),Cont(pk)) ∑〈p k ,e j 〉 sim(Cont(f),Cont(pk)) . (4) 式中:f 是测试集中待译的源短语,f k 是 f 在训练集 中出现的第 k 个特例,ej 表示 f k 的所有可能译文,ei 是 f k 的特定译文,Cont(f)是指 f 的上下文.Pcont通过 比较测试语句中短语 f 的上下文与译文为 ei 的特例 f k 的上下文的相似度,来估计 ei 是 f 译文的概率.式 (4)利用复述对式(3)进行补充,作为另一个特征加 入到模型中.pk 是 f 的复述,〈pk,ei〉是训练集中的短 语对.同样,考虑上下文信息来估计 ei 是 f 译文的概 率.式(3)解决了 Max 提出的第 1 个问题,使上下文 信息更接近短语主导概率的估计,式(4) 则缓解了 上下文种类较少带来的数据稀疏问题. 1.2 复述提高调参效果 目前统计机器翻译的参数调整大多采用最小错 误率训练方 法[18] . 通 常 使 用 基 于 n 元 组 匹 配 的 BLEU [19]等评测指标作为最小错误率.因此在调参 过程中所使用的开发集规模越大、多样性越强、参考 译文数量越多,n 元组匹配的准确性就越高,调参的 效果也就越好.基于这个思想,Madnani 引入复述知 识,对开发集的参考译文进行扩展,来增加参考译文 的多样性[20] .首先,利用层次短语系统训练出双语 第 3 期 胡金铭,等:引入复述技术的统计机器翻译研究综述 ·201·
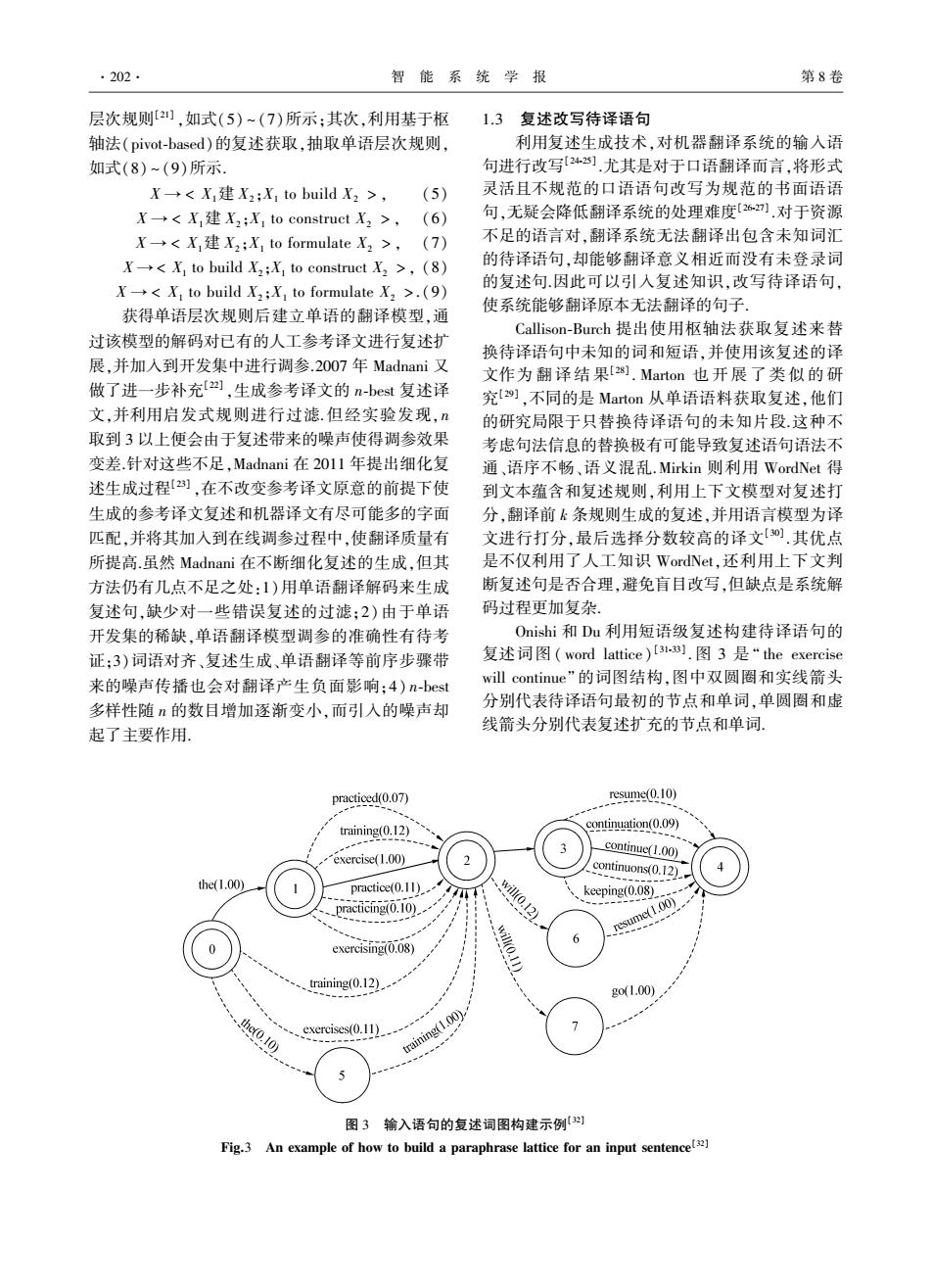
·202· 智 能系统学报 第8卷 层次规则[2],如式(5)~(7)所示:其次,利用基于枢 1.3复述改写待译语句 轴法(pivot-.based)的复述获取,抽取单语层次规则, 利用复述生成技术,对机器翻译系统的输入语 如式(8)~(9)所示。 句进行改写24].尤其是对于口语翻译而言,将形式 X→<X,建X2;X,to build X2>, (5) 灵活且不规范的口语语句改写为规范的书面语语 X→<X,建X2:X1 to construct X2>,(6) 句,无疑会降低翻译系统的处理难度[262.对于资源 X→<X,建X2;X,to formulate X2>,(7) 不足的语言对,翻译系统无法翻译出包含未知词汇 <X to build X2;X to construct X2 >(8) 的待译语句,却能够翻译意义相近而没有未登录词 <X to build X2;X to formulate X2 >.(9) 的复述句.因此可以引入复述知识,改写待译语句, 使系统能够翻译原本无法翻译的句子 获得单语层次规则后建立单语的翻译模型,通 Callison-Burch提出使用枢轴法获取复述来替 过该模型的解码对已有的人工参考译文进行复述扩 换待译语句中未知的词和短语,并使用该复述的译 展,并加入到开发集中进行调参.2007年Madnani又 文作为翻译结果[2】.Marton也开展了类似的研 做了进一步补充2四,生成参考译文的n-best复述译 究[],不同的是Marton从单语语料获取复述,他们 文,并利用启发式规则进行过滤.但经实验发现,n 的研究局限于只替换待译语句的未知片段这种不 取到3以上便会由于复述带来的噪声使得调参效果 考虑句法信息的替换极有可能导致复述语句语法不 变差.针对这些不足,Madnani在2011年提出细化复 通、语序不畅、语义混乱.Mirkin则利用WordNet得 述生成过程],在不改变参考译文原意的前提下使 到文本蕴含和复述规则,利用上下文模型对复述打 生成的参考译文复述和机器译文有尽可能多的字面 分,翻译前k条规则生成的复述,并用语言模型为译 匹配,并将其加入到在线调参过程中,使翻译质量有 文进行打分,最后选择分数较高的译文[].其优点 所提高.虽然Madnani在不断细化复述的生成,但其 是不仅利用了人工知识WordNet,还利用上下文判 方法仍有几,点不足之处:1)用单语翻译解码来生成 断复述句是否合理,避免盲目改写,但缺点是系统解 复述句,缺少对一些错误复述的过滤:2)由于单语 码过程更加复杂。 开发集的稀缺,单语翻译模型调参的准确性有待考 Onishi和Du利用短语级复述构建待译语句的 证:3)词语对齐、复述生成、单语翻译等前序步骤带 复述词图(word lattice)[3-3].图3是“the exercise 来的噪声传播也会对翻译产生负面影响:4)n-best will continue'”的词图结构,图中双圆圈和实线箭头 多样性随的数目增加逐渐变小,而引入的噪声却 分别代表待译语句最初的节点和单词,单圆圈和虚 起了主要作用 线箭头分别代表复述扩充的节点和单词 practiced(0.07) resume(0.10) training(0.12) continuation(0.09) --- 3 exercise(1.00) continue(1.00) continuons(0.12) 4 the(1.00) practice(0.11) practicing(0.10) wi0.122 keeping(0.08) resume(1.00) 6 exercising(0.08) wi0.11) training(0.12) go1.00) hc0.10) -exercises(0.11) training(1.00) 图3输入语句的复述词图构建示例) Fig.3 An example of how to build a paraphrase lattice for an input sentencet]
层次规则[21] ,如式(5) ~ (7)所示;其次,利用基于枢 轴法(pivot⁃based)的复述获取,抽取单语层次规则, 如式(8) ~ (9)所示. X → < X1建 X2 ;X1 to build X2 > , (5) X → < X1建 X2 ;X1 to construct X2 > , (6) X → < X1建 X2 ;X1 to formulate X2 > , (7) X → < X1 to build X2;X1 to construct X2 > , (8) X → < X1 to build X2 ;X1 to formulate X2 > .(9) 获得单语层次规则后建立单语的翻译模型,通 过该模型的解码对已有的人工参考译文进行复述扩 展,并加入到开发集中进行调参.2007 年 Madnani 又 做了进一步补充[22] ,生成参考译文的 n⁃best 复述译 文,并利用启发式规则进行过滤.但经实验发现,n 取到 3 以上便会由于复述带来的噪声使得调参效果 变差.针对这些不足,Madnani 在 2011 年提出细化复 述生成过程[23] ,在不改变参考译文原意的前提下使 生成的参考译文复述和机器译文有尽可能多的字面 匹配,并将其加入到在线调参过程中,使翻译质量有 所提高.虽然 Madnani 在不断细化复述的生成,但其 方法仍有几点不足之处:1)用单语翻译解码来生成 复述句,缺少对一些错误复述的过滤;2) 由于单语 开发集的稀缺,单语翻译模型调参的准确性有待考 证;3)词语对齐、复述生成、单语翻译等前序步骤带 来的噪声传播也会对翻译产生负面影响;4) n⁃best 多样性随 n 的数目增加逐渐变小,而引入的噪声却 起了主要作用. 1.3 复述改写待译语句 利用复述生成技术,对机器翻译系统的输入语 句进行改写[24⁃25] .尤其是对于口语翻译而言,将形式 灵活且不规范的口语语句改写为规范的书面语语 句,无疑会降低翻译系统的处理难度[26⁃27] .对于资源 不足的语言对,翻译系统无法翻译出包含未知词汇 的待译语句,却能够翻译意义相近而没有未登录词 的复述句.因此可以引入复述知识,改写待译语句, 使系统能够翻译原本无法翻译的句子. Callison⁃Burch 提出使用枢轴法获取复述来替 换待译语句中未知的词和短语,并使用该复述的译 文作为 翻 译 结 果[28] . Marton 也 开 展 了 类 似 的 研 究[29] ,不同的是 Marton 从单语语料获取复述,他们 的研究局限于只替换待译语句的未知片段.这种不 考虑句法信息的替换极有可能导致复述语句语法不 通、语序不畅、语义混乱.Mirkin 则利用 WordNet 得 到文本蕴含和复述规则,利用上下文模型对复述打 分,翻译前 k 条规则生成的复述,并用语言模型为译 文进行打分,最后选择分数较高的译文[30] .其优点 是不仅利用了人工知识 WordNet,还利用上下文判 断复述句是否合理,避免盲目改写,但缺点是系统解 码过程更加复杂. Onishi 和 Du 利用短语级复述构建待译语句的 复述词图 ( word lattice) [31⁃33] . 图 3 是 “ the exercise will continue” 的词图结构,图中双圆圈和实线箭头 分别代表待译语句最初的节点和单词,单圆圈和虚 线箭头分别代表复述扩充的节点和单词. 图 3 输入语句的复述词图构建示例[32] Fig.3 An example of how to build a paraphrase lattice for an input sentence [32] ·202· 智 能 系 统 学 报 第 8 卷

第3期 胡金铭,等:引人复述技术的统计机器翻译研究综述 ·203· 构建词图的好处是不用区分待译语句中的未知 的复述规则中没有实词的替换规则,所以该方法减 词和已知词,而是让翻译系统的解码器根据词图自 少了内容词替换带来的任意性:但只能处理功能词 行搜索最优翻译结果,提高容错性.这样可以构造比 和日文语气词,有一定局限性.Lepage利用类似复述 Callison-Burch方法更为流利的复述输入语句,其缺 模板的方法生成参考译文的复述集,丰富参考译文 陷在于构造词图时过多的边数会导致复杂度成倍提 的表达[].Zhou则针对BLEU没有考虑召回率和缺 升.此外,部分不当替换不但会增大词图的搜索空间 少对复述匹配的支持来进行改善,提出了基于 而且也不能改善翻译效果,需进行适当的剪枝.He BLEU的ParaEval评测方法[3,对1-gram的匹配进 的研究[3]与Du相似,他采用一种正向翻译与反向 行修改使其支持了复述匹配,并使用单参考译文计 翻译相结合的方法获取复述.正向翻译就是源端到 算召回率. 目标端的翻译过程,反向翻译则是目标端到源端的 Russo-Lassner对(x,h)训练线性回归模型,其 翻译过程.他利用一次正向翻译的译文T和经过反 中x是一个代表机器译文和参考译文句对间一致性 向翻译后再正向翻译的译文T,作为抽取复述的单 的特征向量,h是对机器译文的人工评分[o.他将机 语平行语料,然后通过启发式规则的过滤,利用层次 器翻译自动评测任务看作复述识别,即对比机器译 短语系统的规则抽取方法[2]构建复述规则,之后再 文与参考译文之间的词汇、句法信息的变化,因此特 构造词图这样做的好处有2点:1)不但生成了词和 征选择包括词千共现、WordNet同义词集、动词语义 短语级的复述,而且可以生成句级的复述:2)因为 类等 复述规则由翻译系统得来,对于部分病态复述,经翻 Snover基于其在2006年提出的TER评测指 译系统的病态处理,会意外获得质量更好的结果,这 标,融合了可调参数、形态学分析、同义词以及复述 也体现了复述和统计机器翻译融合的思想 之后,提出新的评测指标TERp[412].TERp不但将参 Resnik通过迭代修改待译语句来解决翻译质量 考译文和机器译文字面相同的片段匹配,还将有相 较差的问题[]其方法是,对翻译系统的翻译结果 同词干或同义词的片段匹配.TER即保留了TER的 进行评判,将译文中翻译较差的片段所对应的源语 编辑操作一匹配、插人、删除、替换、移动,还增加 句片段进行复述,构造出新的输入语句,新输入语句 了词干匹配、同义词匹配、短语替换,使评价结果与 的译文要优于原译文.该方法较Callison-Burch的方 人工评价的一致性更高: 法[2)能更针对地构造复述,利用TER即中定义的多 Pado将文本蕴含(textual entailment)用在机器 种操作来判断哪些片段应该构造复述, 翻译的评测中[4).蕴含被定义为一个前提P(prem- 1.4复述改善机器翻译自动评测 ise)和一个假设H(hypothesis)之间的二元关系,即 机器翻译的自动评测一直是机器翻译研究中的 若已知前提P成立可以推出H为真,则说P蕴含H 难点,目前最为广泛使用的指标是BLEU9,它计算 研究者一般将复述看作蕴含的特例,因为复述是双 机器译文和参考译文间n-gram的匹配准确率,将其 向的,而蕴含的推理是单向的.举例说明:设P为 加权得到评价分数.很多学者基于BLEU指标改善 “Jane is a French teacher”,H为“Jane can speak 机器翻译的自动测评.Kauchak调查发现,NIST2004 French”,则P蕴含H,H可从P中推理出来,相反P 测试集中每个句子的参考译文两两组成句对,其中 不一定能从H推理出来.Pado认为好的机器译文与 0.2%是字面完全一致的,60%至少11个词不同] 参考译文是双向蕴含的,机器译文内容的缺失会破 这就意味着,如果参考译文的数量有限时(1~3 坏正向蕴含,而机器译文内容的增添又会打破反向 句),那么基于字面匹配的自动评测永远不可能达 蕴含,如果双向蕴含都不成立则认为翻译结果较差 到人工评测的水平.因此,Kauchak提出应该使参考 蕴含识别可以包含更多的语义和语法知识,利用蕴 译文更多地包含机器译文的词或短语,而这也是早 含信息的“深度”匹配自然会优于简单的字面匹配 期学者们改善评测技术的主要手段.他利用WordNet 评测标准 从参考译文和机器译文中识别可能构造复述的词 2复述在统计机器翻译中的应用分析 对,测试候选复述是否在参考译文的上下文中可采 纳,然后生成参考译文的复述,达到增加参考译文数 复述作为人类语言中的一个普遍现象,受到自 量的目的.Kanayama考虑日语相比英语更多样性和 然语言处理界学者的广泛关注.尤其在机器翻译领 胶合性[列],利用人工定义的复述规则加以形态学分 域,在不同的阶段引入复述技术,在一定程度上改善 析,生成参考译文的复述,构造更多的参考译文,来 了翻译质量.鉴于前人的研究工作,将复述引入机器 提高自动评价和人工评价的一致性.因为人工定义 翻译的不同阶段中,确实可以改善翻译结果但在机
构建词图的好处是不用区分待译语句中的未知 词和已知词,而是让翻译系统的解码器根据词图自 行搜索最优翻译结果,提高容错性.这样可以构造比 Callison⁃Burch 方法更为流利的复述输入语句,其缺 陷在于构造词图时过多的边数会导致复杂度成倍提 升.此外,部分不当替换不但会增大词图的搜索空间 而且也不能改善翻译效果,需进行适当的剪枝. He 的研究[34]与 Du 相似,他采用一种正向翻译与反向 翻译相结合的方法获取复述.正向翻译就是源端到 目标端的翻译过程,反向翻译则是目标端到源端的 翻译过程.他利用一次正向翻译的译文 T1 和经过反 向翻译后再正向翻译的译文 T2 作为抽取复述的单 语平行语料,然后通过启发式规则的过滤,利用层次 短语系统的规则抽取方法[21]构建复述规则,之后再 构造词图.这样做的好处有 2 点:1)不但生成了词和 短语级的复述,而且可以生成句级的复述;2) 因为 复述规则由翻译系统得来,对于部分病态复述,经翻 译系统的病态处理,会意外获得质量更好的结果,这 也体现了复述和统计机器翻译融合的思想. Resnik 通过迭代修改待译语句来解决翻译质量 较差的问题[35] .其方法是,对翻译系统的翻译结果 进行评判,将译文中翻译较差的片段所对应的源语 句片段进行复述,构造出新的输入语句,新输入语句 的译文要优于原译文.该方法较 Callison⁃Burch 的方 法[28]能更针对地构造复述,利用 TERp 中定义的多 种操作来判断哪些片段应该构造复述. 1.4 复述改善机器翻译自动评测 机器翻译的自动评测一直是机器翻译研究中的 难点,目前最为广泛使用的指标是 BLEU [19] ,它计算 机器译文和参考译文间 n⁃gram 的匹配准确率,将其 加权得到评价分数.很多学者基于 BLEU 指标改善 机器翻译的自动测评.Kauchak 调查发现,NIST2004 测试集中每个句子的参考译文两两组成句对,其中 0.2%是字面完全一致的,60%至少 11 个词不同[36] . 这就意味着,如果参考译文的数量有限时 ( 1 ~ 3 句),那么基于字面匹配的自动评测永远不可能达 到人工评测的水平.因此,Kauchak 提出应该使参考 译文更多地包含机器译文的词或短语,而这也是早 期学者们改善评测技术的主要手段.他利用 WordNet 从参考译文和机器译文中识别可能构造复述的词 对,测试候选复述是否在参考译文的上下文中可采 纳,然后生成参考译文的复述,达到增加参考译文数 量的目的.Kanayama 考虑日语相比英语更多样性和 胶合性[37] ,利用人工定义的复述规则加以形态学分 析,生成参考译文的复述,构造更多的参考译文,来 提高自动评价和人工评价的一致性.因为人工定义 的复述规则中没有实词的替换规则,所以该方法减 少了内容词替换带来的任意性;但只能处理功能词 和日文语气词,有一定局限性.Lepage 利用类似复述 模板的方法生成参考译文的复述集,丰富参考译文 的表达[38] .Zhou 则针对 BLEU 没有考虑召回率和缺 少对复 述 匹 配 的 支 持 来 进 行 改 善, 提 出 了 基 于 BLEU 的 ParaEval 评测方法[39] ,对 1⁃gram 的匹配进 行修改使其支持了复述匹配,并使用单参考译文计 算召回率. Russo⁃Lassner 对( x,h) 训练线性回归模型,其 中 x 是一个代表机器译文和参考译文句对间一致性 的特征向量,h 是对机器译文的人工评分[40] .他将机 器翻译自动评测任务看作复述识别,即对比机器译 文与参考译文之间的词汇、句法信息的变化,因此特 征选择包括词干共现、WordNet 同义词集、动词语义 类等. Snover 基于其在 2006 年提出的 TER 评测指 标,融合了可调参数、形态学分析、同义词以及复述 之后,提出新的评测指标 TERp [41⁃42] .TERp 不但将参 考译文和机器译文字面相同的片段匹配,还将有相 同词干或同义词的片段匹配.TERp 保留了 TER 的 编辑操作———匹配、插入、删除、替换、移动,还增加 了词干匹配、同义词匹配、短语替换,使评价结果与 人工评价的一致性更高. Pado 将文本蕴含( textual entailment) 用在机器 翻译的评测中[43] .蕴含被定义为一个前提 P( prem⁃ ise)和一个假设 H( hypothesis)之间的二元关系,即 若已知前提 P 成立可以推出 H 为真,则说 P 蕴含 H. 研究者一般将复述看作蕴含的特例,因为复述是双 向的,而蕴含的推理是单向的. 举例说明:设 P 为 “ Jane is a French teacher”, H 为 “ Jane can speak French”,则 P 蕴含 H,H 可从 P 中推理出来,相反 P 不一定能从 H 推理出来.Pado 认为好的机器译文与 参考译文是双向蕴含的,机器译文内容的缺失会破 坏正向蕴含,而机器译文内容的增添又会打破反向 蕴含,如果双向蕴含都不成立则认为翻译结果较差. 蕴含识别可以包含更多的语义和语法知识,利用蕴 含信息的“深度”匹配自然会优于简单的字面匹配 评测标准. 2 复述在统计机器翻译中的应用分析 复述作为人类语言中的一个普遍现象,受到自 然语言处理界学者的广泛关注.尤其在机器翻译领 域,在不同的阶段引入复述技术,在一定程度上改善 了翻译质量.鉴于前人的研究工作,将复述引入机器 翻译的不同阶段中,确实可以改善翻译结果.但在机 第 3 期 胡金铭,等:引入复述技术的统计机器翻译研究综述 ·203·