
Porter算法(1980) 每一步有一组上下文无关或有关的规则用来删 除后缀,或者将其转换为其它形式 ■上下文无关规则:sses→ss,ies→i,s→NULL ·上下文有关规则: (*v*):ed-→NULL,ing→NULL (*V)的含义是:词根必须包含一个元音 plastered->plaster bled→bled'删除词缀后,剩下的词干里没有元音 ·问题: ·需要大量的语言知识来定义规则 ·由于人类语言的复杂性,规则无法覆盖全部情况 ·规则依赖于语言
Porter算法 (1980) 每一步有一组上下文无关或有关的规则用来删 除后缀,或者将其转换为其它形式 上下文无关规则:sses → ss, ies → i, s → NULL 上下文有关规则: (*v*) : ed → NULL, ing → NULL (*v*)的含义是:词根必须包含一个元音 plastered → plaster bled → bled 删除词缀后,剩下的词干里没有元音 问题: 需要大量的语言知识来定义规则 由于人类语言的复杂性,规则无法覆盖全部情况 规则依赖于语言

后继变化数Successor Variety 基于对文本集合的统计分析 ·给定一个足够大的语料库,可以通过统计的方法获得词干 ■这种方法是自动的,和语言关联性不大的 后继变化数的定义: ·语料库中跟在某个字符串后的不同字符的数 ■考虑英文词典 ·pr?->后继变化数是多少? ·pro?->? ·pr和pro谁更像一个词根? ·直觉:如果一个字符串的后继变化数值很低,则可能是一个 词根
后继变化数Successor Variety 基于对文本集合的统计分析 给定一个足够大的语料库, 可以通过统计的方法获得词干 这种方法是自动的,和语言关联性不大的 后继变化数的定义: 语料库中跟在某个字符串后的不同字符的数 考虑英文词典 pr? -> 后继变化数是多少? pro? -> ? pr 和 pro 谁更像一个词根? 直觉:如果一个字符串的后继变化数值很低,则可能是一个 词根
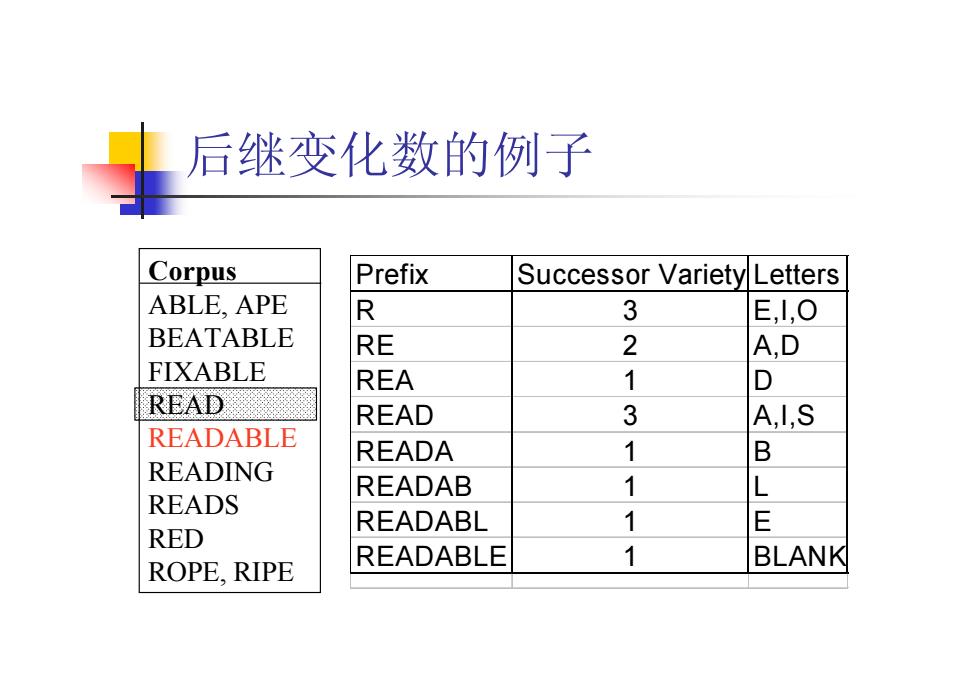
后继变化数的例子 Corpus Prefix Successor Variety Letters ABLE,APE R 3 E,l,0 BEATABLE RE 2 A,D FIXABLE REA 1 D READ READ 3 A,I,S READABLE READA 1 B READING READAB 1 L READS READABL 1 E RED READABLE 1 ROPE,RIPE BLANK
后继变化数的例子 Prefix Successor Variety Letters R 3 E,I,O RE 2 A,D REA 1 D READ 3 A,I,S READA 1 B READAB 1 L READABL 1 E READABLE 1 BLANK Corpus ABLE, APE BEATABLE FIXABLE READ READABLE READING READS RED ROPE, RIPE

切分 ■使用后继变化数信息切分词 ■cut off ·通过后继变化数的cutoff值识别边界 ▣当后继变化数>=阈值时,进行切分 ■考虑阈值=2 RIEIADIABLE ■尖峰和高地 ·在后继变化数比前后都大,出现尖峰的位置切开 READIABLE ■切出来的词必须完整 I如:READ
切分 使用后继变化数信息切分词 cut off 通过后继变化数的cutoff值识别边界 当后继变化数>=阈值时,进行切分 考虑阈值 = 2 R|E|AD|ABLE 尖峰和高地 在后继变化数比前后都大,出现尖峰的位置切开 READ|ABLE 切出来的词必须完整 如:READ

其它term处理 ■英文词形态还原 Calculated,Calculating -Calculate ·Went->go,goes->go ■中文分词 ·举例 ■“他将来北京” 。“研究生命的起源” 。英文有没有分词问题? ■有,例如“give in”(投降),必须分词
其它term处理 英文词形态还原 Calculated, Calculating -> Calculate Went->go, goes->go 中文分词 举例 “他将来北京” “研究生命的起源” 英文有没有分词问题? 有,例如“give in”(投降),必须分词