
Stemming 克服词形的变化,把所有同根词转变为单一形式 RECOGNIZE,RECOGNISE,RECOGNIZED,RECOGNIZATION Stemming的优点: 。减少不同term的数量 ·识别相似的词 ·改进了检索性能,但不采用语言分析的方法 ■Stemming的缺点: ■正确率显然达不到100% ·不正确的stemming算法可能改变词的含义 ■需要避免过分的截断 ■MEDICAL和MEDIA被识别为MED*,并被认为是意义相近的,这就 错了
Stemming 克服词形的变化,把所有同根词转变为单一形式 RECOGNIZE, RECOGNISE, RECOGNIZED, RECOGNIZATION Stemming的优点: 减少不同term的数量 识别相似的词 改进了检索性能,但不采用语言分析的方法 Stemming的缺点: 正确率显然达不到100% 不正确的stemming算法可能改变词的含义 需要避免过分的截断 MEDICAL和MEDIA被识别为MED*,并被认为是意义相近的,这就 错了
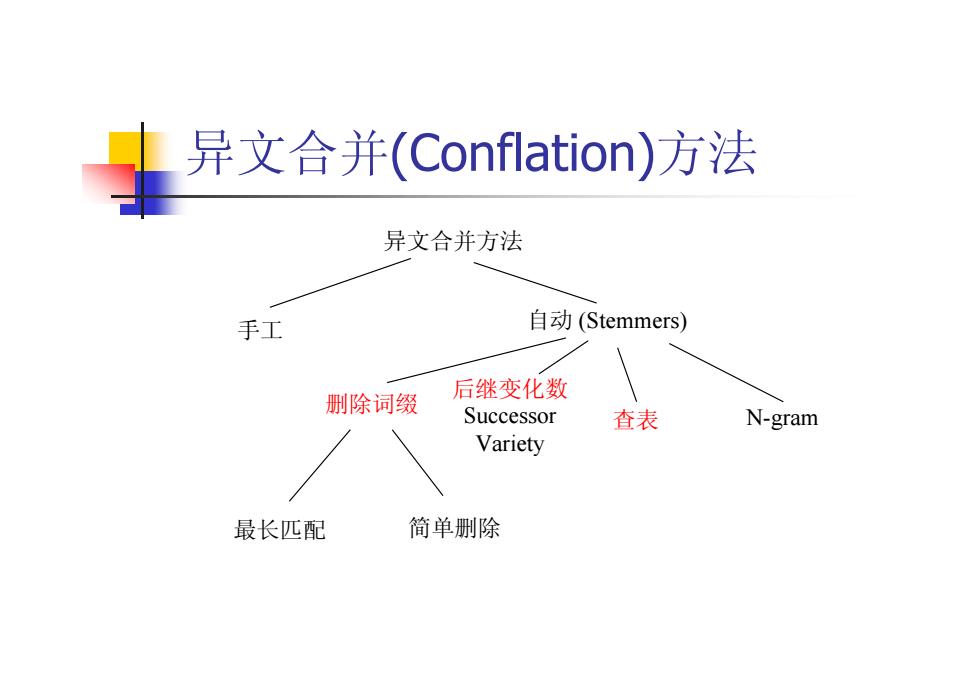
异文合并(Conflation)方法 异文合并方法 手工 自动(Stemmers) 删除词缀 后继变化数 Successor 查表 N-gram Variety 最长匹配 简单删除
异文合并(Conflation)方法 异文合并方法 手工 自动 (Stemmers) 删除词缀 后继变化数 Successor Variety 查表 N-gram 最长匹配 简单删除

查表 ■创建一个term和stem的对应表 TERM STEM engineering engineer engineered engineer engineer engineer ■表可以被索引起来,以便加快查找速度 ■创建这样的表很困难 ■存储空间的开销较大
查表 创建一个term和stem的对应表 表可以被索引起来,以便加快查找速度 创建这样的表很困难 存储空间的开销较大 TERM STEM engineering engineer engineered engineer engineer engineer

词缀删除算法 词缀删除算法将term的前缀和/或后缀删除,留 下词干 ■大多数算法删除后缀,例如:-SES,-ATION, ING等等 ■最长匹配 ■从词中删除最长匹配的后缀: computability-->comput singing-->sing avoid:ability->NULL,sing->s ▣迭代式最长匹配 。重复最长匹配的过程: ·WILLINGNESS->删除NESS->删除ING
词缀删除算法 词缀删除算法将term的前缀和 /或后缀删除,留 下词干 大多数算法删除后缀,例如:-SES, -ATION, - ING等等 最长匹配 从词中删除最长匹配的后缀: computability --> comput singing --> sing avoid: ability ->NULL, sing->s 迭代式最长匹配 重复最长匹配的过程: WILLINGNESS --> 删除NESS --> 删除ING

上下文有关和上下文无关 ■上下文无关 ·根据后缀表删除后缀(或基于规则集) ■上下文有关 ■考虑词的其它性质,例如: .happily→happi-→happy ·定义一个上下文敏感的转换规则:如果一个词根以结尾,ⅰ 前面是p,那么将转换为y ■需要控制许多例外规则 ·从TABLE中删除-ABLE不行,从GAS中删除-S也不行 ·有时需要删除“双写字母” ·FORGETTING→FORGET
上下文有关和上下文无关 上下文无关 根据后缀表删除后缀 (或基于规则集 ) 上下文有关 考虑词的其它性质,例如: happily → happi → happy 定义一个上下文敏感的转换规则:如果一个词根以i结尾,i 前面是 p,那么将i转换为 y 需要控制许多例外规则 从TABLE中删除-ABLE不行,从GAS中删除-S也不行 有时需要删除 “双写字母 ” FORGETTING → FORGET