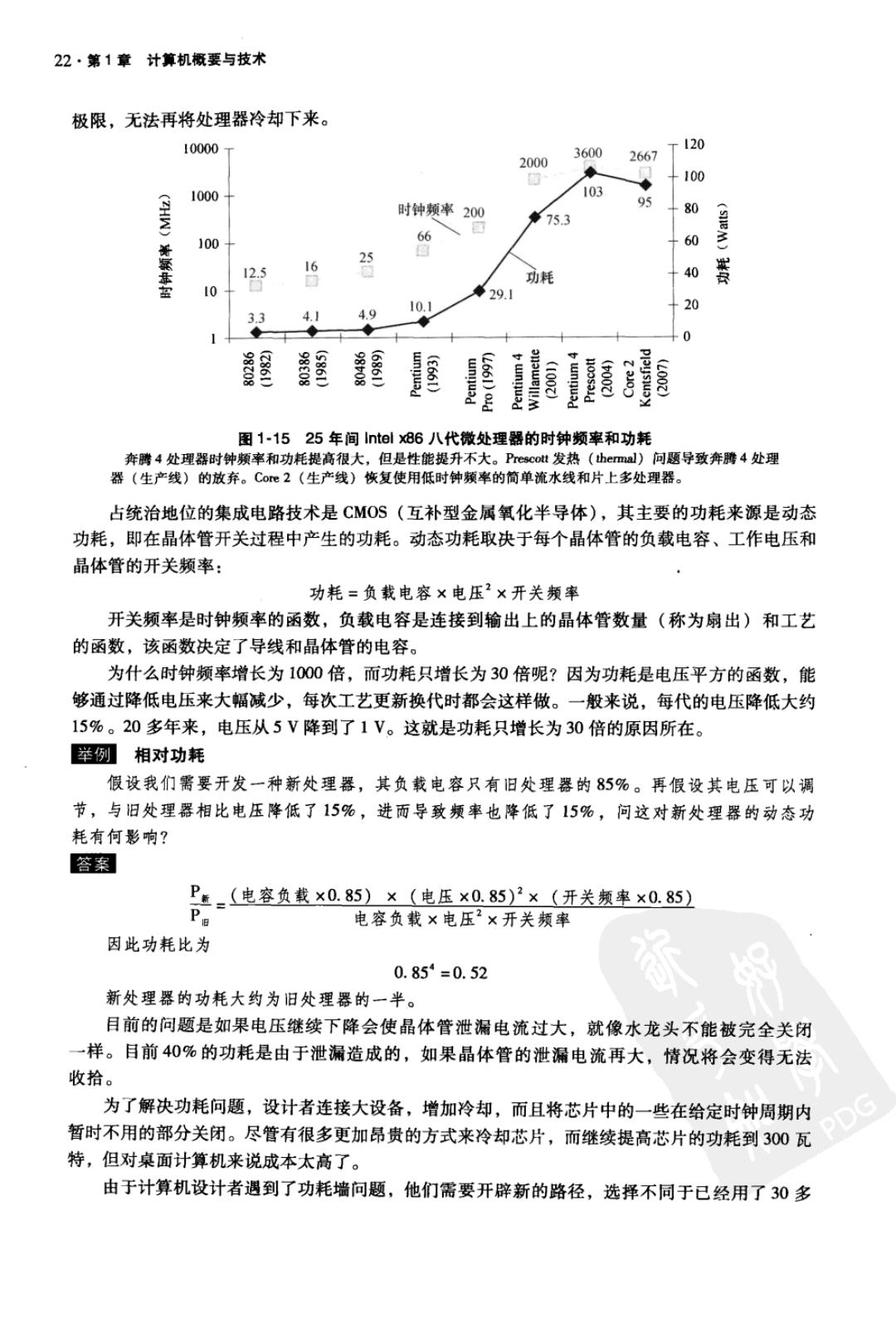
22·第1章计算机概要与技术 极限,无法再将处理器冷却下来。 10000T 120 3600 2000 2667 100 1000 103 时钟频率200 95 摩75.3 80 100 66 60 女 25 16 垂 12.5 功耗 40 罴 10 ●29.1 10.1 20 3.3 4.9 -0 1000 图1-1525年间Intel86八代微处理器的时钟频率和功耗 奔腾4处理器时钟频率和功耗提高很大,但是性能提升不大。Prescott发热(thermal)问题导致奔腾4处理 器(生产线)的放弃。Co心2(生产线)恢复使用低时钟频率的简单流水线和片上多处理器。 占统治地位的集成电路技术是CMOS(互补型金属氧化半导体),其主要的功耗来源是动态 功耗,即在晶体管开关过程中产生的功耗。动态功耗取决于每个晶体管的负载电容、工作电压和 晶体管的开关频率: 功耗=负载电容×电压2×开关频率 开关频率是时钟频率的函数,负载电容是连接到输出上的晶体管数量(称为扇出)和工艺 的函数,该函数决定了导线和晶体管的电容。 为什么时钟频率增长为1000倍,而功耗只增长为30倍呢?因为功耗是电压平方的函数,能 够通过降低电压来大幅减少,每次工艺更新换代时都会这样做。一般来说,每代的电压降低大约 15%。20多年来,电压从5V降到了1V。这就是功耗只增长为30倍的原因所在。 举例相对功耗 假设我们需要开发一种新处理器,其负载电容只有旧处理器的85%。再假设其电压可以调 节,与旧处理器相比电压降低了15%,进面导致频率也降低了15%,问这对新处理器的动态功 耗有何影响? 答案 P=(电容负载×0.85)×(电压×0.85)'×(开关频率×0.85) 电容负载×电压2×开关频率 因此功耗比为 0.85=0.52 新处理器的功耗大约为旧处理器的一半。 目前的问题是如果电压继续下降会使晶体管泄漏电流过大,就像水龙头不能被完全关闭 一样。目前40%的功耗是由于泄漏造成的,如果晶体管的泄漏电流再大,情况将会变得无法 收拾。 为了解决功耗问题,设计者连接大设备,增加冷却,而且将芯片中的一些在给定时钟周期内 暂时不用的部分关闭。尽管有很多更加昂贵的方式来冷却芯片,而继续提高芯片的功耗到300瓦 特,但对桌面计算机来说成本太高了。 由于计算机设计者遇到了功耗墙问题,他们需要开辟新的路径,选择不同于已经用了30多

第1章计算机概要与技术·23 年的方法继续前进。 精解:虽然动态功耗是CMOS功耗的主要来源,但静态功耗也是存在的。因为即使在晶体管关闭的情 况下,还是有泄漏电流存在。2008年时典型的电流泄漏占40%的功耗。因此,增加晶体管的数目,就会增 加漏电功耗,即使这些晶体管总是关闭的。各种各样的设计和工艺创新被用来控制电流泄漏,但还是难以 进一步降低电压。 1.6沧海巨变:从单处理器向多处理器转变 迄今为止,很多软件很像独唱编写者所写的音乐;使用当代的芯片,我们对于编写二重唱、 四重唱,以及小型的合奏具有少量的经验,但是为大型交响乐或者合唱谱曲则是一个不同的 挑战。 一Brian Hayes,《并行领域的计算》,2007 功耗的极限迫使微处理器的设计产生了巨变。图1-16给出了桌面微处理器的程序响应时间 的发展。从2002年起,其每年的增长速率从1.5下降到不足1.2。 10000 Intel Xeon.GHz 64-bit Intel Xz AMD0品C装s45764 Intel Pentium 4.3.0 GHz AMD Athlon,1.6 GHz 4195 Intel Pentium IIL,1.0 GHz 2584 Alpha 21264A.0.7 GHz1779 1000 Alpha 21264,0.6 GHz 1267 Alpha 214.0 G 993 Alpha 21164.0.5 GHz -481 Apia2I164,0.3GH280 Apha21064A.0.3GH83 =20% PowerPC 604.0.1GHz17 Alpha 21064.0 G HP PA-RISC,0.05 GHz 51 1BMRS6000/54024 52%/年 MIPS M200018 10 MIPS M/12013 Sun-4/2609 VAX87005 VAX-11/780. 25%/年5,VAX-11/785 01978 1980 19821984 1986 1988199019921994199619982000200220042006 图1-16自20世纪80年代中期以来处理器性能的发展 本图描绘了和VAX1l/780相比,采用SPECint测试程序得到的性能数据(见1.8节)。在20世纪80年代 中期以前,性能的增长主要靠技术驱动,平均每年增长25%。在这个阶段之后,增长速度达到52%,这些归 功于体系结构的创新和结构变化。到2002年,这种性能增长发生了变化,大约是7的因子(a factor of$v- e),面向浮点计算的性能大幅度增长。从2002年开始,受到功耗、指令级并行程度和长的存储器延迟的限 制,单核处理器的性能增长放缓,大约每年20%。 在2006年,所有桌面和服务器公司都在单片微处理器中加入了多个处理器,以求更大的吞 吐率,而不再继续追求降低单个程序运行在单个处理器上的响应时间。为了减少processor和mi- croprocessor(微处理器)这两个词语之间的混淆,一些公司将processor作为“cores”的代称, ●G 这样的微处理器(microprocessor)就是多核处理器了。因此,一个“四核”微处理器是一个芯 片,包含了4个processor或者4个core。 图1-17给出了最近微处理器中核的数目、功耗和时钟频率。在许多公司宣布的产品计划中

24·第1章计算机概要与技术 核的数目大约每2年将会翻一番(见第7章)。 AMD Sun 产品 Opteron X4 Intel Nehalem IBM Power 6 Ultra SPARC T2 (Barcelona) (Niagara 2) 每片核数 4 4 2 8 时钟频率 2.5 GHz 约2.5GHz 4.7 GHz 1.4 GHz 微处理器的功耗 120W 约100W 约100W 94W 图1-172008年多核微处理器每芯片的核数、时钟频率和功耗 在过去,程序员可以依赖于硬件、体系结构和编译程序的创新,无需修改一行代码,程序的 性能每18个月翻一番。而今天,程序员要想显著改进响应时间,必须重写他们的程序。而且, 随着核的数目不断加倍,程序员也必须不断改进他们的代码。 为了强调软件和硬件系统的协同工作,我们在本书用“硬件/软件接口”的概念来进行描 述,并对这一接口概括一些重要的观点,下面是本书中的第一个。 硬件软件接口 并行性对计算性能一直十分重要,但它往往是隐蔽的。第4章将说明流水线,它是一种漂亮 的技术,通过指令重叠执行使程序运行得更快。这是指令级并行性的一个例子。在抽取了硬件的 并行本质之后,程序员或编译程序可认为在硬件中指令是串行执行的。 迫使程序员意识到硬件的并行性,并显式地按并行方式重写其程序,曾经是计算机体系结 构的“第三抱怨”,以致很多采用此种方式进行革新的公司都失败了(见光盘上7.14节)。从历 史发展的角度来观察,整个T行业已经把它放到了未来的发展方向上,程序员最终将成功地跃 进到显式并行编程。 为什么程序员编写显式并行程序如此困难呢?第一个原因是并行编程以提高性能为目的, 必然增加编程的难度。不仅程序必须要正确,能够解决重要问题,而且运行速度要快,还需要为 用户或其他程序提供接口以便使用,否则编写一个串行程序就足够了。 第二个原因是为了发挥并行硬件的速度,程序员必须将应用划分为每个核大致相同数量的 任务,并同时完成。还要尽可能减小调度的开销,以不至于把并行的性能都浪费掉。 作一个比喻,现在有一个写新闻故事的任务,如果由8名记者共同来完成,能否提高8倍的 写作速度呢?为了实现这一目标,这个新闻故事需要进行划分,让每个记者都有事可做。假如某 名记者分到的任务比其他7名记者加起来的任务还要多,那用8名记者的好处就不存在了。因 此,任务分配必须平衡才能得到理想的加速。另一个存在的危险是记者要花费时间互相交流才 能完成所分配的任务。如果故事的一部分,例如结论,在所有其他部分完成之前不能编写,则你 缩短故事编写时间的计划将会失败。所以,必须尽量减少通信和同步的开销。对于本文的比喻和 并行编程来说,挑战包括:调度、负载平衡、通信以及同步等开销。你也许会想到,当更多的记 者来写一个故事,或是核的数目更多时,并行编程的挑战将更大。 为了反映业界的这个沧海巨变,后面的五章里每章都会有一节介绍有关并行性革命的内容: ·第2章,2.11节:并行与指令:同步。通常独立的并行任务需要一次次地协调,以便通 报它们何时完成了所分配的任务。本章将解释多核处理器任务同步所使用的指令。 ·第3章,3.6节:并行性和计算机算术:结合律。许多并行程序员往往从正在使用中的 串行程序开始。要确认他们的并行版程序是否能工作就要回答以下问题:是否和串行程 序得到了同样的结果?如果答案是否定的,那么并行版的新程序就存在错误。这个逻辑 假定计算机运算是遵守结合律的:将一百万个数相加,无论次序如何,得到的和是相同 的。本章将解释该逻辑对整数是成立的,但对浮点数并不成立

第1章计算机概要与技术·25 ·第4章,4.10节:并行和高级指令级并行。尽管明确地知道并行编程的困难,在20世纪 90年代依然付出了巨大的努力和投资用于研究硬件和编译程序的并行性。本章描述了其 中的一些技术,包括取指与多指令同时执行和推测决策结果、指令执行等。 ·第5章,5.8节:并行与存储器层次结构:cache一致性。降低通信开销的一个方法是让 所有处理器使用同一个地址空间,任何处理器可以读写任何数据。今天的计算机都采用 cace技术,即在处理器附近更快的存储器中,保持数据的一个临时复制。可以想象,如 果多个处理器访问cache中的共享数据不一致的话,并行编程将尤为困难。本章将介绍 保持所有cache数据一致性的机制。 ·第6章,6.9节:并行性与/O:廉价磁盘冗余阵列(RAID)。如果你在并行性革命中忽 略了I/O,那么你的并行程序将在等待/O上浪费大量的时间。本章介绍的RAID技术, 可以加速外存访问的速度,这体现了并行性的另一个优点:利用资源的多个复制,即使 有一个复制失效了,系统仍能继续工作。因此,RAD能同时改进/O性能和可用性。 除了这些章节之外,还有一整章介绍并行编程。第7章详细叙述了并行编程的挑战性;提出 了两种方法来解决共享编址通信和显式消息传输;介绍了一种易于编程的并行性模型;讨论了 使用基准测试程序对并行处理器进行评测的困难;为多核微处理器引入了一个新的简单性能模 型;最后,描述和评价了四种使用该种模型的多核微处理器。 本书从这一版开始在附录A中介绍了GPU(graphics processing unit)。GPU是一种在桌面计算 机中越来越普及的图形处理器,它是为加速图像处理而发明的。得益于高度的并行性,GPU表现出 了优越的性能,并已发展为完善的编程平台。附录A介绍了NVIDIA GPU及其并行编程环境。 1.7实例:制造以及AMD Opteron X4基准 我想,就像书一样,“计算机”是一个全世界广泛应用的概念。但我没有想到它会发展得如 此迅速,因为我完全没有预料到我们在一块芯片上可以得到像我们最终得到的如此多的部件。 晶体管的进步完全出乎我们的预料。它比我们预想的发展要快。 一J.Presper Eckert,ENIAC的创建者之一,言论发表于I991 本书的每一章都有“实例”一节,它将本书中的概念与我们日常使用的计算机联系起来, 这些小节涵盖了现代计算机中使用到的技术。下面是本书中的第一个“实例”小节,我们将以 AMD Opteron X4为例,说明如何制造集成电路,以及如何测量性能和功耗。 芯片的制造从硅开始。硅是从沙子中发现的一种物质。由于它导电性能不好,所以称为半 导体·。用特殊的化学方法对硅添加某些材料,可以把其细微的区域转变为以下三种类型之一: ·良好的导电体(类似于细微的铜线或铝线) ·良好的绝缘体(类似于塑料或玻璃膜) ·可控的导电体或绝缘体(类似开关) 晶体管属于第三种。VLSI电路是由数亿个上述三种材料组合起来并封装在一起所制成的。 集成电路的制造过程对决定芯片的价格非常关键,因此对计算机设计者十分重要。图118 表示了集成电路制造的整个过程。集成电路的制造是从硅锭开始的,它像一根巨大的香肠。目 前使用的硅锭直径约8~12英寸,长度约12~24英寸。硅锭经切片机切成片厚度不超过0.1英 寸的晶圆°。这些晶圆经过大约20~40步化学加工最终产生之前所讨论的晶体管、导体和绝缘 曰硅(silicon):一种自然元素,它是一种半导体。 PDG 已半导体(semiconductor):一种导电性能不好的物质。 自硅锭(silicon crystal ingot):一块由硅晶体组成的棒。直径大约在8-12英寸,长度约12-24英寸。 )晶圆(wafer):厚度不超过O.1英寸的硅锭片,被用来制造芯片
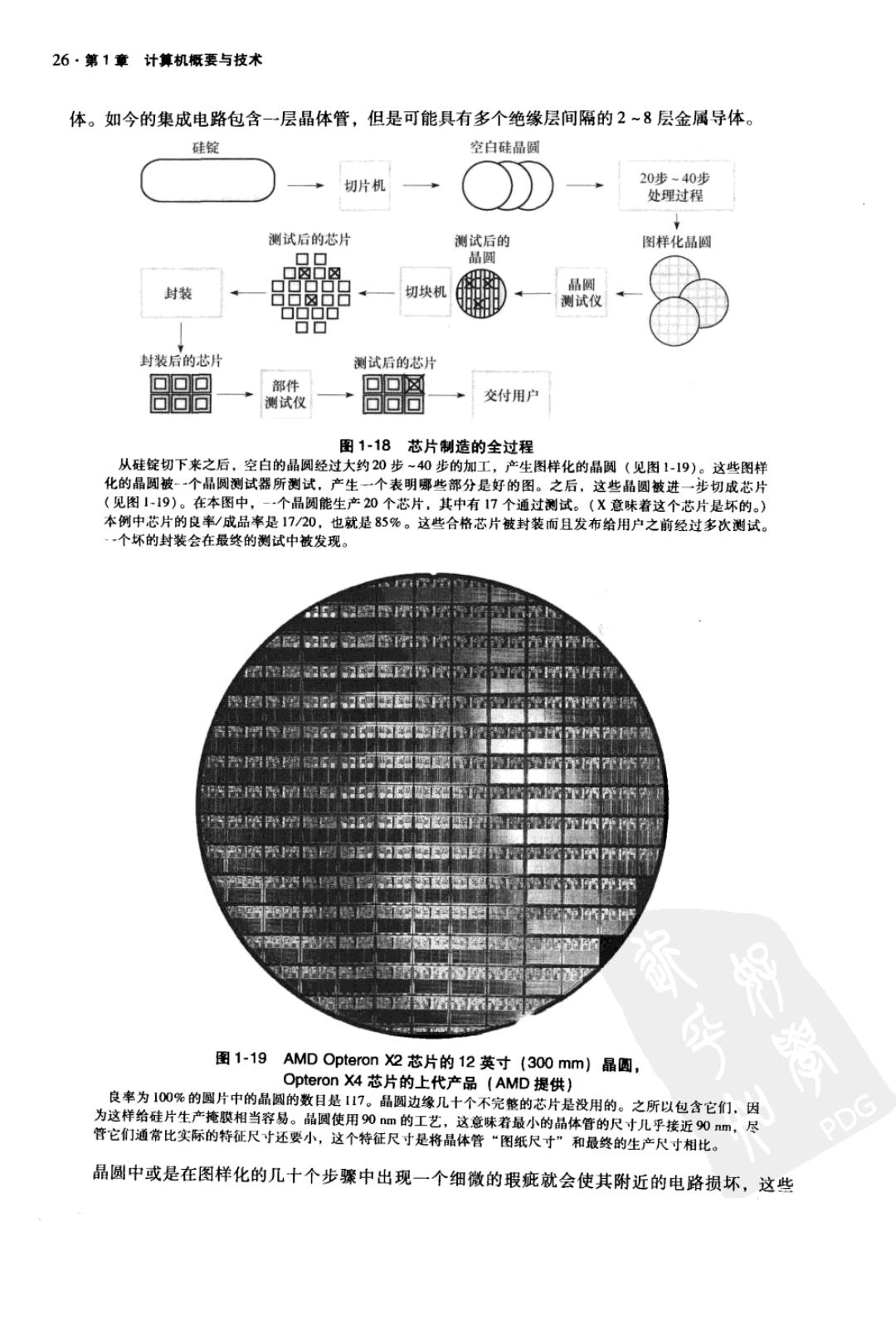
26·第1章计算机概要与技术 体。如今的集成电路包含一层晶体管,但是可能具有多个绝缘层间隔的2~8层金属导体。 硅锭 空白硅晶圆 切片机 20步~40步 处理过程 测试后的芯片 测试后的 图样化晶圆 ▣▣ 品圆 ▣☒▣☒ 封装 切块机 品圆 测试仪 ▣OO口 ▣▣ 封装后的芯片 测试后的芯片 ▣▣▣ 部件 ▣▣网 ▣▣ 测试仪 ▣▣▣ 交付用户 图1-18芯片制造的全过程 从硅锭切下来之后,空白的晶圆经过大约20步~40步的加工,产生图样化的晶圆(见图119)。这些图样 化的晶圆被-个晶圆测试器所测试,产生一个表明哪些部分是好的图。之后,这些品圆被进一步切成芯片 (见图119)。在本图中,-一个晶圆能生产20个芯片,其中有17个通过测试。(X意味着这个芯片是坏的) 本例中芯片的良率/成品率是17/20,也就是85%。这些合格芯片被封装而且发布给用户之前经过多次测试。 一个坏的封装会在最终的测试中被发现。 图1-19 AMD Opteron2芯片的12英寸(300mm)晶圆, 还尝心 Opteron X4芯片的上代产品(AMD提供) 良率为100%的圆片中的晶圆的数目是17。晶圆边缘几十个不完整的芯片是没用的。之所以包含它们,因 为这样给硅片生产掩膜相当容易。晶圆使用90m的工艺,这意味着最小的品体管的尺寸儿乎接近90nm,尽 管它们通常比实际的特征尺寸还要小,这个特征尺寸是将晶体管“图纸尺寸”和最终的生产尺寸相比。 PDG 晶圆中或是在图样化的几十个步骤中出现一个细微的瑕疵就会使其附近的电路损坏,这些