
7.2.1基于统计语言模型的分词方法(3/10) 方法描述: 设对于待切分的句子S,W=ww2.Wk (1≤k≤n)是一种可能的切分。 W*=argmax P(WIS) (7-1) arg max P(W)P(SW) (7-3) W 微软研究院把一个可能的词序列W转换成 一个可能的词类序列C=CC2cw,即:
◼ 方法描述: 7.2.1 基于统计语言模型的分词方法(3/10)
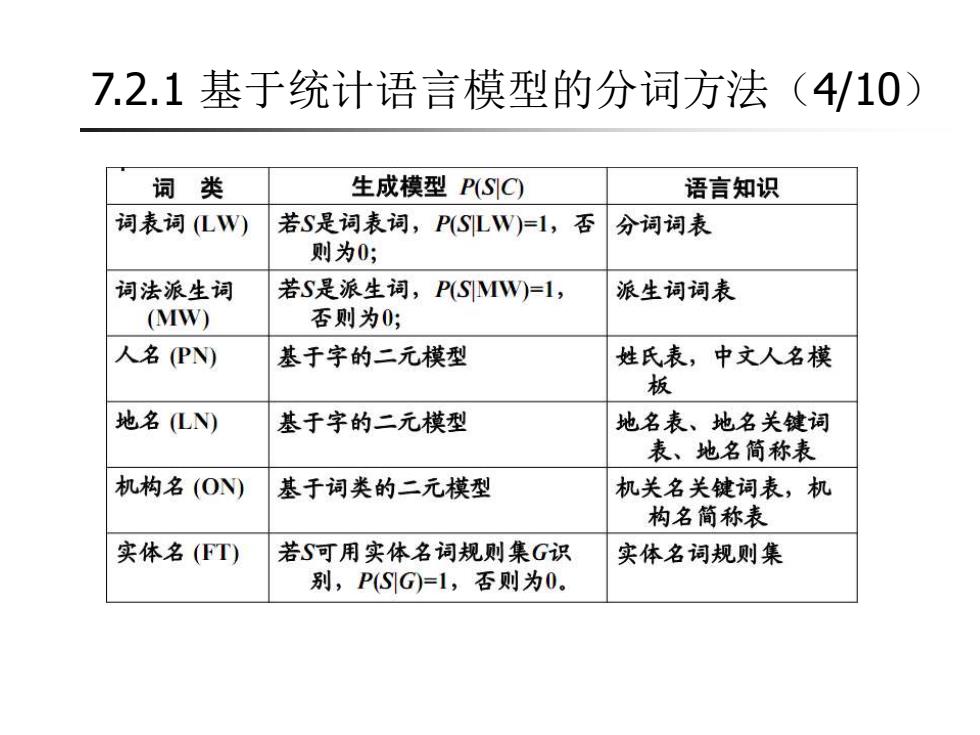
7.2.1基于统计语言模型的分词方法(4/10) 词类 生成模型PSC) 语言知识 词表词(LW) 若S是词表词,PSLW)=1,否 分词词表 则为0; 词法派生词 若S是派生词,P(SMW)=l, 派生词词表 (MW) 否则为0; 人名(PN) 基于字的二元模型 姓氏表,中文人名模 板 地名(LN) 基于字的二元模型 地名表、地名关键词 表、地名简称表 机构名(ON) 基于词类的二元模型 机关名关键词表,机 构名简称表 实体名(FT) 若S可用实体名词规则集G识 实体名词规则集 别,PSG)=1,否则为0
7.2.1 基于统计语言模型的分词方法(4/10)

7.2.1基于统计语言模型的分词方法(5/10) 那么, C'=arg max(P(C P(SIC (7-4) 语言模型 生成模型 P(C可采用3元语法: 语句s=w1W2…wm的先验概率: P(s)=P(W)X P(w2lW )X P(w3lw w2)X... XP(wmw1.wm-l) =ΠP(gg…g) ..(5.1)
三元模型的参数可以通过在最大似然估计 在一个带有词类别标记的训练语料上计 算,并采用回退平滑算法解决数据稀疏 问题。 7.2.1 基于统计语言模型的分词方法(5/10)

7.2.1基于统计语言模型的分词方法(6/10) 生成模型在满足独立性假设的条件下,可近似为: P(S1C)≈ΠP(sc) (7-6) 该公式的含义是,任意一个词类生成汉字串的概 率只与自身有关,而与其上下文无关。例如,如 果“教授”是词表词,Ps教授c,LW=l
生成模型在满足独立性假设的条件下,可近似为: 该公式的含义是,任意一个词类生成汉字串的概 率只与自身有关,而与其上下文无关。例如,如 果“教授”是词表词,则 7.2.1 基于统计语言模型的分词方法(6/10)

7.2.1基于统计语言模型的分词方法(7/10) 模型的训练由以下三步组成: (1)在词表和派生词表的基础上,用正向最大匹配法切分 训练语料,专有名词通过一个专门模块标注,实体名词 通过相应的规则和有限状态自动机标注,由此产生一个 带词类别标记的初始语料; (2)用带词类别标记的初始语料,采用最大似然估计方法 估计语言模型的概率参数; (3)用语言模型(公式(7-1)、(7-2)、(7-3)),对训练 语料重新切分和标注,得到新的训练语料; (4)重复(2)(3)步,直到系统的性能不再有明显的变化
7.2.1 基于统计语言模型的分词方法(7/10)