
knn.fit(X_train,y_train) print("Test set score:{:.2f]".format(knn.score(X_test,y_test))) 0ut[32]: Test set score:0.97 这个代码片段包含了应用scikit-Learn中任何机器学习算法的核心代码。fit、predict和 score方法是scikit-learn监督学习模型中最常用的接口。学完本章介绍的概念,你可以 将这些模型应用到许多机器学习任务上。下一章,我们会更深入地介绍scikit-learn中各 种类型的监督学习模型,以及这些模型的正确使用方法。 20|第1章 图灵社区会员zhugeln(499702878@qq.com)专享尊重版权
20 | 第 1 章 knn.fit(X_train, y_train) print("Test set score: {:.2f}".format(knn.score(X_test, y_test))) Out[32]: Test set score: 0.97 这个代码片段包含了应用 scikit-learn 中任何机器学习算法的核心代码。fit、predict 和 score 方法是 scikit-learn 监督学习模型中最常用的接口。学完本章介绍的概念,你可以 将这些模型应用到许多机器学习任务上。下一章,我们会更深入地介绍 scikit-learn 中各 种类型的监督学习模型,以及这些模型的正确使用方法。 图灵社区会员 zhugeln(499702878@qq.com) 专享 尊重版权

书籍下载gg群6089740钉钉群21734177 IT书籍http:/t.cn/RDIAj5D 第2章 监督学习 前面说过,监督学习是最常用也是最成功的机器学习类型之一。本章将会详细介绍监督学 习,并解释几种常用的监督学习算法。我们在第1章已经见过一个监督学习的应用:利用 物理测量数据将鸢尾花分成几个品种。 记住,每当想要根据给定输入预测某个结果,并且还有输入/输出对的示例时,都应该使 用监督学习。这些输入/输出对构成了训练集,我们利用它来构建机器学习模型。我们的 目标是对从未见过的新数据做出准确预测。监督学习通常需要人力来构建训练集,但之后 的任务本来非常费力甚至无法完成,现在却可以自动完成,通常速度也更快。 2.1分类与回归 监督机器学习问题主要有两种,分别叫作分类(classification)与回归(regression)。 分类问题的目标是预测类别标签(class label),这些标签来自预定义的可选列表。第1 章讲过一个例子,即将鸢尾花分到三个可能的品种之一。分类问题有时可分为二分类 (binary classification,在两个类别之间进行区分的一种特殊情况)和多分类(multiclass classification,在两个以上的类别之间进行区分)。你可以将二分类看作是尝试回答一道是/ 否问题。将电子邮件分为垃圾邮件和非垃圾邮件就是二分类问题的实例。在这个二分类任 务中,要问的是/否问题为:“这封电子邮件是垃圾邮件吗?” 在二分类问题中,我们通常将其中一个类别称为正类(positive class),另一个类别称为反 类(negative class)。这里的“正”并不代表好的方面或正数,而是代表研究对象。因此在 寻找垃圾邮件时,“正”可能指的是垃圾邮件这一类别。将两个类别中的哪一个作为“正 类”,往往是主观判断,与具体的领域有关。 另一方面,鸢尾花的例子则属于多分类问题。另一个多分类的例子是根据网站上的文本预 21 电子书寻找看手相钉钉或微信pythontesting
第 2 章 监督学习 前面说过,监督学习是最常用也是最成功的机器学习类型之一。本章将会详细介绍监督学 习,并解释几种常用的监督学习算法。我们在第 1 章已经见过一个监督学习的应用:利用 物理测量数据将鸢尾花分成几个品种。 记住,每当想要根据给定输入预测某个结果,并且还有输入 / 输出对的示例时,都应该使 用监督学习。这些输入 / 输出对构成了训练集,我们利用它来构建机器学习模型。我们的 目标是对从未见过的新数据做出准确预测。监督学习通常需要人力来构建训练集,但之后 的任务本来非常费力甚至无法完成,现在却可以自动完成,通常速度也更快。 2.1 分类与回归 监督机器学习问题主要有两种,分别叫作分类(classification)与回归(regression)。 分类问题的目标是预测类别标签(class label),这些标签来自预定义的可选列表。第 1 章讲过一个例子,即将鸢尾花分到三个可能的品种之一。分类问题有时可分为二分类 (binary classification,在两个类别之间进行区分的一种特殊情况)和多分类(multiclass classification,在两个以上的类别之间进行区分)。你可以将二分类看作是尝试回答一道是 / 否问题。将电子邮件分为垃圾邮件和非垃圾邮件就是二分类问题的实例。在这个二分类任 务中,要问的是 / 否问题为:“这封电子邮件是垃圾邮件吗?” 在二分类问题中,我们通常将其中一个类别称为正类(positive class),另一个类别称为反 类(negative class)。这里的“正”并不代表好的方面或正数,而是代表研究对象。因此在 寻找垃圾邮件时,“正”可能指的是垃圾邮件这一类别。将两个类别中的哪一个作为“正 类”,往往是主观判断,与具体的领域有关。 另一方面,鸢尾花的例子则属于多分类问题。另一个多分类的例子是根据网站上的文本预 21 书籍下载qq群6089740 钉钉群21734177 IT书籍 http://t.cn/RDIAj5D 电子书寻找看手相 钉钉或微信pythontesting

测网站所用的语言。这里的类别就是预定义的语言列表。 回归任务的目标是预测一个连续值,编程术语叫作浮点数(floating-point number),数学术 语叫作实数(real number)。根据教育水平、年龄和居住地来预测一个人的年收入,这就是 回归的一个例子。在预测收入时,预测值是一个金额(amount),可以在给定范围内任意 取值。回归任务的另一个例子是,根据上一年的产量、天气和农场员工数等属性来预测玉 米农场的产量。同样,产量也可以取任意数值。 区分分类任务和回归任务有一个简单方法,就是问一个问题:输出是否具有某种连续性。 如果在可能的结果之间具有连续性,那么它就是一个回归问题。想想预测年收入的例子。 输出具有非常明显的连续性。一年赚40000美元还是40001美元并没有实质差别,即使 两者金额不同。如果我们的算法在本应预测40000美元时的预测结果是39999美元或 40001美元,不必过分在意。 与此相反,对于识别网站语言的任务(这是一个分类问题)来说,并不存在程度问题。网 站使用的要么是这种语言,要么是那种语言。在语言之间不存在连续性,在英语和法语之 间不存在其他语言。1 2.2 泛化、过拟合与欠拟合 在监督学习中,我们想要在训练数据上构建模型,然后能够对没见过的新数据(这些新数 据与训练集具有相同的特性)做出准确预测。如果一个模型能够对没见过的数据做出准确 预测,我们就说它能够从训练集泛化(generalize)到测试集。我们想要构建一个泛化精度 尽可能高的模型。 通常来说,我们构建模型,使其在训练集上能够做出谁确预测。如果训练集和测试集足够 相似,我们预计模型在测试集上也能做出准确预测。不过在某些情况下这一点并不成立。 例如,如果我们可以构建非常复杂的模型,那么在训练集上的精度可以想多高就多高。 为了说明这一点,我们来看一个虚构的例子。比如有一个新手数据科学家,已知之前船的 买家记录和对买船不感兴趣的顾客记录,想要预测某个顾客是否会买船。2目标是向可能购 买的人发送促销电子邮件,而不去打扰那些不感兴趣的顾客。 假设我们有顾客记录,如表2-1所示。 表2-1:顾客数据示例 年龄 拥有的小汽车数量 是否有房子 子女数量 婚姻状况 是否养狗 是否买过船 66 是 2 丧偶 否 是 52 是 已婚 否 是 22 0 分 0 已婚 是 否 25 否 1 单身 台 否 注1:请语言学家原谅我们将语言的表示方式简化为独特而又确定的实体。 注2:在现实世界中,这实际上是一个非常复杂的问题。虽然我们知道其他顾客还没有从我们这里买过船, 但他们可能已经在其他人那里买过了,或者仍在存钱并打算将来再买。 22 第2章
22 | 第 2 章 测网站所用的语言。这里的类别就是预定义的语言列表。 回归任务的目标是预测一个连续值,编程术语叫作浮点数(floating-point number),数学术 语叫作实数(real number)。根据教育水平、年龄和居住地来预测一个人的年收入,这就是 回归的一个例子。在预测收入时,预测值是一个金额(amount),可以在给定范围内任意 取值。回归任务的另一个例子是,根据上一年的产量、天气和农场员工数等属性来预测玉 米农场的产量。同样,产量也可以取任意数值。 区分分类任务和回归任务有一个简单方法,就是问一个问题:输出是否具有某种连续性。 如果在可能的结果之间具有连续性,那么它就是一个回归问题。想想预测年收入的例子。 输出具有非常明显的连续性。一年赚 40 000 美元还是 40 001 美元并没有实质差别,即使 两者金额不同。如果我们的算法在本应预测 40 000 美元时的预测结果是 39 999 美元或 40 001 美元,不必过分在意。 与此相反,对于识别网站语言的任务(这是一个分类问题)来说,并不存在程度问题。网 站使用的要么是这种语言,要么是那种语言。在语言之间不存在连续性,在英语和法语之 间不存在其他语言。1 2.2 泛化、过拟合与欠拟合 在监督学习中,我们想要在训练数据上构建模型,然后能够对没见过的新数据(这些新数 据与训练集具有相同的特性)做出准确预测。如果一个模型能够对没见过的数据做出准确 预测,我们就说它能够从训练集泛化(generalize)到测试集。我们想要构建一个泛化精度 尽可能高的模型。 通常来说,我们构建模型,使其在训练集上能够做出准确预测。如果训练集和测试集足够 相似,我们预计模型在测试集上也能做出准确预测。不过在某些情况下这一点并不成立。 例如,如果我们可以构建非常复杂的模型,那么在训练集上的精度可以想多高就多高。 为了说明这一点,我们来看一个虚构的例子。比如有一个新手数据科学家,已知之前船的 买家记录和对买船不感兴趣的顾客记录,想要预测某个顾客是否会买船。2 目标是向可能购 买的人发送促销电子邮件,而不去打扰那些不感兴趣的顾客。 假设我们有顾客记录,如表 2-1 所示。 表2-1:顾客数据示例 年龄 拥有的小汽车数量 是否有房子 子女数量 婚姻状况 是否养狗 是否买过船 66 1 是 2 丧偶 否 是 52 2 是 3 已婚 否 是 22 0 否 0 已婚 是 否 25 1 否 1 单身 否 否 注 1:请语言学家原谅我们将语言的表示方式简化为独特而又确定的实体。 注 2:在现实世界中,这实际上是一个非常复杂的问题。虽然我们知道其他顾客还没有从我们这里买过船, 但他们可能已经在其他人那里买过了,或者仍在存钱并打算将来再买
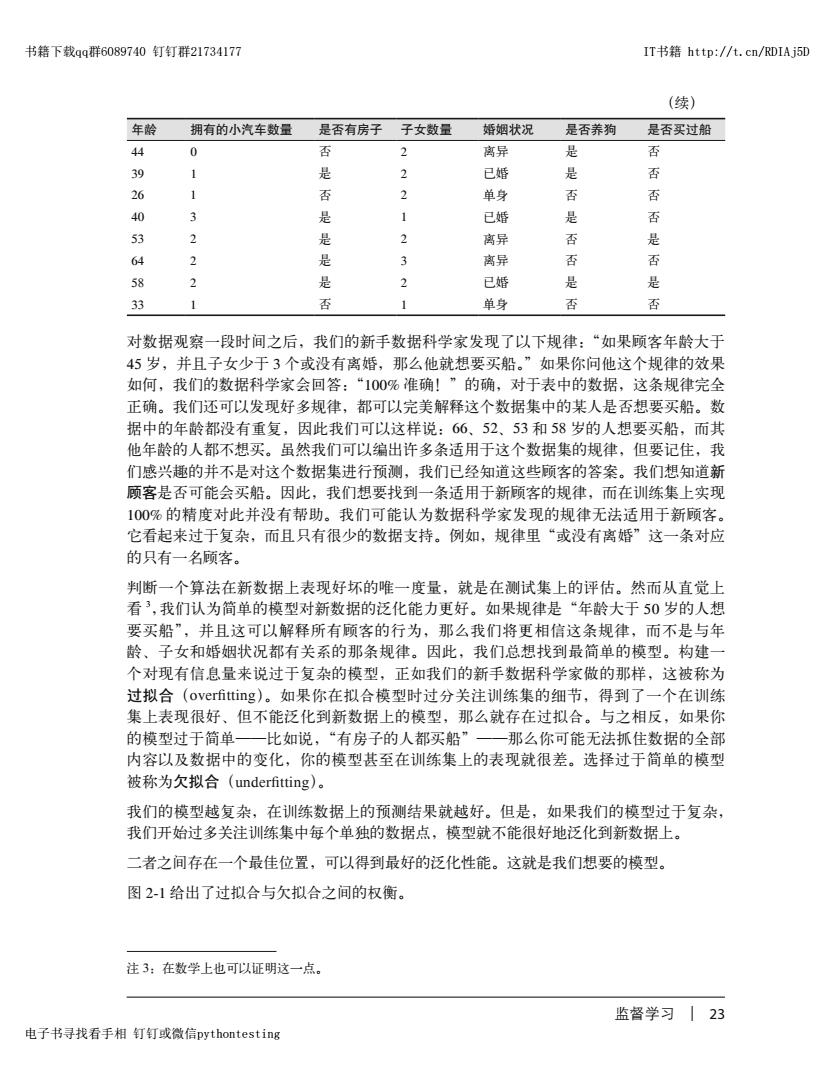
书籍下载qq群6089740钉钉群21734177 IT书籍http:/t.cn/RDIAj5D (续) 年龄 拥有的小汽车数量 是否有房子 子女数量 婚姻状况 是否养狗 是否买过船 44 0 否 2 离异 是 否 39 1 是 2 已婚 是 否 26 否 3 单身 否 否 40 3 是 已婚 是 否 53 2 是 3 离异 否 是 64 2 是 离异 否 否 58 2 是 2 已婚 是 是 33 1 否 1 单身 否 否 对数据观察一段时间之后,我们的新手数据科学家发现了以下规律:“如果顾客年龄大于 45岁,并且子女少于3个或没有离婚,那么他就想要买船。”如果你问他这个规律的效果 如何,我们的数据科学家会回答:“100%准确!”的确,对于表中的数据,这条规律完全 正确。我们还可以发现好多规律,都可以完美解释这个数据集中的某人是否想要买船。数 据中的年龄都没有重复,因此我们可以这样说:66、52、53和58岁的人想要买船,而其 他年龄的人都不想买。虽然我们可以编出许多条适用于这个数据集的规律,但要记住,我 们感兴趣的并不是对这个数据集进行预测,我们已经知道这些顾客的答案。我们想知道新 顾客是否可能会买船。因此,我们想要找到一条适用于新顾客的规律,而在训练集上实现 100%的精度对此并没有帮助。我们可能认为数据科学家发现的规律无法适用于新顾客。 它看起来过于复杂,而且只有很少的数据支持。例如,规律里“或没有离婚”这一条对应 的只有一名顾客。 判断一个算法在新数据上表现好坏的唯一度量,就是在测试集上的评估。然而从直觉上 看3,我们认为简单的模型对新数据的泛化能力更好。如果规律是“年龄大于50岁的人想 要买船”,并且这可以解释所有顾客的行为,那么我们将更相信这条规律,而不是与年 龄、子女和婚姻状况都有关系的那条规律。因此,我们总想找到最简单的模型。构建一 个对现有信息量来说过于复杂的模型,正如我们的新手数据科学家做的那样,这被称为 过拟合(overfitting)。如果你在拟合模型时过分关注训练集的细节,得到了一个在训练 集上表现很好、但不能泛化到新数据上的模型,那么就存在过拟合。与之相反,如果你 的模型过于简单一比如说,“有房子的人都买船”一那么你可能无法抓住数据的全部 内容以及数据中的变化,你的模型甚至在训练集上的表现就很差。选择过于简单的模型 被称为欠拟合(underfitting)。 我们的模型越复杂,在训练数据上的预测结果就越好。但是,如果我们的模型过于复杂, 我们开始过多关注训练集中每个单独的数据点,模型就不能很好地泛化到新数据上。 二者之间存在一个最佳位置,可以得到最好的泛化性能。这就是我们想要的模型。 图2-1给出了过拟合与欠拟合之间的权衡。 注3:在数学上也可以证明这一点。 监督学习23 电子书寻找看手相钉钉或微信pythontesting
监督学习 | 23 年龄 拥有的小汽车数量 是否有房子 子女数量 婚姻状况 是否养狗 是否买过船 44 0 否 2 离异 是 否 39 1 是 2 已婚 是 否 26 1 否 2 单身 否 否 40 3 是 1 已婚 是 否 53 2 是 2 离异 否 是 64 2 是 3 离异 否 否 58 2 是 2 已婚 是 是 33 1 否 1 单身 否 否 对数据观察一段时间之后,我们的新手数据科学家发现了以下规律:“如果顾客年龄大于 45 岁,并且子女少于 3 个或没有离婚,那么他就想要买船。”如果你问他这个规律的效果 如何,我们的数据科学家会回答:“100% 准确!”的确,对于表中的数据,这条规律完全 正确。我们还可以发现好多规律,都可以完美解释这个数据集中的某人是否想要买船。数 据中的年龄都没有重复,因此我们可以这样说:66、52、53 和 58 岁的人想要买船,而其 他年龄的人都不想买。虽然我们可以编出许多条适用于这个数据集的规律,但要记住,我 们感兴趣的并不是对这个数据集进行预测,我们已经知道这些顾客的答案。我们想知道新 顾客是否可能会买船。因此,我们想要找到一条适用于新顾客的规律,而在训练集上实现 100% 的精度对此并没有帮助。我们可能认为数据科学家发现的规律无法适用于新顾客。 它看起来过于复杂,而且只有很少的数据支持。例如,规律里“或没有离婚”这一条对应 的只有一名顾客。 判断一个算法在新数据上表现好坏的唯一度量,就是在测试集上的评估。然而从直觉上 看 3 ,我们认为简单的模型对新数据的泛化能力更好。如果规律是“年龄大于 50 岁的人想 要买船”,并且这可以解释所有顾客的行为,那么我们将更相信这条规律,而不是与年 龄、子女和婚姻状况都有关系的那条规律。因此,我们总想找到最简单的模型。构建一 个对现有信息量来说过于复杂的模型,正如我们的新手数据科学家做的那样,这被称为 过拟合(overfitting)。如果你在拟合模型时过分关注训练集的细节,得到了一个在训练 集上表现很好、但不能泛化到新数据上的模型,那么就存在过拟合。与之相反,如果你 的模型过于简单——比如说,“有房子的人都买船”——那么你可能无法抓住数据的全部 内容以及数据中的变化,你的模型甚至在训练集上的表现就很差。选择过于简单的模型 被称为欠拟合(underfitting)。 我们的模型越复杂,在训练数据上的预测结果就越好。但是,如果我们的模型过于复杂, 我们开始过多关注训练集中每个单独的数据点,模型就不能很好地泛化到新数据上。 二者之间存在一个最佳位置,可以得到最好的泛化性能。这就是我们想要的模型。 图 2-1 给出了过拟合与欠拟合之间的权衡。 注 3:在数学上也可以证明这一点。 (续) 书籍下载qq群6089740 钉钉群21734177 IT书籍 http://t.cn/RDIAj5D 电子书寻找看手相 钉钉或微信pythontesting

训练精度 最佳模型 泛化精度 精度 欠拟合 过拟合 模型复杂度 图2-1:模型复杂度与训练精度和测试精度之间的权衡 模型复杂度与数据集大小的关系 需要注意,模型复杂度与训练数据集中输入的变化密切相关:数据集中包含的数据点的变 化范围越大,在不发生过拟合的前提下你可以使用的模型就越复杂。通常来说,收集更多 的数据点可以有更大的变化范围,所以更大的数据集可以用来构建更复杂的模型。但是, 仅复制相同的数据点或收集非常相似的数据是无济于事的。 回到前面卖船的例子,如果我们查看了10000多行的顾客数据,并且所有数据都符合 这条规律:“如果顾客年龄大于45岁,并且子女少于3个或没有离婚,那么他就想要买 船”,那么我们就更有可能相信这是一条有效的规律,比从表2-1中仅12行数据得出来 的更为可信。 收集更多数据,适当构建更复杂的模型,对监督学习任务往往特别有用。本书主要关注固 定大小的数据集。在现实世界中,你往往能够决定收集多少数据,这可能比模型调参更为 有效。永远不要低估更多数据的力量! 2.3监督学习算法 现在开始介绍最常用的机器学习算法,并解释这些算法如何从数据中学习以及如何预测。 我们还会讨论每个模型的复杂度如何变化,并概述每个算法如何构建模型。我们将说明每 个算法的优点和缺点,以及它们最适应用于哪类数据。此外还会解释最重要的参数和选项 的含义。4许多算法都有分类和回归两种形式,两者我们都会讲到。 注4:讲解所有的参数和选项超出了本书范围,你可以参阅scikit-learn文档(htp:/scikit--leam.org/stable/ documentation)来了解更多细节。 24 |第2章
24 | 第 2 章 精度 模型复杂度 欠拟合 过拟合 最佳模型 训练精度 泛化精度 图 2-1:模型复杂度与训练精度和测试精度之间的权衡 模型复杂度与数据集大小的关系 需要注意,模型复杂度与训练数据集中输入的变化密切相关:数据集中包含的数据点的变 化范围越大,在不发生过拟合的前提下你可以使用的模型就越复杂。通常来说,收集更多 的数据点可以有更大的变化范围,所以更大的数据集可以用来构建更复杂的模型。但是, 仅复制相同的数据点或收集非常相似的数据是无济于事的。 回到前面卖船的例子,如果我们查看了 10 000 多行的顾客数据,并且所有数据都符合 这条规律:“如果顾客年龄大于 45 岁,并且子女少于 3 个或没有离婚,那么他就想要买 船”,那么我们就更有可能相信这是一条有效的规律,比从表 2-1 中仅 12 行数据得出来 的更为可信。 收集更多数据,适当构建更复杂的模型,对监督学习任务往往特别有用。本书主要关注固 定大小的数据集。在现实世界中,你往往能够决定收集多少数据,这可能比模型调参更为 有效。永远不要低估更多数据的力量! 2.3 监督学习算法 现在开始介绍最常用的机器学习算法,并解释这些算法如何从数据中学习以及如何预测。 我们还会讨论每个模型的复杂度如何变化,并概述每个算法如何构建模型。我们将说明每 个算法的优点和缺点,以及它们最适应用于哪类数据。此外还会解释最重要的参数和选项 的含义。4 许多算法都有分类和回归两种形式,两者我们都会讲到。 注 4:讲解所有的参数和选项超出了本书范围,你可以参阅 scikit-learn 文档(http://scikit-learn.org/stable/ documentation)来了解更多细节