
China-pub.com 下载 第1章概 论 本章要点 ·为什么要用编译器 ·编译器结构中的其他问题 ·与编译器相关的程序 ·自举与移植 ·翻译步 ·TNY样本语言与编译器 ·编译器中的主要数据结构 ·C-Minus:编译器项目的一种语言 编译器是将一种语言翻译为另一种语言的计算机程序。编译器将源程序(source language) 编写的程序作为输入,而产生用目标语言(target language)编写的等价程序。通常地,源程 序为高级语言(high-level language),如C或c++,而目标语言则是目标机器的目标代码 (object code,有时也称作机器代码(machine code),也就是写在计算机机器指令中的用于运 行的代码。这一过程可以用下图表示: 源程序一编译器一目标程序 编译器是一种相当复杂的程序,其代码的长度可从10000行到1000000行不等。编写甚至 读懂这样的一个程序都非易事,大多数的计算机科学家和专业人员也从来没有编写过一个完整 的编译器。但是,几乎所有形式的计算均要用到编译器,而且任何一个与计算机打交道的专业 人员都应掌握编译器的基本结构和操作。除此之外,计算机应用程序中经常遇到的一个任务就 是命令解释程序和界面程序的开发,这比编译器要小,但使用的却是相同的技术。因此,掌握 这一技术具有非常大的实际意义。 也正因为这一点,本书不仅仅要讲解基础知识,还为读者提供了所有必要的工具和设计编 写真正的编译器的实践。要做到这些,就必须学习各项理论知识,而这主要应从自动机原理 (它使编译器结构合理)着手。在讲述时我们假设读者并不了解自动机原理。当然,此处的观 点与标准的自动机原理论著有所不同,这些论著特别强调编译过程:但是,学过自动机原理的 读者就会发现对这些理论材料很熟悉,这部分阅读起来也十分迅速。特别是对于那些十分了解 自动机原理背景的读者来说,对2.2节、2.3节、2.4节和3.2节就不必细读了。无论怎样,读者都 应知道基本的数据结构和离散数学。机器结构和汇编语言的相关知识也很重要,在第8章“代 码生成”中尤为如此 实际编码技术的研究本身就要求认真规划,这是因为即使有很好的理论基础,编码的细节 也可能会复杂得令人不知如何操作。本书包括了有关程序设计语言结构的一系列简单示例,并 利用它们针对该项技术进行详细描述,讨论中使用到的语言被称作TNY。此外,附录A还提供 了一个更泛的示例,它包括了一个小小的但却非常复杂的适用于分类项目的C子集(称作C Mius)。本书还有大量的练习,这其中包括简单的笔头训练、文本中的代码扩充,以及更多的 相关编码练习。 总之,在编译器结构和被编译的程序设计语言的设计之间存在着一个很重要的交互。在本 书中,只是附带着讲解了一下语言设计问题,而是着重于程序设计语言的概念和设计问题(参
下载 第1章 概 论 本章要点 • 为什么要用编译器 • 编译器结构中的其他问题 • 与编译器相关的程序 • 自举与移植 • 翻译步骤 • TINY样本语言与编译器 • 编译器中的主要数据结构 • C-Minus:编译器项目的一种语言 编译器是将一种语言翻译为另一种语言的计算机程序。编译器将源程序( source language) 编写的程序作为输入,而产生用目标语言( t a rget language)编写的等价程序。通常地,源程 序为高级语言( high-level language),如C或C + +,而目标语言则是目标机器的目标代码 (object code,有时也称作机器代码(machine code)),也就是写在计算机机器指令中的用于运 行的代码。这一过程可以用下图表示: 编译器是一种相当复杂的程序,其代码的长度可从 10 000行到1 000 000行不等。编写甚至 读懂这样的一个程序都非易事,大多数的计算机科学家和专业人员也从来没有编写过一个完整 的编译器。但是,几乎所有形式的计算均要用到编译器,而且任何一个与计算机打交道的专业 人员都应掌握编译器的基本结构和操作。除此之外,计算机应用程序中经常遇到的一个任务就 是命令解释程序和界面程序的开发,这比编译器要小,但使用的却是相同的技术。因此,掌握 这一技术具有非常大的实际意义。 也正因为这一点,本书不仅仅要讲解基础知识,还为读者提供了所有必要的工具和设计编 写真正的编译器的实践。要做到这些,就必须学习各项理论知识,而这主要应从自动机原理 (它使编译器结构合理)着手。在讲述时我们假设读者并不了解自动机原理。当然,此处的观 点与标准的自动机原理论著有所不同,这些论著特别强调编译过程;但是,学过自动机原理的 读者就会发现对这些理论材料很熟悉,这部分阅读起来也十分迅速。特别是对于那些十分了解 自动机原理背景的读者来说,对2 . 2节、2 . 3节、2 . 4节和3 . 2节就不必细读了。无论怎样,读者都 应知道基本的数据结构和离散数学。机器结构和汇编语言的相关知识也很重要,在第 8章“代 码生成”中尤为如此。 实际编码技术的研究本身就要求认真规划,这是因为即使有很好的理论基础,编码的细节 也可能会复杂得令人不知如何操作。本书包括了有关程序设计语言结构的一系列简单示例,并 利用它们针对该项技术进行详细描述,讨论中使用到的语言被称作 T I N Y。此外,附录A还提供 了一个更广泛的示例,它包括了一个小小的但却非常复杂的适用于分类项目的 C子集(称作C - M i n u s)。本书还有大量的练习,这其中包括简单的笔头训练、文本中的代码扩充,以及更多的 相关编码练习。 总之,在编译器结构和被编译的程序设计语言的设计之间存在着一个很重要的交互。在本 书中,只是附带着讲解了一下语言设计问题,而是着重于程序设计语言的概念和设计问题(参 源程序 → 编译器 → 目标程序

2 编译原理及实践 China-pub.co 下载 见本章最后的“注意与参考”部分) 首先将简要地介绍编译器的历史及其存在目的与理由,以及与编译器相关的程序描述。接 着讲解编译器的结构、各种翻译过程和相关的数据结构,并联系一个简单的具体示例来示范这 个结构。最后,再概括地讲述一下编译器结构的其他问题,这包括自举和移植,以及本书后面 用到的主要语言的描述。 1.1为什么要用编译器 在本世纪40年代,由于冯·诺伊曼在存储-程序计算机方面的先锋作用,编写一串代码或 程序已成必要,这样计算机就可以执行所需的计算。开始时,这些程序都是用机器语言 (machine language)编写的。机器语言就是表示机器实际操作的数字代码,例如: c70600000002 表示在IBM PC.上使用的8x86处理器将数字2移至地址00o0(16进制)的指令。当然,编写 这样的代码是十分费时和乏味的,这种代码形式很快就被汇编语言(assembly language)代替 了。在汇编语言中,都是以符号形式给出指令和存储地址的。例如,汇编语言指令 MOV X, 就与前面的机器指令等价(假设符号存储地址X是0O00)。汇编程序(assembler)将汇编语言 的符号代码和存储地址翻译成与机器语言相对应的数字代码。 汇编语言大大提高了编程的速度和准确度,人们至今仍在使用着它,在编码需要极快的速 度和极高的简洁程度时尤为如此。但是,汇编语言也有许多缺点:编写起来也不容易,阅读和 理解很难:而且汇编语言的编写严格依赖于特定的机器,所以为一台计算机编写的代码在应用 于另一台计算机时必须完全重写。很明显,发展编程技术的下一个重要步骤就是以一个更类似 于数学定义或自然语言的简洁形式来编写程序的操作,它应与任何机器都无关,而且也可由 个程序翻译为可执行的代码。例如,前面的汇编语言代码可以写成一个简洁的与机器无关的形式 ■2 起初人们担心这是不可能的,或者即使可能,目标代码也会因效率不高而没有多大用处 在1954年至1957年期间,IBM的John Backusi带领的一个研究小组对FORTRAN语言及其编 译器的开发,使得上面的担忧不必要了。但是,由于当时处理中所涉及到的大多数程序设计语 言的翻译并不为人所掌握,所以这个项目的成功也伴随着巨大的辛劳。 几乎与此同时,人们也在开发着第一个编译器,Noam Chomsky开始了他的自然语言结 构的研究。他的发现最终使得编译器结构异常简单,甚至还带有了一些自动化。 Chomsky的 研究导致了根据语言文法(grammar,指定其结构的规则)的难易程度以及识别它们所需的 算法来为语言分类。正如现在所称的一与乔姆斯基分类结构(Chomsky hierarchy)一样一 包括了文法的4个层次:0型、1型、2型和3型文法,且其中的每一个都是其前者的专门化。2 型(或上下文无关文法(context--free grammar)被证明是程序设计语言中最有用的,而且 今天它已代表着程序设计语言结构的标准方式。分析问避(parsing problem,用于限定上下 文无关语言的识别的有效算法)的研究是在60年代和70年代,它相当完善地解决了这一问题, 现在它已是编译理论的一个标准部分。本书的第3、4和5章将研究上下文无关的语言和分析 算法。 有穷自动机(finite automata)和正则表达式(regular expression)同上下文无关文法紧密 相关,它们与乔姆斯基的3型文法相对应。对它们的研究与乔姆斯基的研究几乎同时开始,并 且引出了表示程序设计语言的单词(或称为记号)的符号方式。第2章将讲述有穷自动机和正
见本章最后的“注意与参考”部分)。 首先将简要地介绍编译器的历史及其存在目的与理由,以及与编译器相关的程序描述。接 着讲解编译器的结构、各种翻译过程和相关的数据结构,并联系一个简单的具体示例来示范这 个结构。最后,再概括地讲述一下编译器结构的其他问题,这包括自举和移植,以及本书后面 用到的主要语言的描述。 1.1 为什么要用编译器 在本世纪4 0年代,由于冯·诺伊曼在存储 -程序计算机方面的先锋作用,编写一串代码或 程序已成必要,这样计算机就可以执行所需的计算。开始时,这些程序都是用机器语言 (machine language)编写的。机器语言就是表示机器实际操作的数字代码,例如: C7 06 0000 0002 表示在IBM PC上使用的Intel 8x86处理器将数字2移至地址0 0 0 0(1 6进制)的指令。当然,编写 这样的代码是十分费时和乏味的,这种代码形式很快就被汇编语言( assembly language)代替 了。在汇编语言中,都是以符号形式给出指令和存储地址的。例如,汇编语言指令 MOV X, 2 就与前面的机器指令等价(假设符号存储地址 X是0 0 0 0)。汇编程序(a s s e m b l e r)将汇编语言 的符号代码和存储地址翻译成与机器语言相对应的数字代码。 汇编语言大大提高了编程的速度和准确度,人们至今仍在使用着它,在编码需要极快的速 度和极高的简洁程度时尤为如此。但是,汇编语言也有许多缺点:编写起来也不容易,阅读和 理解很难;而且汇编语言的编写严格依赖于特定的机器,所以为一台计算机编写的代码在应用 于另一台计算机时必须完全重写。很明显,发展编程技术的下一个重要步骤就是以一个更类似 于数学定义或自然语言的简洁形式来编写程序的操作,它应与任何机器都无关,而且也可由一 个程序翻译为可执行的代码。例如,前面的汇编语言代码可以写成一个简洁的与机器无关的形式 x = 2 起初人们担心这是不可能的,或者即使可能,目标代码也会因效率不高而没有多大用处。 在1 9 5 4年至1 9 5 7年期间,I B M的John Backus带领的一个研究小组对F O RT R A N语言及其编 译器的开发,使得上面的担忧不必要了。但是,由于当时处理中所涉及到的大多数程序设计语 言的翻译并不为人所掌握,所以这个项目的成功也伴随着巨大的辛劳。 几乎与此同时,人们也在开发着第一个编译器, Noam Chomsky开始了他的自然语言结 构的研究。他的发现最终使得编译器结构异常简单,甚至还带有了一些自动化。 C h o m s k y的 研究导致了根据语言文法( g r a m m a r,指定其结构的规则)的难易程度以及识别它们所需的 算法来为语言分类。正如现在所称的 — 与乔姆斯基分类结构( Chomsky hierarchy)一样 — 包括了文法的4个层次:0型、1型、2型和3型文法,且其中的每一个都是其前者的专门化。 2 型(或上下文无关文法( context-free grammar))被证明是程序设计语言中最有用的,而且 今天它已代表着程序设计语言结构的标准方式。分析问题( parsing problem,用于限定上下 文无关语言的识别的有效算法)的研究是在 6 0年代和7 0年代,它相当完善地解决了这一问题, 现在它已是编译理论的一个标准部分。本书的第 3、4和5章将研究上下文无关的语言和分析 算法。 有穷自动机(finite automata)和正则表达式(regular expression)同上下文无关文法紧密 相关,它们与乔姆斯基的 3型文法相对应。对它们的研究与乔姆斯基的研究几乎同时开始,并 且引出了表示程序设计语言的单词(或称为记号)的符号方式。第 2章将讲述有穷自动机和正 2 编译原理及实践 下载

China-pub.com 第1章腰论了 下载 则表达式。 人们接着又深化了生成有效的目标代码的方法,这就是最初的编译器,它们被一直使用至 今。人们通常将其误称为优化技术(optimization technique),但因其从未真正地得到过被优化 了的目标代码而仅仅改进了它的有效性,因此实际上应称作代码改进技术(code improvement technique)。第8章将讲述该技术的基础知识 当分析问题变得好懂起来时,人们就在开发程序上花费了很大的功夫来研究这一部分的编 译器的自动构造。这些程序最初被称为编译程序-编译器,但更确切地应称为分析程序生成器 (parser generator),这是因为它们仅仅能够自动处理编译的一部分。这些程序中最著名的是 Yacc(yet another compiler-compiler),它是由Steve Johnson在1975年为Unix系统编写的,我们将 在第5章中再次谈到它。类似地,有穷自动机的研究也发展了另一种称为扫描程序生成器 (scanner generator)的工具,Lex(与Yacc同时,由Mike Lesk为Unix系统开发的)是这其中的 佼佼者。读者将在第2章中学到Lex。 在70年代后期和80年代早期,大量的项目都关注于编译器其他部分的生成自动化,这其中 就包括了代码生成。这些尝试并未取得多少成功,这大概是因为操作太复杂而人们又对其不甚 了解,本书也就不详细谈它了 编译器设计最近的发展包括:首先,编译器包括了更为复杂的算法的应用程序,它用于推 断和/或简化程序中的信息:这又与更为复杂的程序设计语言(可允许此类分析)的发展结合 在一起。其中典型的有用于函数语言编译的HindIey-Milner类型检查的统一算法。其次,编译 器已越来越成为基于窗口的交互开发环境(interactive development environment,IDE)的一部 分,它包括了编辑器、链接程序、调试程序以及项目管理程序。这样的DE的标准并没有多少 但是已沿着这一方向对标准的窗口环境进行开发了。这一专题的研究超出了本书的范围(但是 读者可以参阅下一节中有关DE部件的内容)。读者可以参阅本章末尾的“注意与参考”中的 文献内容。尽管近年来对此进行了大量的研究,但是基本的编译器设计在近20年中都没有多大 的改变,而且它们正迅速地成为计算机科学课程中的中心一环。 1.2与编译器相关的程序 本节主要描述与编译器有关或专编译器一同使用的其他程序,以及那些在一个完整的语言 开发环境中与编译器一同使用的程序(有一些已在前面提到过)。 ()解释程序(interpreter) 解释程序是如同编译器的一种语言翻译程序。它与编译器的不同之处在于:它立即执行源 程序而不是生成在翻译完成之后才执行的目标代码。从原理上讲,任何程序设计语言都可被解 释或被编译,但是根据所使用的语言和翻译情况,很可能会选用解释程序而不用编译器。例如, 我们经常解释BASIC语言而不是去编译它。类似地,诸如LISP的函数语言也常常是被解释的。 解释程序也经常用于教育和软件的开发,此处的程序很有可能被翻译若干次。而另一方面,当 执行的速度是最为重要的因素时就使用编译器,这是因为被编译的目标代码比被解释的源代码 要快得多,有时要快10倍或更多。但是,解释程序具有许多与编译器共享的操作,而两者之间 也有一些混合之处。本书后面也将会提到解释程序,但重点仍是编译。 (2)汇编程序(assembler) 汇编程序是用于特定计算机上的汇编语言的翻译程序。正如前面所提到的,汇编语言是计 算机的机器语言的符号形式,它极易翻译。有时,编译器会生成汇编语言以作为其目标语言, 然后再由一个汇编程序将它翻译成目标代码
则表达式。 人们接着又深化了生成有效的目标代码的方法,这就是最初的编译器,它们被一直使用至 今。人们通常将其误称为优化技术( optimization technique),但因其从未真正地得到过被优化 了的目标代码而仅仅改进了它的有效性,因此实际上应称作代码改进技术( code improvement t e c h n i q u e)。第8章将讲述该技术的基础知识。 当分析问题变得好懂起来时,人们就在开发程序上花费了很大的功夫来研究这一部分的编 译器的自动构造。这些程序最初被称为编译程序 -编译器,但更确切地应称为分析程序生成器 (parser generator),这是因为它们仅仅能够自动处理编译的一部分。这些程序中最著名的是 Ya c c(yet another compiler- c o m p i l e r),它是由Steve Johnson在1 9 7 5年为U n i x系统编写的,我们将 在第 5章中再次谈到它。类似地,有穷自动机的研究也发展了另一种称为扫描程序生成器 (scanner generator)的工具,L e x(与Ya c c同时,由Mike Lesk为U n i x系统开发的)是这其中的 佼佼者。读者将在第2章中学到L e x。 在7 0年代后期和8 0年代早期,大量的项目都关注于编译器其他部分的生成自动化,这其中 就包括了代码生成。这些尝试并未取得多少成功,这大概是因为操作太复杂而人们又对其不甚 了解,本书也就不详细谈它了。 编译器设计最近的发展包括:首先,编译器包括了更为复杂的算法的应用程序,它用于推 断和/或简化程序中的信息;这又与更为复杂的程序设计语言(可允许此类分析)的发展结合 在一起。其中典型的有用于函数语言编译的 H i n d l e y - M i l n e r类型检查的统一算法。其次,编译 器已越来越成为基于窗口的交互开发环境( interactive development environment,I D E)的一部 分,它包括了编辑器、链接程序、调试程序以及项目管理程序。这样的 I D E的标准并没有多少, 但是已沿着这一方向对标准的窗口环境进行开发了。这一专题的研究超出了本书的范围(但是 读者可以参阅下一节中有关 I D E部件的内容)。读者可以参阅本章末尾的“注意与参考”中的 文献内容。尽管近年来对此进行了大量的研究,但是基本的编译器设计在近 2 0年中都没有多大 的改变,而且它们正迅速地成为计算机科学课程中的中心一环。 1.2 与编译器相关的程序 本节主要描述与编译器有关或专编译器一同使用的其他程序,以及那些在一个完整的语言 开发环境中与编译器一同使用的程序(有一些已在前面提到过)。 (1) 解释程序(i n t e r p re t e r) 解释程序是如同编译器的一种语言翻译程序。它与编译器的不同之处在于:它立即执行源 程序而不是生成在翻译完成之后才执行的目标代码。从原理上讲,任何程序设计语言都可被解 释或被编译,但是根据所使用的语言和翻译情况,很可能会选用解释程序而不用编译器。例如, 我们经常解释B A S I C语言而不是去编译它。类似地,诸如 L I S P的函数语言也常常是被解释的。 解释程序也经常用于教育和软件的开发,此处的程序很有可能被翻译若干次。而另一方面,当 执行的速度是最为重要的因素时就使用编译器,这是因为被编译的目标代码比被解释的源代码 要快得多,有时要快1 0倍或更多。但是,解释程序具有许多与编译器共享的操作,而两者之间 也有一些混合之处。本书后面也将会提到解释程序,但重点仍是编译。 (2) 汇编程序(a s s e m b l e r) 汇编程序是用于特定计算机上的汇编语言的翻译程序。正如前面所提到的,汇编语言是计 算机的机器语言的符号形式,它极易翻译。有时,编译器会生成汇编语言以作为其目标语言, 然后再由一个汇编程序将它翻译成目标代码。 第 1章 概 论 3 下载

编译原理及实践 China-pub.C 下载 (3)连接程序(linker) 编译器和汇编程序都经常依赖于连接程序,它将分别在不同的目标文件中编译或汇编的代 码收集到一个可直接执行的文件中。在这种情况下,目标代码,即还未被连接的机器代码,与 可执行的机器代码之间就有了区别。连接程序还连接目标程序和用于标准库函数的代码,以及 连接目标程序和由计算机的操作系统提供的资源(例如,存储分配程序及输入与输出设备)。 有趣的是,连接程序现在正在完成编译器最早的一个主要活动(这也是“编译”一词的用法, 即通过收集不同的来源来构造)。因为连接过程对操作系统和处理器有极大的依赖性,本书也 就不研究它了。我们也对不细分连接的目标代码和可执行的代码,这是因为对于编译技术而言, 这个区别并不重要 (④装入程序(loader) 编译要、厂编得常或连接程序生成的代码经常还不完全话用或不能抽行,但是它们的主要 存储器访问却可以在存储器的任何位置中且与一个不确定的起始位置相关。这样的代码被称为 是可重定位的(relocatable),而装入程序可处理所有的与指定的基地址或起始地址有关的可重 定位的地址。装入程序使得可执行代码更加灵活,但是装入处理通常是在后台(作为操作环境 的一部分)或与连接相联合时才发生,装入程序极少会是实际的独立程序。 ()预处理器(preprocessor) 预处理器是在真正的翻译开始之前由编译器调用的独立程序。预处理器可以别除注释、包 含其他文件以及执行宏(宏macro是一段重复文字的简短描写)替代。预处理器可由语言(如 C)要求或以后作为提供额外功能(诸如为FORTRAN提供Ratfor预处理器)的附加软件, (6)编辑器(editor) 编译器通常接受由任何生成标准文件(例如ASCⅡ文件)的编辑器编写的源程序。最近, 编译器已与另 个编辑器和其他程序捆绑进一个交互的开发环境 IDE中。此时,尽管编辑 器仍然生成标准文件,但会转向正被讨论的程序设计语言的格式或结构。这样的编辑器称为基 于结构的(structure based),且它早已包括了编译器的某些操作:因此,程序员就会在程序的 编写时而不是在编译时就得知错误了。从编辑器中也可调用编译器以及与它共用的程序,这样 程序员无需离开编辑器就可执行程序。 ()调试程序(debugger 调试程序是可在被编译了的程序中判定执行错误的程序,它也经常与编译器一起放在DE 中。运行一个带有调试程序的程序与直接执行不同,这是因为调试程序保存着所有的或大多数 源代码信息(诸如行数、变量名和过程)。它还可以在预先指定的位置(称为断点(breakpoint) 暂停执行,并提供有关已调用的函数以及变量的当前值的信息。为了执行这些函数,编译器必 须为调试程序提供恰当的符号信息,而这有时却相当困难,尤其是在一个要优化目标代码的编 译器中。因此,调试又变成了一个编译问题,本书的内容就不涉及它了。 ()⑧描述器(prof) 描述器是在执行中搜集目标程序行为统计的程序。程序员特别感兴趣的统计是每一个过程 的调用次数和每一个过程执行时间所占的百分比。这样的统计对于帮助程序员提高程序的执 行速度极为有用。有时编译器也甚至无需程序员的干涉就可利用描述器的输出来自动改进目 标代码。 (9)项目管理程序(project mana ager 现在的软件项目通常大到需要由一组程序员来完成,这时对那些由不同人员操作的文件进 行整理就非常重要了,而这正是项目管理程序的任务。例如,项目管理程序应将由不同的程序
(3) 连接程序(l i n k e r) 编译器和汇编程序都经常依赖于连接程序,它将分别在不同的目标文件中编译或汇编的代 码收集到一个可直接执行的文件中。在这种情况下,目标代码,即还未被连接的机器代码,与 可执行的机器代码之间就有了区别。连接程序还连接目标程序和用于标准库函数的代码,以及 连接目标程序和由计算机的操作系统提供的资源(例如,存储分配程序及输入与输出设备)。 有趣的是,连接程序现在正在完成编译器最早的一个主要活动(这也是“编译”一词的用法, 即通过收集不同的来源来构造)。因为连接过程对操作系统和处理器有极大的依赖性,本书也 就不研究它了。我们也对不细分连接的目标代码和可执行的代码,这是因为对于编译技术而言, 这个区别并不重要。 (4) 装入程序(l o a d e r) 编译器、汇编程序或连接程序生成的代码经常还不完全适用或不能执行,但是它们的主要 存储器访问却可以在存储器的任何位置中且与一个不确定的起始位置相关。这样的代码被称为 是可重定位的(r e l o c a t a b l e),而装入程序可处理所有的与指定的基地址或起始地址有关的可重 定位的地址。装入程序使得可执行代码更加灵活,但是装入处理通常是在后台(作为操作环境 的一部分)或与连接相联合时才发生,装入程序极少会是实际的独立程序。 (5) 预处理器(p re p ro c e s s o r) 预处理器是在真正的翻译开始之前由编译器调用的独立程序。预处理器可以删除注释、包 含其他文件以及执行宏(宏 m a c r o是一段重复文字的简短描写)替代。预处理器可由语言(如 C)要求或以后作为提供额外功能(诸如为F O RT R A N提供R a t f o r预处理器)的附加软件。 (6) 编辑器(e d i t o r) 编译器通常接受由任何生成标准文件(例如 A S C I I文件)的编辑器编写的源程序。最近, 编译器已与另一个编辑器和其他程序捆绑进一个交互的开发环境—— I D E中。此时,尽管编辑 器仍然生成标准文件,但会转向正被讨论的程序设计语言的格式或结构。这样的编辑器称为基 于结构的(structure based),且它早已包括了编译器的某些操作;因此,程序员就会在程序的 编写时而不是在编译时就得知错误了。从编辑器中也可调用编译器以及与它共用的程序,这样 程序员无需离开编辑器就可执行程序。 (7) 调试程序(d e b u g g e r) 调试程序是可在被编译了的程序中判定执行错误的程序,它也经常与编译器一起放在 I D E 中。运行一个带有调试程序的程序与直接执行不同,这是因为调试程序保存着所有的或大多数 源代码信息(诸如行数、变量名和过程)。它还可以在预先指定的位置(称为断点(b r e a k p o i n t)) 暂停执行,并提供有关已调用的函数以及变量的当前值的信息。为了执行这些函数,编译器必 须为调试程序提供恰当的符号信息,而这有时却相当困难,尤其是在一个要优化目标代码的编 译器中。因此,调试又变成了一个编译问题,本书的内容就不涉及它了。 (8) 描述器(p ro f i l e r) 描述器是在执行中搜集目标程序行为统计的程序。程序员特别感兴趣的统计是每一个过程 的调用次数和每一个过程执行时间所占的百分比。这样的统计对于帮助程序员提高程序的执 行速度极为有用。有时编译器也甚至无需程序员的干涉就可利用描述器的输出来自动改进目 标代码。 (9) 项目管理程序(p roject manager) 现在的软件项目通常大到需要由一组程序员来完成,这时对那些由不同人员操作的文件进 行整理就非常重要了,而这正是项目管理程序的任务。例如,项目管理程序应将由不同的程序 4 编译原理及实践 下载
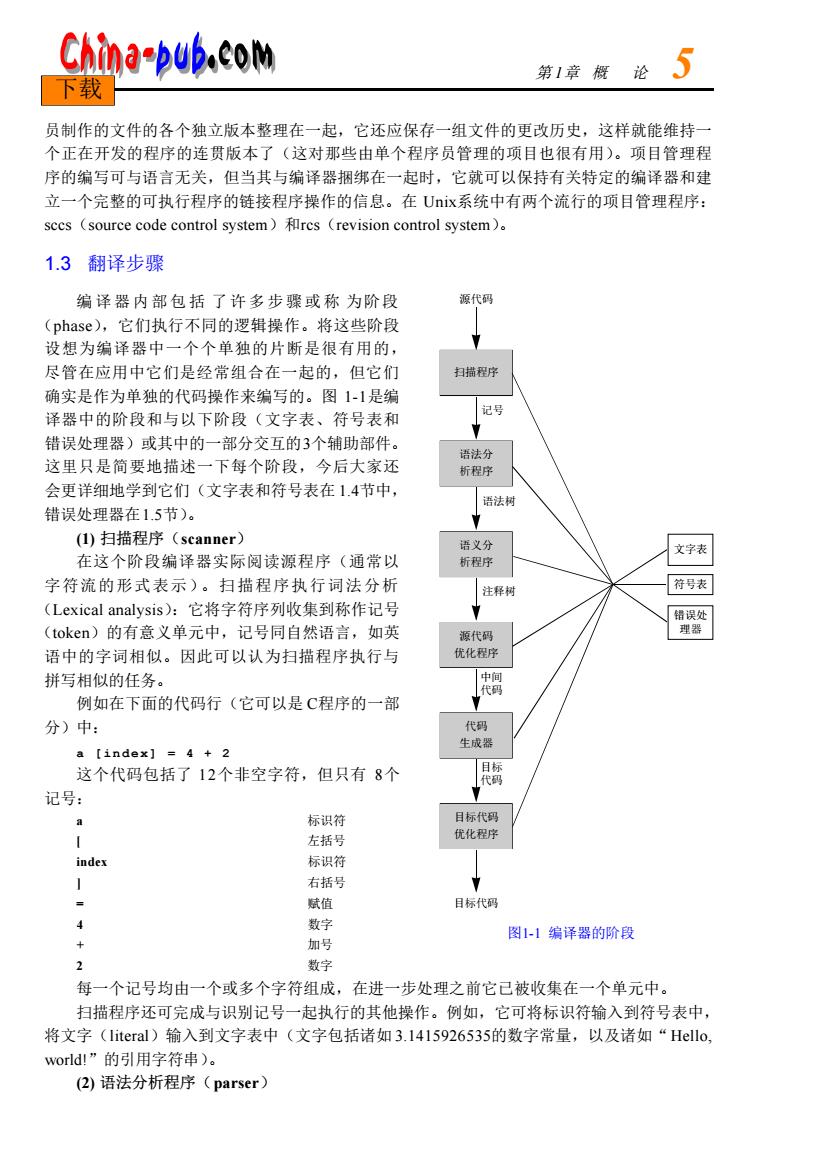
China-pub.com 下载 第1章餐论了 员制作的文件的各个独立版本整理在一起,它还应保存一组文件的更改历史,这样就能维持 个正在开发的程序的连贯版本了(这对那些由单个程序员管理的项目也很有用)。项目管理程 序的编写可与语言无关,但当其与编译器捆绑在一起时,它就可以保持有关特定的编译器和建 立一个完整的可执行程序的链接程序操作的信息。在Uix系统中有两个流行的项目管理程序: sces (source code control system)res (revision control system). 1.3翻译步骤 编译器内部包括了许多步骤或称为阶段 源代码 (phase),它们执行不同的逻辑操作。将这些阶段 设想为编译器中一个个单独的片断是很有用的, 尽管在应用中它们是经常组合在一起的,但它们 确实是作为单独的代码操作来编写的。图1-1是编 译器中的阶段和与以下阶段(文字表、符号表和 错误处理器)或其中的一部分交互的3个辅助部件 这里只是简要地描述一下每个阶段,今后大家还 会更详细地学到它们(文字表和符号表在1.4节中, 错误处理器在1.5节)。 法 ()扫描程序(scanner) 在这个阶段编译器实际阅读源程序(通常以 文字表 字符流的形式表示)。扫描程序执行词法分析 注释 符号表 (Lexical analysis):它将字符序列收集到称作记号 (token)的有意义单元中,记号同自然语言,如英 语中的字词相似。因此可以认为扫描程序执行与 拼写相似的任务 例如在下面的代码行(它可以是C程序的一部 分)中: a【index】=4+2 这个代码包括了12个非空字符,但只有8个 记号: 标识符 左括号 index 标识符 右括号 赋值 日标代码 4 数字 加号 图1-1编译器的阶段 3 数字 每一个记号均由一个或多个字符组成,在进一步处理之前它已被收集在一个单元中。 扫描程序还可完成与识别记号一起执行的其他操作。例如,它可将标识符输入到符号表中, 将文字(literal)输入到文字表中(文字包括诸如3.1415926535的数字常量,以及诸如“Hello world!”的引用字符串)。 (2)语法分析程序(parser)
员制作的文件的各个独立版本整理在一起,它还应保存一组文件的更改历史,这样就能维持一 个正在开发的程序的连贯版本了(这对那些由单个程序员管理的项目也很有用)。项目管理程 序的编写可与语言无关,但当其与编译器捆绑在一起时,它就可以保持有关特定的编译器和建 立一个完整的可执行程序的链接程序操作的信息。在 U n i x系统中有两个流行的项目管理程序: s c c s(source code control system)和r c s(revision control system)。 1.3 翻译步骤 编译器内部包括 了许多步骤或称 为阶段 (p h a s e),它们执行不同的逻辑操作。将这些阶段 设想为编译器中一个个单独的片断是很有用的, 尽管在应用中它们是经常组合在一起的,但它们 确实是作为单独的代码操作来编写的。图 1 - 1是编 译器中的阶段和与以下阶段(文字表、符号表和 错误处理器)或其中的一部分交互的3个辅助部件。 这里只是简要地描述一下每个阶段,今后大家还 会更详细地学到它们(文字表和符号表在 1 . 4节中, 错误处理器在1 . 5节)。 (1) 扫描程序(s c a n n e r) 在这个阶段编译器实际阅读源程序(通常以 字符流的形式表示)。扫描程序执行词法分析 (Lexical analysis):它将字符序列收集到称作记号 (t o k e n)的有意义单元中,记号同自然语言,如英 语中的字词相似。因此可以认为扫描程序执行与 拼写相似的任务。 例如在下面的代码行(它可以是 C程序的一部 分)中: a [index] = 4 + 2 这个代码包括了 1 2个非空字符,但只有 8个 记号: a 标识符 [ 左括号 i n d e x 标识符 ] 右括号 = 赋值 4 数字 + 加号 2 数字 每一个记号均由一个或多个字符组成,在进一步处理之前它已被收集在一个单元中。 扫描程序还可完成与识别记号一起执行的其他操作。例如,它可将标识符输入到符号表中, 将文字(l i t e r a l)输入到文字表中(文字包括诸如 3 . 1 4 1 5 9 2 6 5 3 5的数字常量,以及诸如“H e l l o , w o r l d !”的引用字符串)。 (2) 语法分析程序(p a r s e r) 第 1章 概 论 5 下载 扫描程序 语法分 析程序 语义分 析程序 源代码 优化程序 代码 生成器 目标代码 优化程序 记号 源代码 语法树 注释树 中间 代码 目标 代码 目标代码 符号表 错误处 理器 文字表 图1-1 编译器的阶段