
Optimizing existing large codebase Mem threads Io Improving Memory Handling Measuring Performance Code modernization Improving Memory Handling o Context o Containers and memory o Container reservation o Detecting offending code The nightmare of thread safety Low level optimizations ®Conclusion context comtainera reserving findBadCode 16157 S.Ponce-CERN
Optimizing existing large codebase 16 / 57 S. Ponce - CERN Measure Modernize Mem threads low level c/c context containers reserving findBadCode Improving Memory Handling 1 Measuring Performance 2 Code modernization 3 Improving Memory Handling Context Containers and memory Container reservation Detecting offending code 4 The nightmare of thread safety 5 Low level optimizations 6 Conclusion
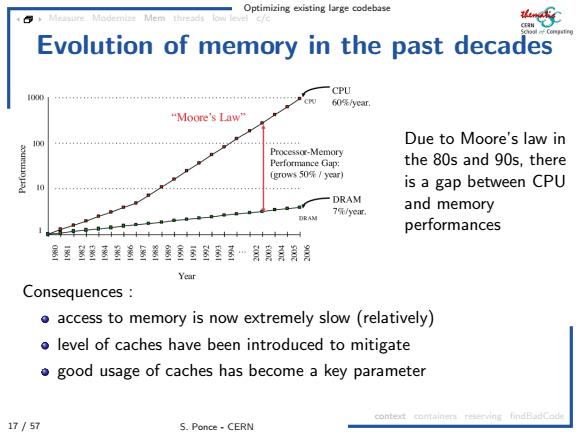
Optimizing existing large codebase 4 Mem threads Evolution of memory in the past decades CPU 60径yer “oore'sLaw 10国 Due to Moore's law in Processor-Memory Performance Gap: the 80s and 90s,there (grows50年/3r) 0 is a gap between CPU -DRAM 7第/小e亚 and memory DRAM performances 家委墨鉴墓鉴墨鉴墨墨鑫玉墨屋…青昌 Year Consequences o access to memory is now extremely slow(relatively) o level of caches have been introduced to mitigate good usage of caches has become a key parameter context comtainers reserving findBadCode 17/57 S.Ponce-CERN
Optimizing existing large codebase 17 / 57 S. Ponce - CERN Measure Modernize Mem threads low level c/c context containers reserving findBadCode Evolution of memory in the past decades Due to Moore’s law in the 80s and 90s, there is a gap between CPU and memory performances Consequences : access to memory is now extremely slow (relatively) level of caches have been introduced to mitigate good usage of caches has become a key parameter

Optimizing existing large codebase Mem threads To Typical cache structure size latency Ll data L1 64 kB 4 cycles instruction L2 Cache 256kB 10 cycles L3 Cache 10 MB 40 cycles DRAM 64 GB 400 cycles Typical data,on an Haswell architecture context comtainers reserving findBadCode 18/57 S.Ponce-CERN
Optimizing existing large codebase 18 / 57 S. Ponce - CERN Measure Modernize Mem threads low level c/c context containers reserving findBadCode Typical cache structure L1 data L1 instruction L2 Cache L3 Cache DRAM size latency 64 kB 4 cycles 256 kB 10 cycles 10 MB 40 cycles 64 GB 400 cycles Typical data, on an Haswell architecture

Optimizing existing large codebase Mem threads Practical consequence in C++ Guidelines o we want as few heap memory allocations as possible stack usage is much better o we want continuous memory blocks,specially for containers that means containers of objects,no pointers involved e.g.vector<Obj*>or array<vector<Obj>>are banned 2 main rules o use container of objects,not of pointers ouse (const)references everywhere avoid any unnecessary copy of data o including implicit ones o use container reservation context comtainers reserving findBadCode 19/57 S.Ponce-CERN
Optimizing existing large codebase 19 / 57 S. Ponce - CERN Measure Modernize Mem threads low level c/c context containers reserving findBadCode Practical consequence in C++ Guidelines we want as few heap memory allocations as possible stack usage is much better ! we want continuous memory blocks, specially for containers that means containers of objects, no pointers involved e.g. vector<Obj*> or array<vector<Obj>> are banned ! 2 main rules use container of objects, not of pointers use (const) references everywhere avoid any unnecessary copy of data including implicit ones use container reservation
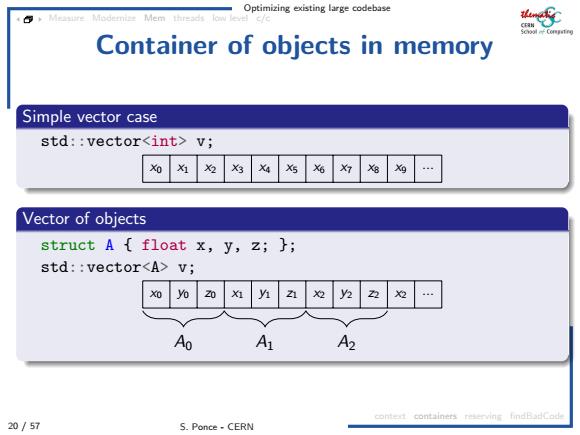
Optimizing existing large codebase Mem threads Container of objects in memory Simple vector case std::vector<int>v; 知 为 X3 Vector of objects struct A float x,y,z;}; std::vector<A>v; 20 Ao A A2 contert containers reserving findBadCode 20/57 S.Ponce-CERN
Optimizing existing large codebase 20 / 57 S. Ponce - CERN Measure Modernize Mem threads low level c/c context containers reserving findBadCode Container of objects in memory Simple vector case std::vector<int> v; x0 x1 x2 x3 x4 x5 x6 x7 x8 x9 ... Vector of objects struct A { float x, y, z; }; std::vector<A> v; x0 y0 z0 A0 x1 y1 z1 A1 x2 y2 z2 A2 x2