
中文分词 心分词面临的主要问题 汉语分词困难重重 ①分词规范:易受主观语感约束,产生不同的切分结果 ②歧义切分 有些歧义无法在句子内部解决, √ 交集歧义 需要结合篇章上下文 研究/生命/的/起源 研究生/命/的/起源 组合歧义 门/把/手/弄/坏/了 门/把手/弄/坏/了 ③未登录词识别 包括中外人名、中国地名、机构组织名、事件名、 货币名、缩略语、派生词、各种专业术 语以及在不断发展和约定俗成的一些新词语。 确定词汇边界:PMI互信息,熵等 确定新词语义:领域词扩展等,LDA,word2vec By事英英 NLP
By 郭凤英 中文分词

分词算法 ●基于规则的分词方法 简单易行,但歧义消解能力差 >基本思想:按照一定策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配 >主要方法:最大匹配、逆向最大匹配、双向最佳匹配、逐词遍历 ●基于统计的分词方法 效果依赖于训练语料的规模和质量 >基本思想:上下文中相邻的字同时出现的次数越多,就越有可能构成一个词,字与字相邻出现的 概率或频率能较好地反映成词的可信度。 >主要方法:N元文法模型(N-gram)、隐马尔可夫模型(Hiden Markov Model,HMM)、 最大熵模型(ME)、条件随机场模型(Conditional Random Fields,CRF)等 ●基于理解的分词方法 需要大量的语言知识和信息 >基本思想:在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象,让计 算机模拟人对句子的理解来进行分词。 >主要方法:专家系统分词、神经网络分词(LSTM,CNN) By英英 NLP
By 郭凤英 分词算法

■词性标注 词性标注(Part of speech tagging)是为分词结果中的每个单词标注一个正确的 词性,也即确定每个词是名词、动词、形容词或者其他词性的过程;主要任务是消 除词性兼类歧义。 我_r毕业_v于_p北京ns清华大学_ni。wp 英语中: 在任何一种自然语言中,词性兼类问题都普遍存在。 1)Time flies like an arrow. 对Brown语料库的统计,55%词兼类。 2)I want you to web our annual report. 《现代汉语八百词》兼类占22.5%。 汉语中: 1)形同音不同,如:好hao3,形容词)、好(hao4,动词) 2)同形同音但意义不同,如:会(会议,名词)、会(能够、动词) 3)具有典型意义的兼类词,如:典型(名词或形容词) 4)上述组合,如:行(xing2,动词/形容词;hang2,名词/量词) By朝英 NLP
By 郭凤英 词性标注

■词性标注算法 基于规则的方法: >根据词语的结构建立词性标注规则 √词缀(前缀、后缀):绿油油(形容词)、一片片(数量词) √重叠词规侧:看看、瞧瞧、高高兴兴、热热闹闹… >基于机器学习的自动规则提取方法 未标注文本 (Unannotated text) √初始词性赋值; 初始标注 √对比正确标注的句子,自动学习结构转换规则 (Initial state) √利用转换规则调整初始赋值 已标注文本 正确的标注文本 (Annotated text) (Truth) 基于统计模型的方法:最大熵、HMM、CRF 综合方法:大 学习器(Learner) 转换规则集(Rules)) √统计概率引导,辅以规侧消歧 B,明英英 NLP
By 郭凤英 词性标注算法
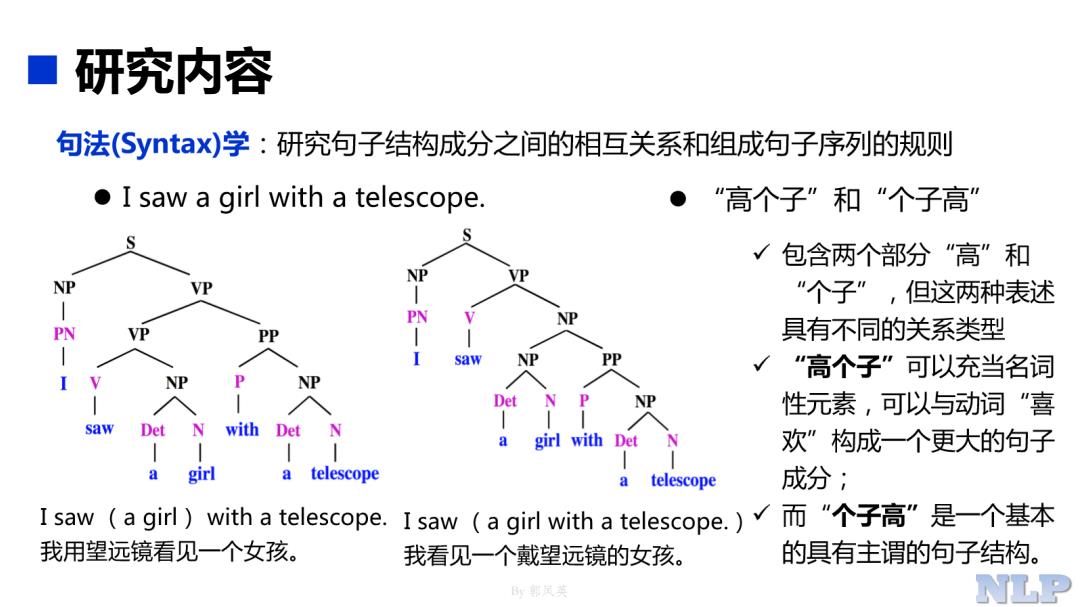
研究内容 句法(Syntax)学:研究句子结构成分之间的相互关系和组成句子序列的规则 o I saw a girl with a telescope. “高个子”和“个子高” 包含两个部分“高”和 NP VP NP VP ”个子”,但这两种表述 PN NP PN VP PP 具有不同的关系类型 I saw NP PP “高个子”可以充当名词 NP P NP Det N NP 性元素,可以与动词“喜 saw Det N with Det N a girl with Det 欢”构成一个更大的句子 a girl a telescope telescope 成分; Isaw(a girl)with a telescope..Isaw(a girl with a telescope.)√而"个子高”是-个基本 我用望远镜看见一个女孩。 我看见一个戴望远镜的女孩。 的具有主谓的句子结构。 By英 NLP
By 郭凤英 研究内容