
第二章SOPC系统构架 2.1系统模块框图 SOPC系统的平台包括:Altera的Nios处理器、Avalon总线,片内外存储器以及外设模 块等。利用SOPC Builder,用户可以很方便地将处理器、存储器和其他外设模块连接起来, 形成一个完整的系统。其中,SOPC Builder中己包含了Nios处理器,以及其他一些常用的 外设P模块。用户也可以设计自己的外设P。 SOPC Builder会根据用户选择的P生成相应的HDL描述文件(系统模块文件),这些 文件与用户逻辑区域内的设计描述文件一起由Quartus软件综合,然后下载到FPGA内,这 样就构成了系统的硬件基础。 典型的SOPC系统模块框图如图2-1所示。 Address Avalon UARTO Instr. RTn Decoder Master/ ... Nios Slave CPU Data Port Timer 0 Interrupt Interfaces mer n 中4。 Controller On-Chip Debug Core SPIO SPIn Wait State 4 Generation GPIO 0 PIO n Off-Chip Data in Software Trace Multiplexer DMAO Memory MA n Master Arbitration Memory Interface Dynamic Bus Sizing User-Defined Interface ”年 Avalon Bus Module 图2-1S0PC系统结构 2.2 Nios CPU Nios CPU是一种采用流水线技术、单指令流的RISC处理器,如图2-2所示。Nios CPU采 用16位指令系统,其指令集具有以下特点: 。 拥有较大的窗口化的寄存器文件 Nios CPU包含512个内部通用寄存器,编译器使用这些寄存器来加速子程序调用和本地 变量的访问。 ·简单完整的指令集 32位和16位的Nios CPU都使用16位宽的指令,减小了代码文件的大小和指令存储器的 带宽。 ·强大的寻址模式 Nios指令集包含加载(Load)和存储(Store)指令,可使用编译器来加速对结构和本 地变量(栈)的访问
第二章 SOPC 系统构架 2. 1 系统模块框图 SOPC 系统的平台包括:Altera 的 Nios 处理器、Avalon 总线,片内外存储器以及外设模 块等。利用 SOPC Builder,用户可以很方便地将处理器、存储器和其他外设模块连接起来, 形成一个完整的系统。其中,SOPC Builder 中已包含了 Nios 处理器,以及其他一些常用的 外设 IP 模块。用户也可以设计自己的外设 IP。 SOPC Builder 会根据用户选择的 IP 生成相应的 HDL 描述文件(系统模块文件),这些 文件与用户逻辑区域内的设计描述文件一起由 Quartus 软件综合,然后下载到 FPGA 内,这 样就构成了系统的硬件基础。 典型的 SOPC 系统模块框图如图 2-1 所示。 图 2-1 SOPC 结构 2. : 拥有较大的窗口化的寄存器文件 通用寄存器,编译器使用这些寄存器来加速子程序调用和本地 变量的访问。 系统 2 Nios CPU Nios CPU是一种采用流水线技术、单指令流的RISC处理器,如图2-2所示。Nios CPU采 用16位指令系统,其指令集具有以下特点 · Nios CPU包含512个内部 · 简单完整的指令集 32位和16位的Nios CPU都使用16位宽的指令,减小了代码文件的大小和指令存储器的 带宽。 · 强大的寻址模式 Nios指令集包含加载(Load)和存储(Store)指令,可使用编译器来加速对结构和本 地变量(栈)的访问

·可扩展性 用户可以直接将自己的逻辑单元(作为用户定制指令)加入Nos算术逻辑单元(ALU) 中。在软件开发包(SDK)中,系统会相应生成访问该定制指令的宏(用C或汇编编写)。 data in data out 32 A Instruction Program Deooder Counter wait Clock Enable Operand Fetch read /write Interrupt irg年 Control ifetch Control General-Purpose Processor Register File byte enable reset clock 图2-2 Nios CPU结构图 大部分指令可以在一个时钟周期内完成。Nos软核处理器包括32位和16位两种体系 结构,见表2-1。 表2-1 Nios CPU体系结构 Nios CPU规格 32位Nios CPU 16位Nios CPU 数据总线宽度(位) 32 16 ALU宽度(位) 32 16 内部寄存器宽度(位) 32 16 地址总线宽度(位) 32 16 指令宽度(位) 16 16 Nios3.0CPU采用五级流水线结构,并具有独立的指令和数据存储器端口(Harvard存 储器结构)。指令和数据存储器的控制端口都作为Avalon总线的主端口。通过SOPC Builder, 用户可以把Nios总线主端口和任何Avalon总线的从端口(如存储器和外设)互联起来.SOPC Builder会自动加入相应的总线仲裁器。 2.2.1指令总线主端口 Nos指令总线主端口是16位宽、支持延时的主端口。此主端口仅仅负责从存储器中取指 令,但不执行任何写操作。因为主端口支持延时操作,所以对于慢速的存储器设备,它能执
· 可扩展性 系统会相应生成访问该定制指令的宏(用C或汇编编写)。 用户可以直接将自己的逻辑单元(作为用户定制指令)加入Nios算术逻辑单元(ALU) 中。在软件开发包(SDK)中, 图2-2 Nios CPU 结构图 表 2-1 Nios CPU 体系结构 大部分指令可以在一个时钟周期内完成。Nios 软核处理器包括 32 位和 16 位两种体系 结构,见表 2-1。 Nios CPU 规格 32 位 Nios CPU 16 位 Nios CPU 数据总线宽度(位) 32 16 ALU 宽度(位) 32 16 内部寄存器宽度(位) 32 16 地址总线宽度(位) 32 16 指令宽度(位) 16 16 Nios 3.0 CPU 采用五级流水线结构,并具有独立的指令和数据存储器端口(Harvard 存 储器结构)。指令和数据存储器的控制端口都作为 Avalon 总线的主端口。通过 SOPC Builder, 用户 2.2.1 指令总线主端口 Nios指令总线主端口是16位宽、支持延时的主端口。此主端口仅仅负责从存储器中取指 令, 可以把 Nios 总线主端口和任何 Avalon 总线的从端口(如存储器和外设)互联起来。SOPC Builder 会自动加入相应的总线仲裁器。 但不执行任何写操作。因为主端口支持延时操作,所以对于慢速的存储器设备,它能执

行延迟的读操作。指令主端口可以在上一条被取指令返回之前,发出新的取指请求。Nos CPU采用一个假设无分支的预测方法来发出预取指的地址。支持具有操作延迟的存储器,使 得存储器延迟对CPU的影响达到最小,并能在整体上提高系统的最高频率。只有分支预测失 败的时候,延迟才会较大。当访问慢速存储器的时候,0s指令主端口采用片内缓存来提高 平均取指速度。 SOPC Builder自动产生的Avalon总线,包含动态地址对齐逻辑。因此,Nios指令主端口 能连接8、16和32位宽存储器。 2.2.2数据总线主端口 对于32位体系结构,Nios数据主端口是32位宽:对于16位体系结构,则为16位宽。 数据主端口有以下三个用途: ·当CPU执行一个数据加载指令(LD,LDP,LDS)时,从存储器中读取数据。 ·当CPU执行一个数据存储指令(ST,STP,STS,ST8S,ST8D,ST16S,ST16D,STS8S, STS16S)时,向存储器中写入数据。 ·在软件异常或者硬件中断时,从中断向量表中取出中断向量。 因为在取得数据之前预测数据地址或继续执行指令是没有意义的,所以Nos数据主端口 不支持延迟操作。因此,数据主端口把从端口的延迟看作是等待周期。当Nos数据主端口被 连接到零等待周期的存储器时,数据加载和数据存储操作能在单个周期时钟内完成。为获得 最高的性能,在数据主端口和指令主端口共享的从端口上,必须使数据主端口优先级最高。 2.2.3缓冲存储器 Nios CPU中的指令主端口包含一个可选的指令缓存,数据主端口包含有一个可选的数 据缓存。通过SOPC Builder中的Nios处理器配置向导,用户能为系统配置指令和数据缓存。 缓冲存储器位于芯片内,大小可配置。数据缓存影响NOs的存储器访问。数据缓存存储最 近被访问过的数据字。只要可能,就使用缓存中的数据,从而减少对存储器的访问。 指令缓存和数据缓存都采用最简单的直接映像方式。即地址的低位被用来选择缓存的 行,如图2-3所示。在直接映象方式中,如果数据地址的索引(index)部分相同,这些数 据字将被映射到缓存中相同的行中。为了检测在缓存同一行中到底存储的是哪个字,字地址 的最高位作为标识(tag)。为了检测缓存中的数据是否有效,在缓存中每行还对应一个有效 位。 注意:数据缓存的行数等于数据缓存大小除以4。指令缓存的行数等于指令缓存的大小 除以2。 当执行装载指令时(LD、LDP和LDS),Nios CPU比较装载地址的高位和选中的缓存 行的标识。如果高位与标识匹配并且该行有效,则处理器将使用缓存中的数据而不再读取存 储器。因此加速了处理性能。当处理器使用缓存数据时,称作“命中”(it)。当缓存不包 含所需的数据时,称作“不命中”(miss)。 Nios CPU的写策略采用了最简单的写直达法(write-through)。即数据不但写入缓存, 同时也写入存储器。向缓存写数据时,缓存行的地址由写入地址的索引部分决定,这样随后 对于相同地址的读操作就会命中。此外,地址的高位作为标识写入,并置有效位。 当缓存失效时,处理器执行一次存储器读传输,找到所需的数据字,把这个字写到目的 寄存器中,同时写入缓存。这样,下次从相同地址读数据时就会命中
行延迟的读操作。指令主端口可以在上一条被取指令返回之前,发出新的取指请求。Nios CPU采用一个假设无分支的预测方法来发出预取指的地址。支持具有操作延迟的存储器,使 得存储器延迟对CPU的影响达到最小,并能在整体上提高系统的最高频率。只有分支预测失 败的时候,延迟才会较大。当访问慢速存储器的时候,Nios指令主端口采用片内缓存来提高 平均 辑。因此,Nios指令主端口 能连接8、16和32位宽存储器。 2.2.2 数据总线主端口 数据主端口有以下三个用途: 个数据加载指令(LD,LDP,LDS)时,从存储器中读取数据。 当 CPU 执行一个数据存储指令(ST, STP, STS, ST8S, ST8D, ST16S, ST16D, STS8S, STS 或者硬件中断时,从中断向量表中取出中断向量。 得 最高的性能,在数据主端口和指令主端口共享的从端口上,必须使数据主端口优先级最高。 数 直接映象方式中,如果数据地址的索引(index)部分相同,这些数 据字将被映射到缓存中相同的行中。为了检测在缓存同一行中到底存储的是哪个字,字地址 的最 意:数据缓存的行数等于数据缓存大小除以 4。指令缓存的行数等于指令缓存的大小 执行装载指令时(LD、LDP 和 LDS),Nios CPU 比较装载地址的高位和选中的缓存 行的 含所需的数据时,称作“不命中”(miss)。 法(write-through)。即数据不但写入缓存, 同时 分决定,这样随后 对于相同地址的读操作就会命中。此外,地址的高位作为标识写入,并置有效位。 存储器读传输,找到所需的数据字,把这个字写到目的 寄存 取指速度。 SOPC Builder自动产生的Avalon总线,包含动态地址对齐逻 对于 32 位体系结构,Nios 数据主端口是 32 位宽;对于 16 位体系结构,则为 16 位宽。 · 当 CPU 执行一 · 16S)时,向存储器中写入数据。 · 在软件异常 因为在取得数据之前预测数据地址或继续执行指令是没有意义的,所以Nios数据主端口 不支持延迟操作。因此,数据主端口把从端口的延迟看作是等待周期。当Nios数据主端口被 连接到零等待周期的存储器时,数据加载和数据存储操作能在单个周期时钟内完成。为获 2.2.3 缓冲存储器 Nios CPU 中的指令主端口包含一个可选的指令缓存,数据主端口包含有一个可选的 据缓存。通过 SOPC Builder 中的 Nios 处理器配置向导,用户能为系统配置指令和数据缓存。 缓冲存储器位于芯片内,大小可配置。数据缓存影响 Nios 的存储器访问。数据缓存存储最 近被访问过的数据字。只要可能,就使用缓存中的数据,从而减少对存储器的访问。 指令缓存和数据缓存都采用最简单的直接映像方式。即地址的低位被用来选择缓存的 行,如图 2-3 所示。在 高位作为标识(tag)。为了检测缓存中的数据是否有效,在缓存中每行还对应一个有效 位。 注 除以 2。 当 标识。如果高位与标识匹配并且该行有效,则处理器将使用缓存中的数据而不再读取存 储器。因此加速了处理性能。当处理器使用缓存数据时,称作“命中”(hit)。当缓存不包 Nios CPU 的写策略采用了最简单的写直达 也写入存储器。向缓存写数据时,缓存行的地址由写入地址的索引部 当缓存失效时,处理器执行一次 器中,同时写入缓存。这样,下次从相同地址读数据时就会命中
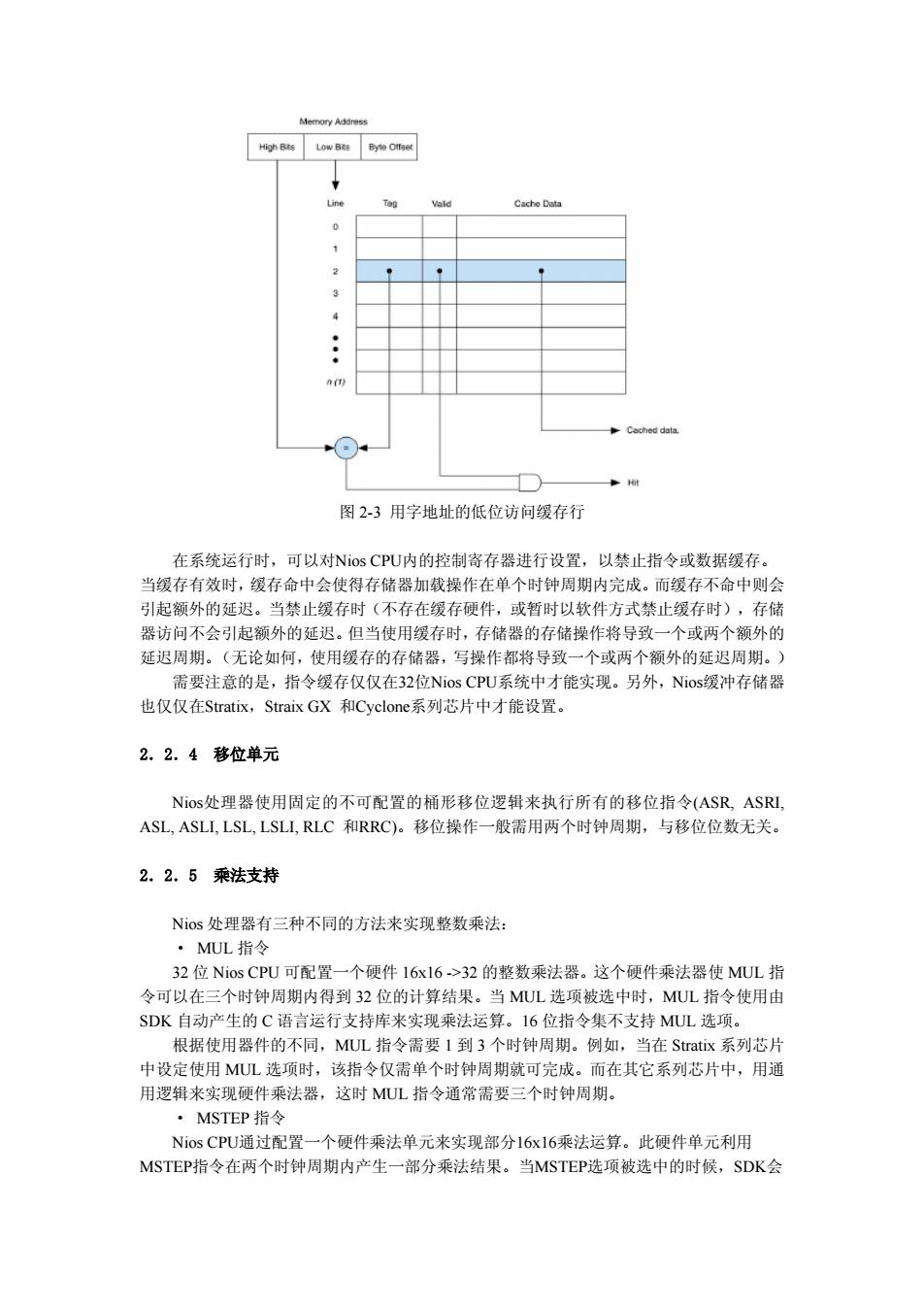
Memory Address High Bts Low Bts Byte Offse Line Vald Cache Data Csched dala. 图2-3用字地址的低位访问缓存行 在系统运行时,可以对Nios CPU内的控制寄存器进行设置,以禁止指令或数据缓存。 当缓存有效时,缓存命中会使得存储器加载操作在单个时钟周期内完成。而缓存不命中则会 引起额外的延迟。当禁止缓存时(不存在缓存硬件,或暂时以软件方式禁止缓存时),存储 器访问不会引起额外的延迟。但当使用缓存时,存储器的存储操作将导致一个或两个额外的 延迟周期。(无论如何,使用缓存的存储器,写操作都将导致一个或两个额外的延迟周期。) 需要注意的是,指令缓存仅仅在32位Nios CPU系统中才能实现。另外,Nos缓冲存储器 也仅仅在Stratix,Straix GX和Cyclone.系列芯片中才能设置。 2.2.4移位单元 Nios处理器使用固定的不可配置的桶形移位逻辑来执行所有的移位指令(ASR,ASRI, ASL,ASLL,LSL,LSLL,RLC和RRC)。移位操作一般需用两个时钟周期,与移位位数无关。 2.2.5乘法支持 Nos处理器有三种不同的方法来实现整数乘法: ·MUL指令 32位Nios CPU可配置一个硬件16x16->32的整数乘法器。这个硬件乘法器使MUL指 令可以在三个时钟周期内得到32位的计算结果。当MUL选项被选中时,MUL指令使用由 SDK自动产生的C语言运行支持库来实现乘法运算。16位指令集不支持MUL选项。 根据使用器件的不同,MUL指令需要1到3个时钟周期。例如,当在Stratix系列芯片 中设定使用MUL选项时,该指令仅需单个时钟周期就可完成。而在其它系列芯片中,用通 用逻辑来实现硬件乘法器,这时MUL指令通常需要三个时钟周期。 ·MSTEP指令 Nios CPU通过配置一个硬件乘法单元来实现部分16x16乘法运算。此硬件单元利用 MSTEP指令在两个时钟周期内产生一部分乘法结果。当MSTEP:选项被选中的时候,SDK会
图 2-3 用字地址的低位访问缓存行 可以对Nios CPU内的控制寄存器进行设置,以禁止指令或数据缓存。 缓存有效时,缓存命中会使得存储器加载操作在单个时钟周期内完成。而缓存不命中则会 引起 延 片中才能设置。 2.2 s处理器使用固定的不可配置的桶形移位逻辑来执行所有的移位指令(ASR, ASRI, ASL 2.2 令可 选项时,该指令仅需单个时钟周期就可完成。而在其它系列芯片中,用通 用逻 在系统运行时, 当 额外的 迟。当禁止缓存时(不存在缓存硬件,或暂时以软件方式禁止缓存时),存储 器访问不会引起额外的延迟。但当使用缓存时,存储器的存储操作将导致一个或两个额外的 延迟周期。(无论如何,使用缓存的存储器,写操作都将导致一个或两个额外的延迟周期。) 需要注意的是,指令缓存仅仅在32位Nios CPU系统中才能实现。另外,Nios缓冲存储器 也仅仅在Stratix,Straix GX 和Cyclone系列芯 .4 移位单元 Nio , ASLI, LSL, LSLI, RLC 和RRC)。移位操作一般需用两个时钟周期,与移位位数无关。 .5 乘法支持 Nios 处理器有三种不同的方法来实现整数乘法: · MUL 指令 32 位 Nios CPU 可配置一个硬件 16x16 ->32 的整数乘法器。这个硬件乘法器使 MUL 指 以在三个时钟周期内得到 32 位的计算结果。当 MUL 选项被选中时,MUL 指令使用由 SDK 自动产生的 C 语言运行支持库来实现乘法运算。16 位指令集不支持 MUL 选项。 根据使用器件的不同,MUL 指令需要 1 到 3 个时钟周期。例如,当在 Stratix 系列芯片 中设定使用 MUL 辑来实现硬件乘法器,这时 MUL 指令通常需要三个时钟周期。 · MSTEP 指令 Nios CPU通过配置一个硬件乘法单元来实现部分16x16乘法运算。此硬件单元利用 MSTEP指令在两个时钟周期内产生一部分乘法结果。当MSTEP选项被选中的时候,SDK会

自动生成C语言运行支持库来实现乘法操作。它通过连续的MSTEP操作序列来实现乘法操 作,例如用16个连续的MSTEP指令来实现16x16->32乘法。实现MSTEP所需要的硬件逻辑 资源少于CPU逻辑总资源的5%。由于数量比较小,因此一般默认选择MSTEP选项。16位指 令集不支持此选项。 ·软件乘法器 当MSTEP和MUL选项都没被选择时,由SDK自动产生的C语言运行支持库使用移 位和加指令来实现整数乘法。软件乘法器消耗最少的CPU逻辑资源,但其执行速度最低。 2.2.6中断支持 Nos3.0CPU允许用户取消对陷阱指令、硬中断或内部异常的支持。这样做的目的是把 NiOs系统配置成一个最简单的控制系统(不运行复杂软件)。在这种配置下,Nios处理器: ·不包括irq输入引脚。 ·无异常处理(因为陷阱指令没定义)。 ·当加载或存储指令使寄存器文件上溢或下溢时,不产生异常。 仅当有如下要求时才能取消陷阱指令、硬中断或内部异常: ·需要最小化的Nios CPU核 ·确信用户的应用软件不产生寄存器窗口上溢或下溢异常。即,子程序调用深度小于 寄存器窗口数。 ·系统内没有任何硬件中断源。 ·汇编语言代码不包含陷阱指令。 2.2.7Nios片上调试棋块 Nios CPU有一个可选的片上JTAG调试模块,用于实现调试工具和Nios CPU的通讯。调 试模块含有First Silicon Solution(FS2)公司设计的IP核。在Nios CPU中,此调试模块被称做 Nios OCI(On-Chip Instrumentation)调试模块。Nios OCIi调试模块可以实现运行控制、硬件 断点和软件跟踪。 一些更先进的调试特性需要外部JTAG调试硬件或第三方调试器。除了调试功能之外, Nios OCI调试模块也能被用作标准的输入输出。 2.2.8开发环境 Nios开发环境包含GNUPro编译器和Cygnus的调试器,这些都是开放的符合工业标准 的C/C+开发工具包。其中GNUPro工具包还包括了C/C++编译器、宏汇编器、连接器、调 试器、二进制工具及库等。 2.3 Avalon总线 Avalon总线是一种相对简单的总线结构,主要用于连接片内处理器与外设,以构成片 上可编程系统(SOPC)。它描述了主从构件间的端口连接关系,以及构件间通讯的时序关系。 Avalon总线规范提供了各种选项,来剪裁总线信号和时序,以满足不同类型外设的需要。 SOPC Builder自动产生Avalon总线,Avalon总线也包括许多特性和约定,用以支持SOPC Builder软件自动生成系统、总线和外设
自动 如用16个连续的 MSTEP指令来实现16x16->32乘法。实现MSTEP所需要的硬件逻辑 资源 耗最少的 CPU 逻辑资源,但其执行速度最低。 指令使寄存器文件上溢或下溢时,不产生异常。 件不产生寄存器窗口上溢或下溢异常。即,子程序调用深度小于 Nios CPU有一个可选的片上JTAG调试模块,用于实现调试工具和Nios CPU的通讯。调 试模块含有First Silicon Solution(FS2)公司设计的IP核。在Nios CPU中,此调试模块被称做 Nios OCI(On-Chip Instrumentation)调试模块。Nios OCI调试模块可以实现运行控制、硬件 断点和软件跟踪。 一些更先进的调试特性需要外部 JTAG 调试硬件或第三方调试器。除了调试功能之外, Nios OCI 调试模块也能被用作标准的输入输出。 2.2.8 开发环境 Nios 开发环境包含 GNUPro 编译器和 Cygnus 的调试器,这些都是开放的符合工业标准 的 C/C++开发工具包。其中 GNUPro 工具包还包括了 C/C++编译器、宏汇编器、连接器、调 试器、二进制工具及库等。 3 Avalon 总线 Avalon 总线是一种相对简单的总线结构,主要用于连接片内处理器与外设,以构成片 OPC)。它描述了主从构件间的端口连接关系,以及构件间通讯的时序关系。 Aval ,用以支持 SOPC Buil r 软件自动生成系统、总线和外设。 生成C语言运行支持库来实现乘法操作。它通过连续的MSTEP操作序列来实现乘法操 作,例 少于CPU逻辑总资源的5%。由于数量比较小,因此一般默认选择MSTEP选项。16位指 令集不支持此选项。 · 软件乘法器 当 MSTEP 和 MUL 选项都没被选择时,由 SDK 自动产生的 C 语言运行支持库使用移 位和加指令来实现整数乘法。软件乘法器消 2.2.6 中断支持 Nios 3.0 CPU 允许用户取消对陷阱指令、硬中断或内部异常的支持。这样做的目的是把 Nios 系统配置成一个最简单的控制系统(不运行复杂软件)。在这种配置下,Nios 处理器: · 不包括 irq 输入引脚。 · 无异常处理(因为陷阱指令没定义)。 · 当加载或存储 仅当有如下要求时才能取消陷阱指令、硬中断或内部异常: · 需要最小化的Nios CPU核 · 确信用户的应用软 寄存器窗口数。 · 系统内没有任何硬件中断源。 · 汇编语言代码不包含陷阱指令。 2.2.7 Nios 片上调试模块 2. 上可编程系统(S on 总线规范提供了各种选项,来剪裁总线信号和时序,以满足不同类型外设的需要。 SOPC Builder 自动产生 Avalon 总线,Avalon 总线也包括许多特性和约定 de