
Optimizing existing large codebase Measuire Modemise Mem threads Finding bottlenecks Understand where we can improve o analyze each part of the software o in order to find out where most time is spent o and understand whether it can be improved Most usual bottlenecks From biggest to lowest impact(usually) 。10 ●Memory 。Parallelization o Low level behavior:vectorization,cache behavior,high CPl erf tool bottlenecks 12/62 S.Ponce-CERN
Optimizing existing large codebase 12 / 62 S. Ponce - CERN Measure Modernize Mem threads low level c/c perf tools bottlenecks Finding bottlenecks Understand where we can improve analyze each part of the software in order to find out where most time is spent and understand whether it can be improved Most usual bottlenecks From biggest to lowest impact (usually) IO Memory Parallelization Low level behavior : vectorization, cache behavior, high CPI

Optimizing existing large codebase Measiare Modernice Mem threads low Make use of latest C++features oC++has evolved dramatically between 2010 and now o three new versions:C++11,C++14,C++17 o a LOT of new features targeting performance ●move semantic threading library variadic templates vectorization coming o converting existing code may already brings speed see Danilo's course for technical details o see my extended C++course if you're not at ease with the language 14/62 S.Ponce-CERN
Optimizing existing large codebase 14 / 62 S. Ponce - CERN Measure Modernize Mem threads low level c/c Make use of latest C++features C ++has evolved dramatically between 2010 and now three new versions : C++11, C++14, C++17 a LOT of new features targeting performance move semantic threading library variadic templates vectorization coming ! converting existing code may already brings speed see Danilo’s course for technical details see my extended C++course if you’re not at ease with the language

Optimizing existing large codebase Measire Modernice Mem threads lom Cleanup your code o While reviewing the code for converting to C++17: ●drop unused code 。drop unnecessary code e.g.do I really need to sort by hits here drop too generic APls if they are finally not needed replace virtual inheritance with templating when possible o consider dropping use of unmaintained libraries o It is very often surprising how much you gain there 15/62 S.Ponce-CERN
Optimizing existing large codebase 15 / 62 S. Ponce - CERN Measure Modernize Mem threads low level c/c Cleanup your code While reviewing the code for converting to C++17 : drop unused code drop unnecessary code e.g. do I really need to sort by hits here ? drop too generic APIs if they are finally not needed replace virtual inheritance with templating when possible consider dropping use of unmaintained libraries It is very often surprising how much you gain there
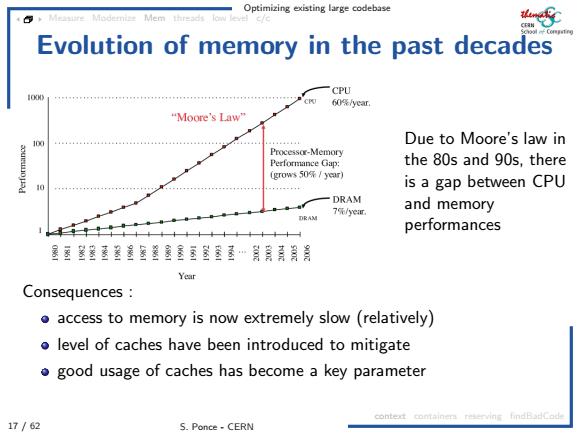
Optimizing existing large codebase 4 Mem threads Evolution of memory in the past decades CPU 60径yer “oore'sLaw 10国 Due to Moore's law in Processor-Memory Performance Gap: the 80s and 90s,there (grows50年/3r) 0 is a gap between CPU -DRAM 7第/小e亚 and memory DRAM performances 家委墨鉴墓鉴墨鉴墨墨鑫玉墨屋…青昌 Year Consequences o access to memory is now extremely slow(relatively) o level of caches have been introduced to mitigate good usage of caches has become a key parameter context comtainers reserving findBadCode 17/62 S.Ponce-CERN
Optimizing existing large codebase 17 / 62 S. Ponce - CERN Measure Modernize Mem threads low level c/c context containers reserving findBadCode Evolution of memory in the past decades Due to Moore’s law in the 80s and 90s, there is a gap between CPU and memory performances Consequences : access to memory is now extremely slow (relatively) level of caches have been introduced to mitigate good usage of caches has become a key parameter
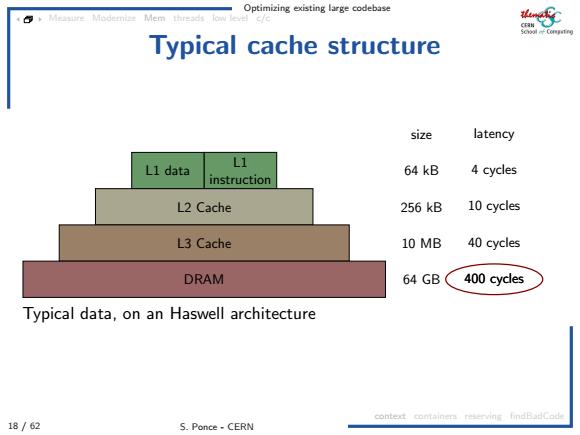
Optimizing existing large codebase Mem threads To Typical cache structure size latency Ll data L1 64 kB 4 cycles instruction L2 Cache 256kB 10 cycles L3 Cache 10 MB 40 cycles DRAM 64 GB 400 cycles Typical data,on an Haswell architecture context comtainers reserving findBadCode 18/62 S.Ponce-CERN
Optimizing existing large codebase 18 / 62 S. Ponce - CERN Measure Modernize Mem threads low level c/c context containers reserving findBadCode Typical cache structure L1 data L1 instruction L2 Cache L3 Cache DRAM size latency 64 kB 4 cycles 256 kB 10 cycles 10 MB 40 cycles 64 GB 400 cycles Typical data, on an Haswell architecture