编泽原理 风歧文洁和语法制导翻译 只要文法的属性是非循环定义的,则每一次扫描至少 有一个属性值被计算出来。 慧如果语法树有个结点(因此最多有0()个属性), 最坏的情况整个遍历需O)时间。 第26页
编译原理 第26页 属性文法和语法制导翻译 只要文法的属性是非循环定义的,则每一次扫描至少 有一个属性值被计算出来。 如果语法树有n个结点(因此最多有O(n)个属性), 最坏的情况整个遍历需O(n²)时间

编泽原理 马性文洁率和怀法制导翻译 例:S有继承属性a,综合属性b;X有继承属性c,综合属性d;Y 有继承属性e、综合属性f;z有继承属性h、综合属性g。 表6.3 语义规则中有较复杂的依赖关系 产生式 语义规则 S→+Yz Z.h:=S.a X.c:=Z.g s.b:=.d-2 Y.e:=S.b X→x .d:=2*x.c t→y Y.f:=7.e*3 Z-z Z.g:=Z.h+1 第27页
编译原理 第27页 属性文法和语法制导翻译 例:S有继承属性a,综合属性b;X有继承属性c,综合属性d;Y 有继承属性e、综合属性f;z有继承属性h、综合属性g
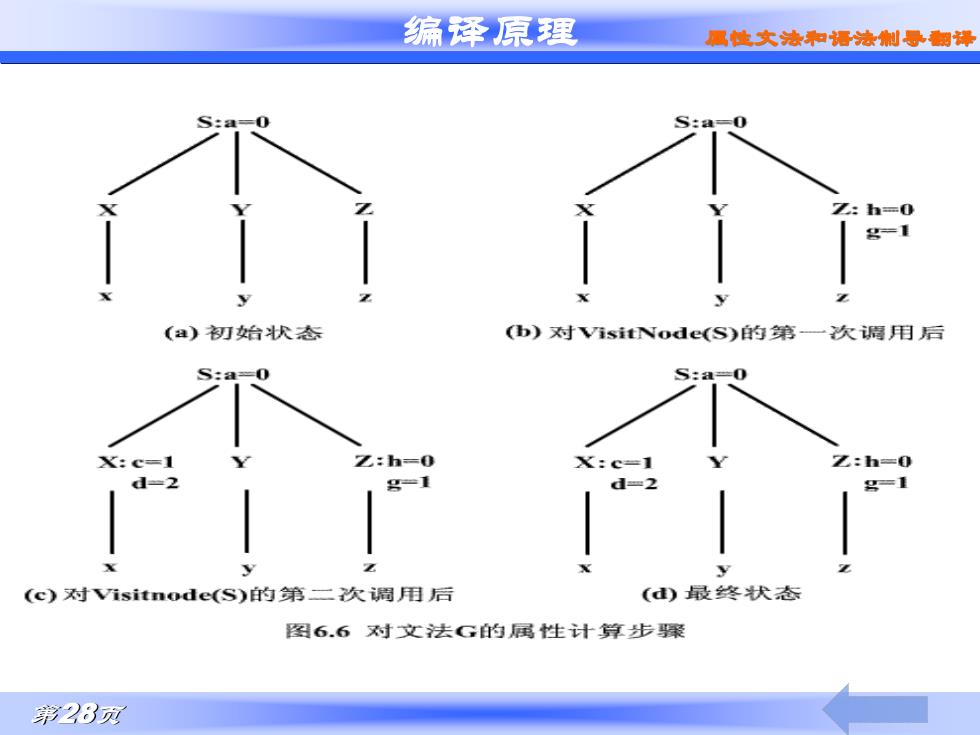
编泽原理 具使文洁和语法制导制译 Sa=0 Z:h=0 g=1 (a)初始状态 (b)对visitNode(S)的第次调用后 S:a=0 S:a=0 X:c=1 Z:h=0 X:c=1 Z:h=0 2 g=1 d2 g=1 (c)对visitnode(S)的第二次周用后 ()最终状态 图6.6对文法G的属性计算步聚 第28列
编译原理 第28页 属性文法和语法制导翻译
编译原理 马位文洁和语洁制导制译 一遍扫描的处理方法 一遍扫描的处理方法是在语法分析的同时计算属性值,而 不是语法分析构造语法树之后进行属性的计算,而且无需 构造实际的语法树(如果有必须,当然也可以实际构造)。 第29页
编译原理 第29页 属性文法和语法制导翻译 一遍扫描的处理方法 一遍扫描的处理方法是在语法分析的同时计算属性值,而 不是语法分析构造语法树之后进行属性的计算,而且无需 构造实际的语法树(如果有必须,当然也可以实际构造)
编泽原理 属此文法和语法制导制译 因为一遍扫描的处理方法与语法分析器的相互作用,它与 下面两个因素密切相关: (1)所采用的语法分析方法; (2)属性的计算次序。 L-属性文法可用于一遍扫描的自上而下分析,而$-属性文 法适合于一遍扫描的自下而上分析。 第30
编译原理 第30页 属性文法和语法制导翻译 因为一遍扫描的处理方法与语法分析器的相互作用,它与 下面两个因素密切相关: (1)所采用的语法分析方法; (2)属性的计算次序。 L-属性文法可用于一遍扫描的自上而下分析,而S-属性文 法适合于一遍扫描的自下而上分析