
编泽原理 具使文洁和语法制导制译 基于属性文法的处理方法 基于属性文法的处理过程通常是: 对单词符号串进行语法分析,构造语法分析树, 然后根据需要遍历语法树并在语法树的各结点处 按语义规则进行计算。 这种由源程序的语法结构所驱动的处理办法就是 语法制导翻译法。 墨语义规则的计算可能产生代码、在符号表中存放 信息、给出错误信息或执行任何其他动作。对输 入符号串的翻译也就是根据语义规则进行计算的 结果。 输入串→语法树→依赖图→语义计算次序 第6列
编译原理 第16页 属性文法和语法制导翻译 基于属性文法的处理方法 基于属性文法的处理过程通常是: 对单词符号串进行语法分析,构造语法分析树, 然后根据需要遍历语法树并在语法树的各结点处 按语义规则进行计算。 这种由源程序的语法结构所驱动的处理办法就是 语法制导翻译法。 语义规则的计算可能产生代码、在符号表中存放 信息、给出错误信息或执行任何其他动作。对输 入符号串的翻译也就是根据语义规则进行计算的 结果。 输入串→ 语法树→ 依赖图→ 语义计算次序

编译原理 马位文洁和语洁制导制译 依赖图 如果在一棵语法树中一个结点的属性b依赖于属性c,那 么这个结点处计算b的语义规则必须在确定c的语义规则 之后使用。 在一棵语法树中的结点的继承属性和综合属性之间的相 互依赖关系可以由称作依赖图的一个有向图来描述。 第引7负
编译原理 第17页 属性文法和语法制导翻译 依赖图 如果在一棵语法树中一个结点的属性b依赖于属性c,那 么这个结点处计算b的语义规则必须在确定c的语义规则 之后使用。 在一棵语法树中的结点的继承属性和综合属性之间的相 互依赖关系可以由称作依赖图的一个有向图来描述

编泽原理 属饮文法和语法制导翻译 在为一棵语法树构造依赖图以前, 我们为每一个包含过 程调用的语义规则引入一个虚综合属性b,这样把每一 个语义规则都写成 b:=f(c1,c2,,ck) 的形式。依赖图中为每一个属性设置一个结点,如果属 性b依赖于属性c,则从属性c的结点有一条有向边连到 属性的结点。更详细地说,对于给定的一棵语法分析 树、依赖图是按下面步骤构造出来的: 第8列
编译原理 第18页 属性文法和语法制导翻译 在为一棵语法树构造依赖图以前,我们为每一个包含过 程调用的语义规则引入一个虚综合属性b,这样把每一 个语义规则都写成 b:=f( c1,c2,…,ck) 的形式。依赖图中为每一个属性设置一个结点,如果属 性b依赖于属性c,则从属性c的结点有一条有向边连到 属性b的结点。更详细地说,对于给定的一棵语法分析 树、依赖图是按下面步骤构造出来的:

编译原理 马处文洁和语洁制导圆梯 for语法树中每一结点ndo for结点n的文法符号的每一个属性ado 为a在依赖图中建立一个结点; for语法树中每一个结点ndo for结点n所用产生式对应的每一个语义规则 b:=f(c1,c2,...ck)do for i:=1 to k do 从ci结点到b结点构造一条有向边; 第19页
编译原理 第19页 属性文法和语法制导翻译 for 语法树中每一结点n do for 结点n的文法符号的每一个属性a do 为a在依赖图中建立一个结点; for 语法树中每一个结点n do for 结点n所用产生式对应的每一个语义规则 b:=f(c1,c2,…,ck) do for i:=1 to k do 从ci结点到b结点构造一条有向边;
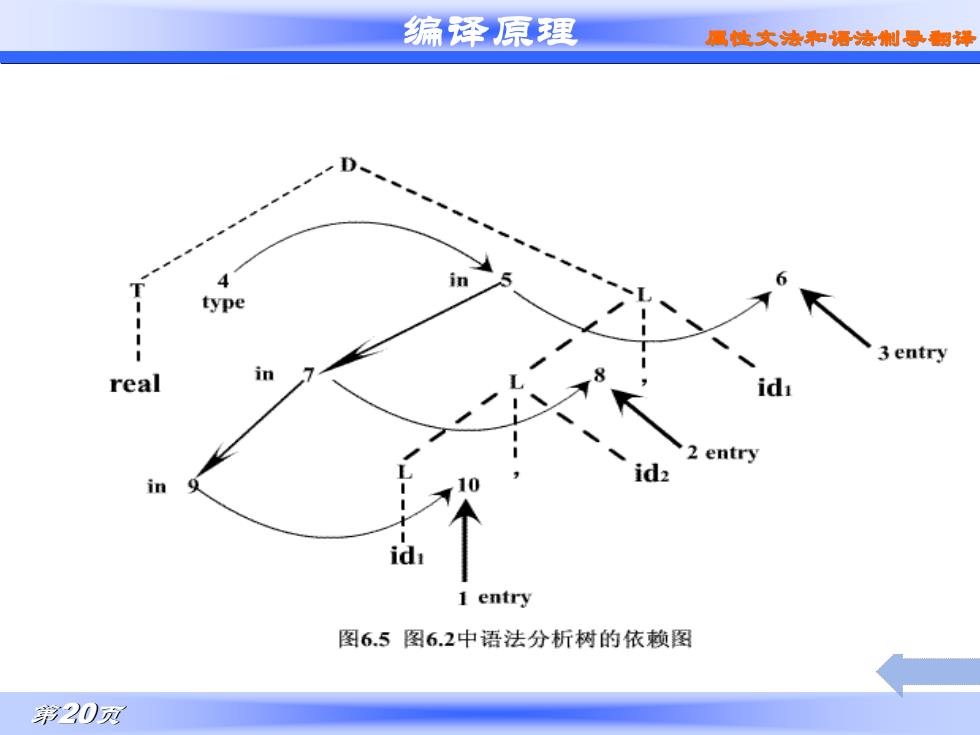
编泽原理 具使文洁和语法制导制译 type 3 entry real in 2 entry id in id, 1 entry 图6.5图6.2中语法分析树的依赖图 第20
编译原理 第20页 属性文法和语法制导翻译