
无监督学习任务一聚类 口在“无监督学习”任务中研究最多、应用最广. 聚类目标:将数据集中的样本划分为若干个通常不相交的子集 (“簇”,cluster). ▣聚类既可以作为一个单独过程(用于找寻数据内在的分布结构), 也可作为分类等其他学习任务的前驱过程
p 在“无监督学习”任务中研究最多、应用最广. p 聚类目标:将数据集中的样本划分为若干个通常不相交的子集 (“簇” ,cluster). p 聚类既可以作为一个单独过程(用于找寻数据内在的分布结构), 也可作为分类等其他学习任务的前驱过程
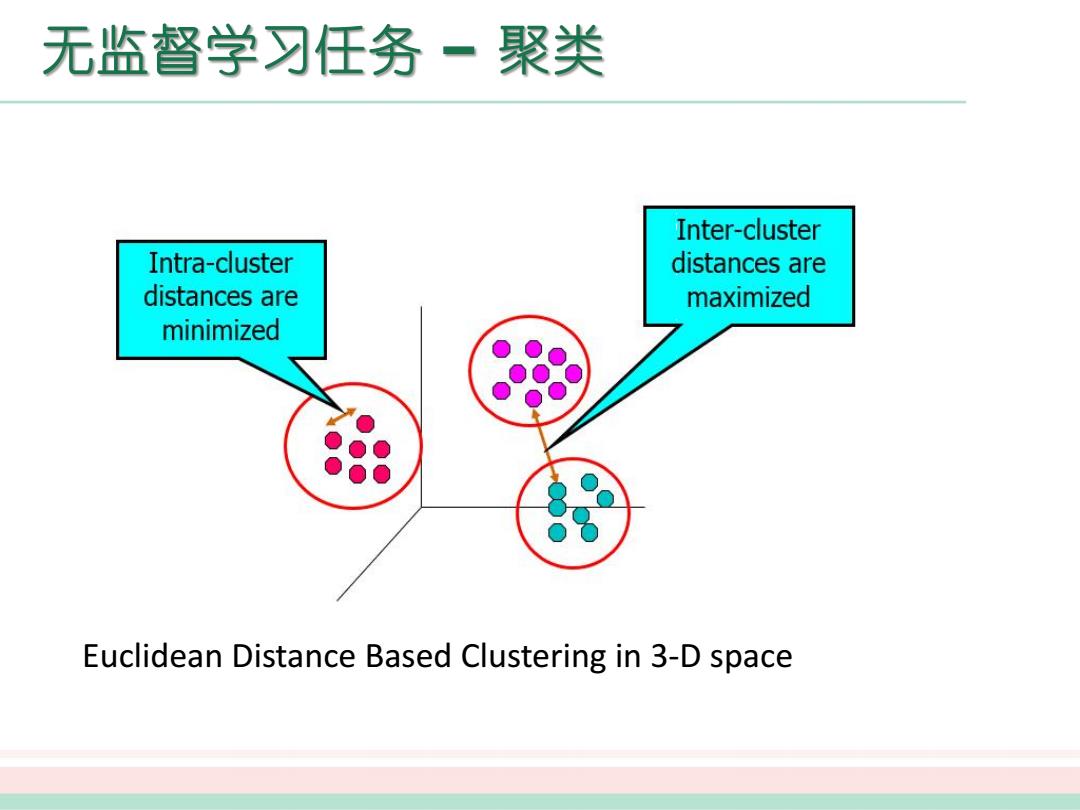
无监督学习任务一聚类 Inter-cluster Intra-cluster distances are distances are maximized minimized Euclidean Distance Based Clustering in 3-D space
Euclidean Distance Based Clustering in 3-D space

无监督学习任务·聚类 ▣形式化描述 假定样本集 D={x1,x2,·,xm}包含m个无标记样本,每个样本 x=(x1;x2;··;cn)是一个n维的特征向量,聚类算法将样本集 D划分成个不相交的簇{Cl=1,2,,}。其中C∩C1=p,且 D=U1C。 相应地,用入∈{1,2,…,}表示样本x1的“簇标记”(即cluster label),即xj∈C,。于是,聚类的结果可用包含m个元素的簇标记 向量入={入1;λ2;·;入m}表示
p 形式化描述 假定样本集 包含 个无标记样本,每个样本 是一个 维的特征向量,聚类算法将样本集 划分成 个不相交的簇 。其中 ,且 。。 相应地,用 表示样本 的“簇标记”(即cluster label),即 。于是,聚类的结果可用包含 个元素的簇标记 向量 表示

性能度量 聚类性能度量,亦称为聚类“有效性指标”(validity index) 口直观来讲: 我们希望“物以类聚”,即同一簇的样本尽可能彼此相似,不同簇的样本尽 可能不同。换言之,聚类结果的“簇内相似度”(intra-cluster similarity) 高,且“簇间相似度”(inter-cluster similarity)低,这样的聚类效果较好
p 聚类性能度量,亦称为聚类“有效性指标”(validity index) p 直观来讲: 我们希望“物以类聚” ,即同一簇的样本尽可能彼此相似,不同簇的样本尽 可能不同。换言之,聚类结果的“簇内相似度”(intra-cluster similarity) 高,且“簇间相似度”(inter-cluster similarity)低,这样的聚类效果较好

性能度量 ▣聚类性能度量: ●外部指标(external index) 将聚类结果与某个“参考模型”(reference model)进行比较。 ● 内部指标(internal index) 直接考察聚类结果而不用任何参考模型
p 聚类性能度量: l 外部指标 (external index) 将聚类结果与某个“参考模型”(reference model)进行比较。 l 内部指标 (internal index) 直接考察聚类结果而不用任何参考模型