
标记说明 ●描述语义动作时,需要赋予每个文法符号X(终结符或者 非终结符)以种种不同方面的值,如X.TYPE(类型) X.VAL(值)等。 ●一个产生式中同一符号多次出现,用上角标来区分。 E→E+E 表示为 E→E(1)+E2) ●每个产生式的语义动作,写在该产生式之后的花括号
标记说明 ⚫描述语义动作时,需要赋予每个文法符号X(终结符或者 非终结符)以种种不同方面的值,如X.TYPE(类型), X.VAL(值)等。 ⚫一个产生式中同一符号多次出现,用上角标来区分。 E → E + E 表示为 E → E (1) + E(2) ⚫每个产生式的语义动作,写在该产生式之后的花括号 内
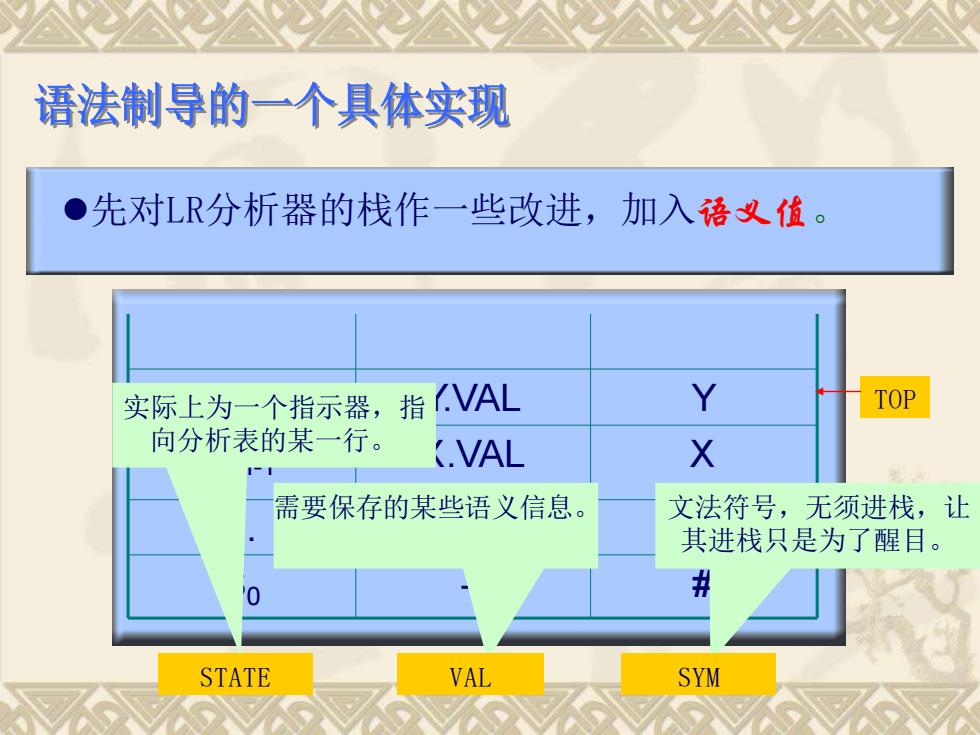
语法制导的一个具体实现 ●先对LR分析器的栈作一些改进,加入语义值。 实际上为一个指示器,指 .VAL Y TOP 向分析表的某一行。 (.VAL X I-I 需要保存的某些语义信息。 文法符号,无须进栈,让 其进栈只是为了醒目。 # STATE VAL SYM
S0 -- # … … … Sm-1 X.VAL X Sm Y.VAL Y 文法符号,无须进栈,让 其进栈只是为了醒目。 需要保存的某些语义信息。 实际上为一个指示器,指 向分析表的某一行。 ⚫先对LR分析器的栈作一些改进,加入语义值。 STATE VAL SYM TOP

●文法及其语义动作 (0)S’→E {print E.VAL} (1)E→E1)+E②) {E.VAL:=E(1).VAL+E(2).VAL} (2)E→E(1)*E2) {E.VAL:=E(1).VAL*E (2).VAL} (3)E>(E1)》 E.VAL:=E (1).VAL) (4)E→n E.VAL:=LEXVAL
⚫文法及其语义动作 (0)S’→ E {print E.VAL} (1)E→E (1)+E(2) {E.VAL:=E(1).VAL+E(2).VAL} (2)E→E (1)*E(2) {E.VAL:=E(1).VAL*E(2).VAL} (3)E→(E(1)) {E.VAL:=E(1).VAL} (4)E→n {E.VAL:=LEXVAL}

上述的语义动作等于给出了计算由十、*组成 的整数算术式的过程。其相应的程序段如下: (0)S’→E print VAL[TOP] (1)E->E(D+E(2)VAL[TOP]:=VAL [TOP]+VAL[TOP+2] (2)E->E(1)*E (2)VAL [TOP]:=VAL [TOP]*VAL [TOP+2] (3)E→(E(1) VAL[TOP]:=VAL [TOP+1] (4)E→n VAL [TOP]:=LEXVAL 若把语义动作改为产生中间代码的动作,就能随着分析 的进展逐步生成中间代码
上述的语义动作等于给出了计算由+、*组成 的整数算术式的过程。其相应的程序段如下: (0)S’→ E print VAL[TOP] (1)E→E (1)+E(2) VAL[TOP]:=VAL[TOP]+VAL[TOP+2] (2)E→E (1)*E(2) VAL[TOP]:=VAL[TOP]*VAL[TOP+2] (3)E→(E(1)) VAL[TOP]:=VAL[TOP+1] (4)E→n VAL[TOP]:=LEXVAL 若把语义动作改为产生中间代码的动作,就能随着分析 的进展逐步生成中间代码

中间代码的必要性 大部分的编译器都不直接产生目标代码,虽然这 是可以实现的,但是产生的代码不是最优的。因 为这涉及到寄存器的分配问题,在语义分析阶段, 很难有效地分配它们
大部分的编译器都不直接产生目标代码,虽然这 是可以实现的,但是产生的代码不是最优的。因 为这涉及到寄存器的分配问题,在语义分析阶段, 很难有效地分配它们。 中间代码的必要性