
Structuring data for efficient I/O format compress addr stats c/e Data structure by example -row storage Naive structure o You arrange your captors in a sequential order according to the detector geometry Each minute,you create a new "row"of data,with 10K floats representing temperatures given by the captors,in that order Time (mn) Captor 1 Captor 2 Captor c 0 ao bo 20 1 a1 b1 Z1 n an bn Zn File content a0bo.2oa1b1…z1…anbn.zn o 6/42 S.Ponce-CERN
Structuring data for efficient I/O 6 / 42 S. Ponce - CERN format compress addr state c/c row/col Data structure by example - row storage Naive structure You arrange your captors in a sequential order according to the detector geometry Each minute, you create a new “row” of data, with 10K floats representing temperatures given by the captors, in that order Time (mn) Captor 1 Captor 2 ... Captor c 0 a0 b0 ... z0 1 a1 b1 ... z1 ... ... ... ... ... n an bn ... zn File content a0 b0 ... z0 a1 b1 ... z1 ... an bn ... zn
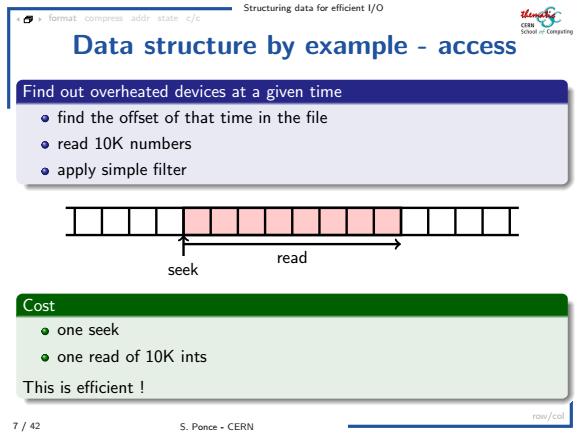
Structuring data for efficient l/O 4 format compress addr state c/e Data structure by example-access Find out overheated devices at a given time o find the offset of that time in the file ●read10 Knumbers o apply simple filter read seek Cost 。one seek o one read of 10K ints This is efficient row/cal 7/42 S.Ponce-CERN
Structuring data for efficient I/O 7 / 42 S. Ponce - CERN format compress addr state c/c row/col Data structure by example - access Find out overheated devices at a given time find the offset of that time in the file read 10K numbers apply simple filter seek read Cost one seek one read of 10K ints This is efficient !

Structuring data for efficient I/O format compre= Data structure by example access (2 Graph the temperature evolution of a given device o read 43.2K numbers from the file,every 40K bytes ●graph them → 下→ ead "read read see seek seek Cost o43.2K reads of 4 bytes and 43.2K seeks o on top typical block size in a filesystem is 8k you will probably read effectively 20%of the file o actually reading the whole file will be more efficient Here the structure of our data is a killer 8/42 S.Ponce-CERN
Structuring data for efficient I/O 8 / 42 S. Ponce - CERN format compress addr state c/c row/col Data structure by example - access (2) Graph the temperature evolution of a given device read 43.2K numbers from the file, every 40K bytes graph them seekread seekread seekread Cost 43.2K reads of 4 bytes and 43.2K seeks ! on top typical block size in a filesystem is 8k you will probably read effectively 20% of the file ! actually reading the whole file will be more efficient Here the structure of our data is a killer
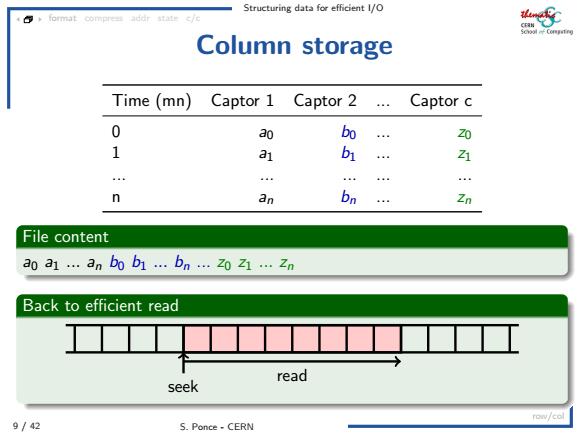
Structuring data for efficient I/O 4 format compress addr state c/c 花5 Column storage Time (mn) Captor 1 Captor 2 Captor c 0 ao bo Zo 1 a1 b1 41 4 。。。 n an bn Zn File content a0a1.an bo b1…bn…z021…Zn Back to efficient read seek read row/cal 9/42 S.Ponce-CERN
Structuring data for efficient I/O 9 / 42 S. Ponce - CERN format compress addr state c/c row/col Column storage Time (mn) Captor 1 Captor 2 ... Captor c 0 a0 b0 ... z0 1 a1 b1 ... z1 ... ... ... ... ... n an bn ... zn File content a0 a1 ... an b0 b1 ... bn ... z0 z1 ... zn Back to efficient read seek read

Structuring data for efficient I/O 4 format compre addr. Row vs column storage Definition Row storage respects internal structure of the data and puts the different items one next in a sequence Column storage breaks the internal structure of the data to collate similar pieces Why to use column o to optimize I/O in general and avoid scattered reads o to optimize data compression o to optimize parallelization of processing Drawback of column storage o a column organized file cannot be updated easily o column storage is usually created from row storage in a postprocessing phase. 10
Structuring data for efficient I/O 10 / 42 S. Ponce - CERN format compress addr state c/c row/col Row vs column storage Definition Row storage respects internal structure of the data and puts the different items one next in a sequence Column storage breaks the internal structure of the data to collate similar pieces Why to use column ? to optimize I/O in general and avoid scattered reads to optimize data compression to optimize parallelization of processing Drawback of column storage a column organized file cannot be updated easily column storage is usually created from row storage in a postprocessing phase