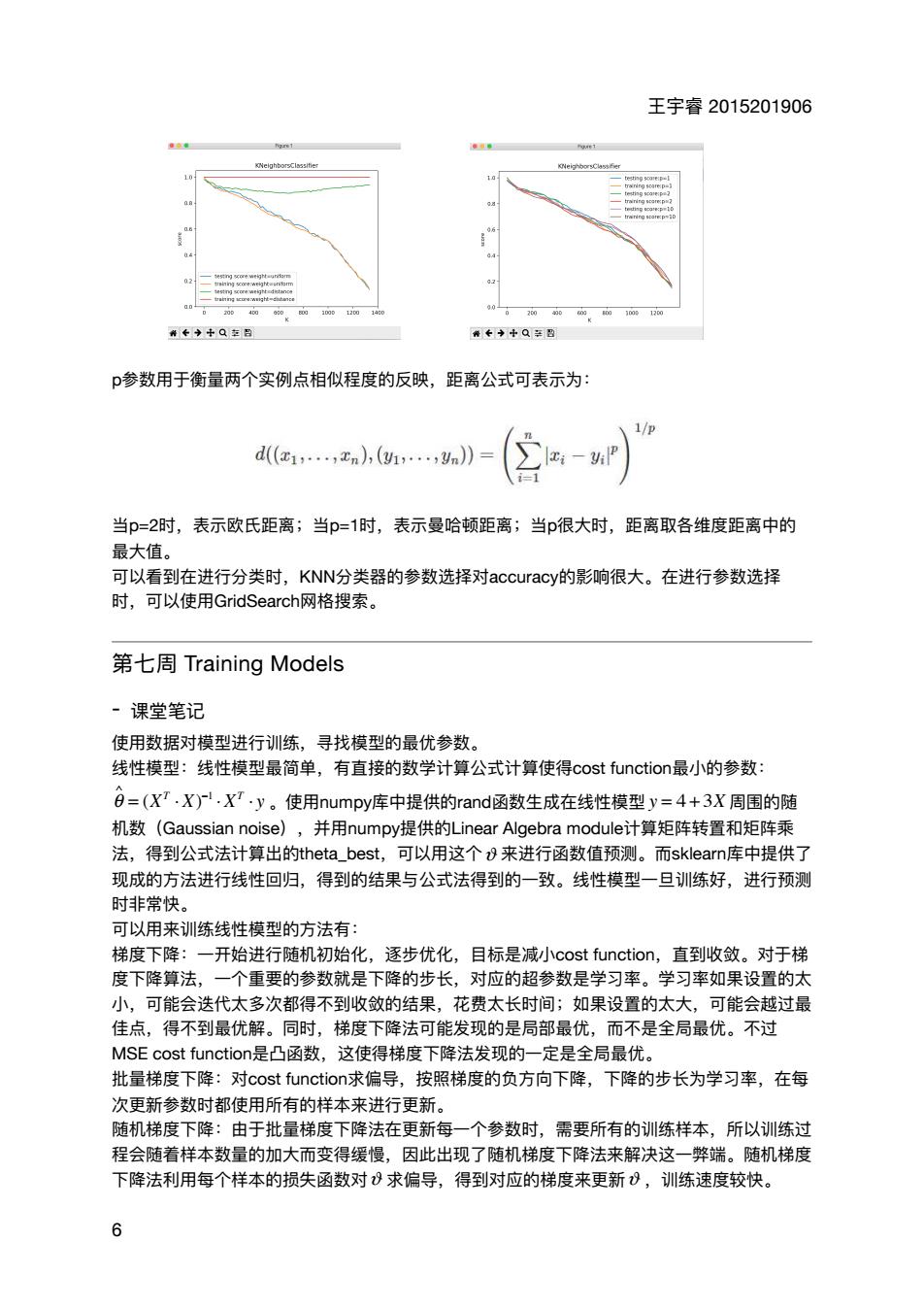
王宇睿2015201906 0←◆+Q包吕 0+++Q多盟 p参数用于衡量两个实例点相似程度的反映,距离公式可表示为: 1/0 d(1,,xn,(…,y》= ∑-P】 当p=2时,表示欧氏距离;当p=1时,表示曼哈顿距离;当p很大时,距离取各维度距离中的 最大值。 可以看到在进行分类时,KNN分类器的参数选择对accuracy的影响很大。在进行参数选择 时,可以使用GridSearch网格搜索。 第七周Training Models ·课堂笔记 使用数据对模型进行训练,寻找模型的最优参数。 线性模型:线性模型最简单,有直接的数学计算公式计算使得cost function最小的参数: 日=(XT,X).XT·y。使用numpy库中提供的rand函数生成在线性模型y=4+3X周围的随 机数(Gaussian noise) ,并用numpy提供的Linear Algebra module计算矩阵转置和矩阵乘 法,得到公式法计算出的theta_best,可以用这个&来进行函数值预测。而sklearn库中提供了 现成的方法进行线性回归,得到的结果与公式法得到的一致。线性模型一旦训练好,进行预测 时非常快。 可以用来训练线性模型的方法有: 梯度下降:一开始进行随机初始化,逐步优化,目标是减小cost function,直到收敛。对于梯 度下降算法,一个重要的参数就是下降的步长,对应的超参数是学习率。学习率如果设置的太 小,可能会迭代太多次都得不到收敛的结果,花费太长时间;如果设置的太大 ,可能会越过最 佳点,得不到最优解。同时,梯度下降法可能发现的是局部最优,而不是全局最优。不过 MSE cost function是凸函数,这使得梯度下降法发现的一定是全局最优。 批量梯度下降:对cost function求偏导,按照梯度的负方向下降,下降的步长为学习率,在每 次更新参数时都使用所有的样本来进行更新 随机梯度下降:由于批量梯度下降法在更新每一个参数时,需要所有的训练样本,所以训练过 程会随着样本数量的加大而变得缓慢,因此出现了随机梯度下降法来解决这一弊端。随机梯度 下降法利用每个样本的损失函数对8求偏导,得到对应的梯度来更新8,训练速度较快
王宇睿 2015201906 p参数⽤于衡量两个实例点相似程度的反映,距离公式可表示为: 当p=2时,表示欧⽒距离;当p=1时,表示曼哈顿距离;当p很⼤时,距离取各维度距离中的 最⼤值。 可以看到在进⾏分类时,KNN分类器的参数选择对accuracy的影响很⼤。在进⾏参数选择 时,可以使⽤GridSearch⽹格搜索。 第七周 Training Models - 课堂笔记 使⽤数据对模型进⾏训练,寻找模型的最优参数。 线性模型:线性模型最简单,有直接的数学计算公式计算使得cost function最⼩的参数: 。使⽤numpy库中提供的rand函数⽣成在线性模型 周围的随 机数(Gaussian noise),并⽤numpy提供的Linear Algebra module计算矩阵转置和矩阵乘 法,得到公式法计算出的theta_best,可以⽤这个 来进⾏函数值预测。⽽sklearn库中提供了 现成的⽅法进⾏线性回归,得到的结果与公式法得到的⼀致。线性模型⼀旦训练好,进⾏预测 时⾮常快。 可以⽤来训练线性模型的⽅法有: 梯度下降:⼀开始进⾏随机初始化,逐步优化,⽬标是减⼩cost function,直到收敛。对于梯 度下降算法,⼀个᯿要的参数就是下降的步⻓,对应的超参数是学习率。学习率如果设置的太 ⼩,可能会迭代太多次都得不到收敛的结果,花费太⻓时间;如果设置的太⼤,可能会越过最 佳点,得不到最优解。同时,梯度下降法可能发现的是局部最优,⽽不是全局最优。不过 MSE cost function是凸函数,这使得梯度下降法发现的⼀定是全局最优。 批量梯度下降:对cost function求偏导,按照梯度的负⽅向下降,下降的步⻓为学习率,在每 次更新参数时都使⽤所有的样本来进⾏更新。 随机梯度下降:由于批量梯度下降法在更新每⼀个参数时,需要所有的训练样本,所以训练过 程会随着样本数量的加⼤⽽变得缓慢,因此出现了随机梯度下降法来解决这⼀弊端。随机梯度 下降法利⽤每个样本的损失函数对 求偏导,得到对应的梯度来更新 ,训练速度较快。 θ ∧ = (XT ⋅ X) −1 ⋅ XT ⋅ y y = 4 + 3X ϑ ϑ ϑ 6

王宇睿2015201906 学习曲线:如果训练好的模型在训练集上表现很好,但使用交叉验证的测试集上表现很差,那 么说明数据出现了过拟合的情况;如果模型在训练集和测试集上变现都很差,则说明数据出现 了欠拟合的情况。 偏差/方差:高偏差意味着模型在训练集上欠拟合,高方差意味着模型在训练集上过拟合。 岭回归:是一种正则化版本的线性回归,为损失函数加上一个正则化项,避免矩阵中某个元素 的一个很小的变动引起最后计算结果误差很大。岭回归有超参数α,如果α为0时,就化简为 线性模型,岭回归牺牲了一部分无偏差性,使得方差变小。 逻辑回归:将数据拟合到一个logistic函数。为估计概率,使用sigmoid函数,它是一个s形的 曲线,取值在0,1]之间。使用逻辑回归可以更好的对事件发生的概率进行预测,以鸢尾花数 据集为例说明逻辑回归。只基于花瓣宽度这一特征构造逻辑回归模型,用于检测Iris-Virginic 种类。 Softmax[回归:Softmaxl回归是逻辑回归的推广,逻辑回归处理二分类问题,而Softmax[回归 处理多分类问题,类标签y的取值大于等于2。对于给定的测试输入×,利用模型针对每一个类 别估算概率值p=j,Softmax函数将k个可能的类别进行了累加,对于Softmax的代价函 数,利用梯度下降法使的J)最小。 课后工作 小组进行课程大作业AiC功能完善,尝试自己构建简单的语音识别系统,识别包括左” “右,前 “后 “停”等控制小车前进方向的关键字,构建和识别的主要过程为 ,数据采集及特征提取 通过录制音频和开源数据中采集两种方式获得了用于输入大量的语音数据和其对应的 文字标签。对获得的原始语音信号讲行外理(由干录制时在较为安静的环境中。因出 不需进行降噪处理) 对语音信号进行分帧(近似认为在10-30ms内是语音信号是短时 平稳的,将语音信号分割为一段一段进行分析)以及预加重(提升高频部分)等处 理。 用kaldit提取出能够反映语音信号特征的关键参数MFCC特征】 翠陈好的MCC特征和时应的类标签验入到狗建的分类器中法行练,利用交 证和网格授索调整分类器的超参数,获得构建好的语音识别模型。 ,识别命令 利用pyth n中的pyaudio包调用电脑的麦克风,从麦克风中获取声音。每隔一定的秒数 将获取到的声音文件实时保存到本地。在iux环境中调用shel脚本利用现有的工具对 音频文件进行MFCC特征提取,将得到的特征结果结果以文件形式保存,然后程序从 文件中读取数据.输入到语音识别樽型中讲行分类,得到对应的标签(左、右.前 后、停) 然而,由于从麦克风中获得声音后进行的操作较多,速度慢,同时,自己构建的语音识别系纺 正确率欠佳,无法满足控制小车的实时性要求,因此目前为止,我们小组决定采用现有的模 对小车进行语音控制。 首先在电脑端利用瑞对端的语音识别系统(IBM Speech to Text)进行语音识别识别出所说 的内容,然后程序读取语音的内容,并根据语言的内容给小车发送相应的指令 小车接到指令 后作出相应的反应,如果没有接到命令则保持现有的运行状态不变。整个语音识别过程见下图: 入√〈〉① 牙发指
王宇睿 2015201906 学习曲线:如果训练好的模型在训练集上表现很好,但使⽤交叉验证的测试集上表现很差,那 么说明数据出现了过拟合的情况;如果模型在训练集和测试集上变现都很差,则说明数据出现 了⽋拟合的情况。 偏差/⽅差:⾼偏差意味着模型在训练集上⽋拟合,⾼⽅差意味着模型在训练集上过拟合。 岭回归:是⼀种正则化版本的线性回归,为损失函数加上⼀个正则化项,避免矩阵中某个元素 的⼀个很⼩的变动引起最后计算结果误差很⼤。岭回归有超参数 ,如果 为0时,就化简为 线性模型,岭回归牺牲了⼀部分⽆偏差性,使得⽅差变⼩。 逻辑回归:将数据拟合到⼀个logistic函数。为估计概率,使⽤sigmoid函数,它是⼀个s形的 曲线,取值在[0, 1]之间。使⽤逻辑回归可以更好的对事件发⽣的概率进⾏预测,以鸢尾花数 据集为例说明逻辑回归。只基于花瓣宽度这⼀特征构造逻辑回归模型,⽤于检测Iris-Virginica 种类。 Softmax回归:Softmax回归是逻辑回归的推⼴,逻辑回归处理⼆分类问题,⽽Softmax回归 处理多分类问题,类标签y的取值⼤于等于2。对于给定的测试输⼊x,利⽤模型针对每⼀个类 别j估算概率值p(y = j|x),Softmax函数将k个可能的类别进⾏了累加,对于Softmax的代价函 数,利⽤梯度下降法使的J(θ)最⼩。 - 课后⼯作 ⼩组进⾏课程⼤作业AiCar功能完善,尝试⾃⼰构建简单的语⾳识别系统,识别包括“左”, “右”,“前”,“后”,“停”等控制⼩⻋前进⽅向的关键字,构建和识别的主要过程为: • 数据采集及特征提取 通过录制⾳频和开源数据中采集两种⽅式获得了⽤于输⼊⼤量的语⾳数据和其对应的 ⽂字标签。对获得的原始语⾳信号进⾏处理(由于录制时在较为安静的环境中,因此 不需进⾏降噪处理),对语⾳信号进⾏分帧(近似认为在10-30ms内是语⾳信号是短时 平稳的,将语⾳信号分割为⼀段⼀段进⾏分析)以及预加᯿(提升⾼频部分)等处 理。 ⽤kaldi提取出能够反映语⾳信号特征的关键参数MFCC特征。 • 模型训练 将整理好的MFCC特征和对应的类标签输⼊到构建的分类器中进⾏训练,利⽤交叉验 证和⽹格搜索调整分类器的超参数,获得构建好的语⾳识别模型。 • 识别命令 利⽤python中的pyaudio包调⽤电脑的⻨克⻛,从⻨克⻛中获取声⾳。每隔⼀定的秒数 将获取到的声⾳⽂件实时保存到本地。在linux环境中调⽤shell脚本利⽤现有的⼯具对 ⾳频⽂件进⾏MFCC特征提取,将得到的特征结果结果以⽂件形式保存,然后程序从 ⽂件中读取数据,输⼊到语⾳识别模型中进⾏分类,得到对应的标签(左、右、前、 后、停)。 然⽽,由于从⻨克⻛中获得声⾳后进⾏的操作较多,速度慢,同时,⾃⼰构建的语⾳识别系统 正确率⽋佳,⽆法满⾜控制⼩⻋的实时性要求,因此⽬前为⽌,我们⼩组决定采⽤现有的模型 对⼩⻋进⾏语⾳控制。 ⾸先在电脑端利⽤端对端的语⾳识别系统(IBM Speech to Text)进⾏语⾳识别,识别出所说 的内容,然后程序读取语⾳的内容,并根据语⾔的内容给⼩⻋发送相应的指令,⼩⻋接到指令 后作出相应的反应,如果没有接到命令则保持现有的运⾏状态不变。整个语⾳识别过程⻅下图: α α 7