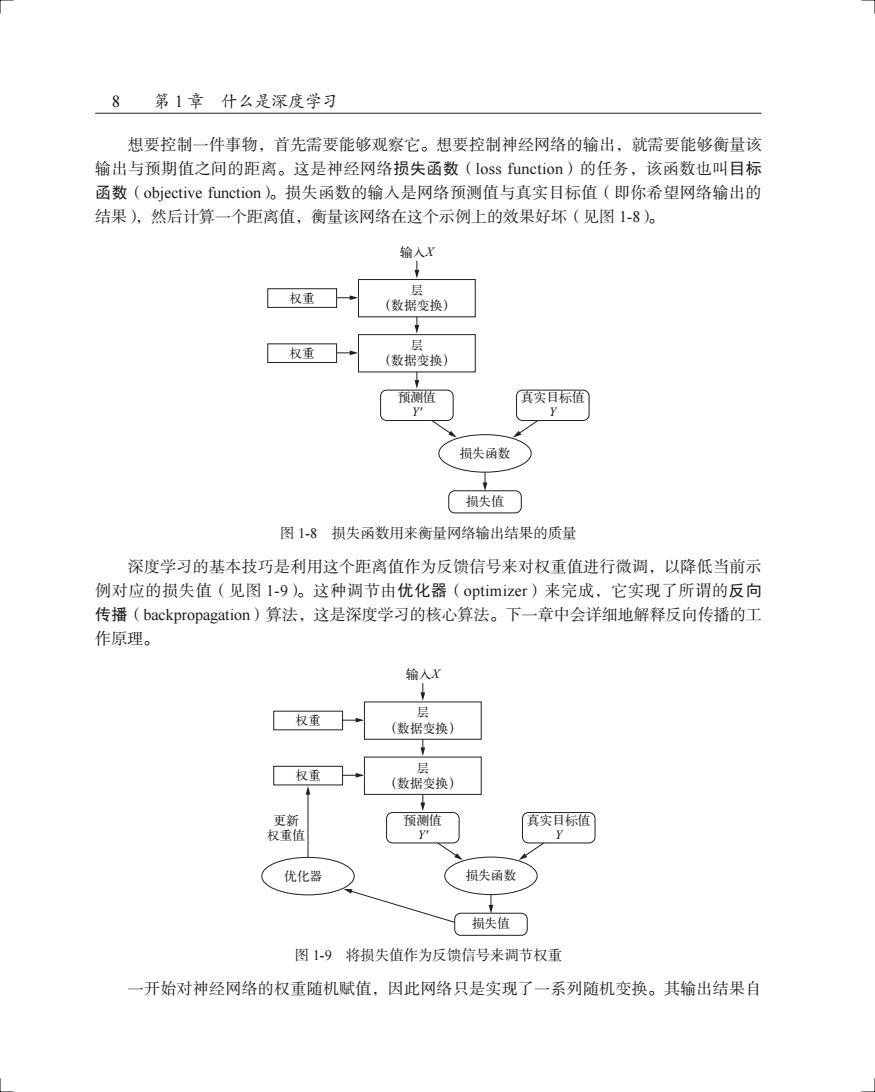
8第1章什么是深度学习 想要控制一件事物,首先需要能够观察它。想要控制神经网络的输出,就需要能够衡量该 输出与预期值之间的距离。这是神经网络损失函数(loss function)的任务,该函数也叫目标 函数(objective function)。损失函数的输入是网络预测值与真实目标值(即你希望网络输出的 结果),然后计算一个距离值,衡量该网络在这个示例上的效果好坏(见图1-8)。 输入X 层 权重 (数据变换) 权重 层 (数据变换) 预测值 真实目标值 Y 损失函数 损失值 图1-8损失函数用来衡量网络输出结果的质量 深度学习的基本技巧是利用这个距离值作为反馈信号来对权重值进行微调,以降低当前示 例对应的损失值(见图1-9)。这种调节由优化器(optimizer)来完成,它实现了所谓的反向 传播(backpropagation)算法,这是深度学习的核心算法。下一章中会详细地解释反向传播的工 作原理。 输人X 层 权重 (数据变换) 层 权重 4 (数据变换) 更新 预测值 真实目标值 权重值 P 优化器 损失函数 损失值 图1-9将损失值作为反馈信号来调节权重 一开始对神经网络的权重随机赋值,因此网络只是实现了一系列随机变换。其输出结果自
8 第 1 章 什么是深度学习 想要控制一件事物,首先需要能够观察它。想要控制神经网络的输出,就需要能够衡量该 输出与预期值之间的距离。这是神经网络损失函数(loss function)的任务,该函数也叫目标 函数(objective function)。损失函数的输入是网络预测值与真实目标值(即你希望网络输出的 结果),然后计算一个距离值,衡量该网络在这个示例上的效果好坏(见图 1-8)。 ֫ DŽຕՎ࣑Dž X ዘ ֫ DŽຕՎ࣑Dž ᇨ֪ኵ Y' ኈํణՔኵ Y ዘ ຕࡧ฿ ฿ኵ 图 1-8 损失函数用来衡量网络输出结果的质量 深度学习的基本技巧是利用这个距离值作为反馈信号来对权重值进行微调,以降低当前示 例对应的损失值(见图 1-9)。这种调节由优化器(optimizer)来完成,它实现了所谓的反向 传播(backpropagation)算法,这是深度学习的核心算法。下一章中会详细地解释反向传播的工 作原理。 ᆫࣅഗ ֫ DŽຕՎ࣑Dž X ዘ ֫ DŽຕՎ࣑Dž ᇨ֪ኵ Y' ኈํణՔኵ Y ዘ ຕࡧ฿ ฿ኵ ߸ႎ ዘኵ 图 1-9 将损失值作为反馈信号来调节权重 一开始对神经网络的权重随机赋值,因此网络只是实现了一系列随机变换。其输出结果自

书籍下载qq群6089740钉钉群21734177 IT书籍http:/t.cn/RDIAj5D 1.1人工智能、机器学习与深度学习 然也和理想值相去甚远,相应地,损失值也很高。但随着网络处理的示例越来越多,权重值也 在向正确的方向逐步微调,损失值也逐渐降低。这就是训练循环(training loop),将这种循环重 复足够多的次数(通常对数千个示例进行数十次迭代),得到的权重值可以使损失函数最小。具 有最小损失的网络,其输出值与目标值尽可能地接近,这就是训练好的网络。再次强调,这是 一个简单的机制,一旦具有足够大的规模,将会产生魔法般的效果。 1.1.6深度学习已经取得的进展 虽然深度学习是机器学习一个相当有年头的分支领域,但在21世纪前十年才崛起。在随后 的几年里,它在实践中取得了革命性进展,在视觉和听觉等感知问题上取得了令人瞩目的成果, 而这些问题所涉及的技术,在人类看来是非常自然、非常直观的,但长期以来却一直是机器难 以解决的。 特别要强调的是,深度学习已经取得了以下突破,它们都是机器学习历史上非常困难的领域: 口接近人类水平的图像分类 口接近人类水平的语音识别 口接近人类水平的手写文字转录 口更好的机器翻译 口更好的文本到语音转换 口数字助理,比如谷歌即时(Google Now)和亚马逊Alexa 口接近人类水平的自动驾驶 口更好的广告定向投放,Google、百度、必应都在使用 口更好的网络搜索结果 口能够回答用自然语言提出的问题 口在围棋上战胜人类 我们仍然在探索深度学习能力的边界。我们已经开始将其应用于机器感知和自然语言理解 之外的各种问题,比如形式推理。如果能够成功的话,这可能预示着深度学习将能够协助人类 进行科学研究、软件开发等活动。 1.1.7不要相信短期炒作 虽然深度学习近年来取得了令人瞩目的成就,但人们对这一领域在未来十年间能够取得的 成就似乎期望过高。虽然一些改变世界的应用(比如自动驾驶汽车)已经触手可及,但更多的 应用可能在长时间内仍然难以实现,比如可信的对话系统、达到人类水平的跨任意语言的机器 翻译、达到人类水平的自然语言理解。我们尤其不应该把达到人类水平的通用智能(human-level general intelligence)的讨论太当回事。在短期内期望过高的风险是,一旦技术上没有实现,那 么研究投资将会停止,而这会导致在很长一段时间内进展缓慢。 这种事曾经发生过。人们曾对人工智能极度乐观,随后是失望与怀疑,进而导致资金匮乏。 这种循环发生过两次,最早始于20世纪60年代的符号主义人工智能。在早期的那些年里,人 电子书寻找看手相钉钉或微信pythontesting
1.1 人工智能、机器学习与深度学习 9 1 5 3 7 2 6 4 8 9 然也和理想值相去甚远,相应地,损失值也很高。但随着网络处理的示例越来越多,权重值也 在向正确的方向逐步微调,损失值也逐渐降低。这就是训练循环(training loop),将这种循环重 复足够多的次数(通常对数千个示例进行数十次迭代),得到的权重值可以使损失函数最小。具 有最小损失的网络,其输出值与目标值尽可能地接近,这就是训练好的网络。再次强调,这是 一个简单的机制,一旦具有足够大的规模,将会产生魔法般的效果。 1.1.6 深度学习已经取得的进展 虽然深度学习是机器学习一个相当有年头的分支领域,但在 21 世纪前十年才崛起。在随后 的几年里,它在实践中取得了革命性进展,在视觉和听觉等感知问题上取得了令人瞩目的成果, 而这些问题所涉及的技术,在人类看来是非常自然、非常直观的,但长期以来却一直是机器难 以解决的。 特别要强调的是,深度学习已经取得了以下突破,它们都是机器学习历史上非常困难的领域: 接近人类水平的图像分类 接近人类水平的语音识别 接近人类水平的手写文字转录 更好的机器翻译 更好的文本到语音转换 数字助理,比如谷歌即时(Google Now)和亚马逊 Alexa 接近人类水平的自动驾驶 更好的广告定向投放,Google、百度、必应都在使用 更好的网络搜索结果 能够回答用自然语言提出的问题 在围棋上战胜人类 我们仍然在探索深度学习能力的边界。我们已经开始将其应用于机器感知和自然语言理解 之外的各种问题,比如形式推理。如果能够成功的话,这可能预示着深度学习将能够协助人类 进行科学研究、软件开发等活动。 1.1.7 不要相信短期炒作 虽然深度学习近年来取得了令人瞩目的成就,但人们对这一领域在未来十年间能够取得的 成就似乎期望过高。虽然一些改变世界的应用(比如自动驾驶汽车)已经触手可及,但更多的 应用可能在长时间内仍然难以实现,比如可信的对话系统、达到人类水平的跨任意语言的机器 翻译、达到人类水平的自然语言理解。我们尤其不应该把达到人类水平的通用智能(human-level general intelligence)的讨论太当回事。在短期内期望过高的风险是,一旦技术上没有实现,那 么研究投资将会停止,而这会导致在很长一段时间内进展缓慢。 这种事曾经发生过。人们曾对人工智能极度乐观,随后是失望与怀疑,进而导致资金匮乏。 这种循环发生过两次,最早始于 20 世纪 60 年代的符号主义人工智能。在早期的那些年里,人 书籍下载qq群6089740 钉钉群21734177 IT书籍 http://t.cn/RDIAj5D 电子书寻找看手相 钉钉或微信pythontesting

10 第1章什么是深度学习 们激动地预测着人工智能的未来。马文·闵斯基是符号主义人工智能方法最有名的先驱和支持 者之一,他在1967年宣称:“在一代人的时间内…将基本解决创造‘人工智能’的问题。”三 年后的1970年,他做出了更为精确的定量预测:“在三到八年的时间里,我们将拥有一台具有 人类平均智能的机器。”在2016年,这一目标看起来仍然十分遥远,遥远到我们无法预测需要 多长时间才能实现。但在20世纪60年代和70年代初,一些专家却相信这一目标近在咫尺(正 如今天许多人所认为的那样)。几年之后,由于这些过高的期望未能实现,研究人员和政府资金 均转向其他领域,这标志着第一次人工智能冬天(AI winter)的开始(这一说法来自“核冬天”, 因为当时是冷战高峰之后不久)。 这并不是人工智能的最后一个冬天。20世纪80年代,一种新的符号主义人工智能一专 家系统(expert system)一开始在大公司中受到追捧。最初的几个成功案例引发了一轮投资热 潮,进而全球企业都开始设立人工智能部门来开发专家系统。1985年前后,各家公司每年在这 项技术上的花费超过10亿美元。但到了20世纪90年代初,这些系统的维护费用变得很高,难 以扩展,并且应用范围有限,人们逐渐对其失去兴趣。于是开始了第二次人工智能冬天。 我们可能正在见证人工智能炒作与让人失望的第三次循环,而且我们仍处于极度乐观的阶 段。最好的做法是降低我们的短期期望,确保对这一技术领域不太了解的人能够清楚地知道深 度学习能做什么、不能做什么。 1.1.8人工智能的未来 虽然我们对人工智能的短期期望可能不切实际,但长远来看前景是光明的。我们才刚刚开 始将深度学习应用于许多重要的问题,从医疗诊断到数字助手,在这些问题上深度学习都发挥 了变革性作用。过去五年里,人工智能研究一直在以惊人的速度发展,这在很大程度上是由于 人工智能短短的历史中前所未见的资金投入,但到目前为止,这些进展却很少能够转化为改变 世界的产品和流程。深度学习的大多数研究成果尚未得到应用,至少尚未应用到它在各行各业 中能够解决的所有问题上。你的医生和会计师都还没有使用人工智能。你在日常生活中可能也 不会用到人工智能。当然,你可以向智能手机提出简单的问题并得到合理的回答,也可以在亚 马逊网站上得到相当有用的产品推荐,还可以在谷歌相册(Google Photos)网站搜索“生日” 并立刻找到上个月你女儿生日聚会的照片。与过去相比,这些技术已大不相同,但这些工具仍 然只是日常生活的陪衬。人工智能仍需进一步转变为我们工作、思考和生活的核心。 眼下,我们似乎很难相信人工智能会对世界产生巨大影响,因为它还没有被广泛地部署应 用一正如1995年,我们也难以相信互联网在未来会产生的影响。当时,大多数人都没有认识 到互联网与他们的关系,以及互联网将如何改变他们的生活。今天的深度学习和人工智能也是 如此。但不要怀疑:人工智能即将到来。在不远的未来,人工智能将会成为你的助手,甚至成 为你的朋友。它会回答你的问题,帮助你教育孩子,并关注你的健康。它还会将生活用品送到 你家门口,并开车将你从A地送到B地。它还会是你与日益复杂的、信息密集的世界之间的接口。 更为重要的是,人工智能将会帮助科学家在所有科学领域(从基因学到数学)取得突破性进展, 从而帮助人类整体向前发展
10 第 1 章 什么是深度学习 们激动地预测着人工智能的未来。马文 • 闵斯基是符号主义人工智能方法最有名的先驱和支持 者之一,他在 1967 年宣称:“在一代人的时间内……将基本解决创造‘人工智能’的问题。”三 年后的 1970 年,他做出了更为精确的定量预测:“在三到八年的时间里,我们将拥有一台具有 人类平均智能的机器。”在 2016 年,这一目标看起来仍然十分遥远,遥远到我们无法预测需要 多长时间才能实现。但在 20 世纪 60 年代和 70 年代初,一些专家却相信这一目标近在咫尺(正 如今天许多人所认为的那样)。几年之后,由于这些过高的期望未能实现,研究人员和政府资金 均转向其他领域,这标志着第一次人工智能冬天(AI winter)的开始(这一说法来自“核冬天”, 因为当时是冷战高峰之后不久)。 这并不是人工智能的最后一个冬天。20 世纪 80 年代,一种新的符号主义人工智能——专 家系统(expert system)——开始在大公司中受到追捧。最初的几个成功案例引发了一轮投资热 潮,进而全球企业都开始设立人工智能部门来开发专家系统。1985 年前后,各家公司每年在这 项技术上的花费超过 10 亿美元。但到了 20 世纪 90 年代初,这些系统的维护费用变得很高,难 以扩展,并且应用范围有限,人们逐渐对其失去兴趣。于是开始了第二次人工智能冬天。 我们可能正在见证人工智能炒作与让人失望的第三次循环,而且我们仍处于极度乐观的阶 段。最好的做法是降低我们的短期期望,确保对这一技术领域不太了解的人能够清楚地知道深 度学习能做什么、不能做什么。 1.1.8 人工智能的未来 虽然我们对人工智能的短期期望可能不切实际,但长远来看前景是光明的。我们才刚刚开 始将深度学习应用于许多重要的问题,从医疗诊断到数字助手,在这些问题上深度学习都发挥 了变革性作用。过去五年里,人工智能研究一直在以惊人的速度发展,这在很大程度上是由于 人工智能短短的历史中前所未见的资金投入,但到目前为止,这些进展却很少能够转化为改变 世界的产品和流程。深度学习的大多数研究成果尚未得到应用,至少尚未应用到它在各行各业 中能够解决的所有问题上。你的医生和会计师都还没有使用人工智能。你在日常生活中可能也 不会用到人工智能。当然,你可以向智能手机提出简单的问题并得到合理的回答,也可以在亚 马逊网站上得到相当有用的产品推荐,还可以在谷歌相册(Google Photos)网站搜索“生日” 并立刻找到上个月你女儿生日聚会的照片。与过去相比,这些技术已大不相同,但这些工具仍 然只是日常生活的陪衬。人工智能仍需进一步转变为我们工作、思考和生活的核心。 眼下,我们似乎很难相信人工智能会对世界产生巨大影响,因为它还没有被广泛地部署应 用——正如 1995 年,我们也难以相信互联网在未来会产生的影响。当时,大多数人都没有认识 到互联网与他们的关系,以及互联网将如何改变他们的生活。今天的深度学习和人工智能也是 如此。但不要怀疑:人工智能即将到来。在不远的未来,人工智能将会成为你的助手,甚至成 为你的朋友。它会回答你的问题,帮助你教育孩子,并关注你的健康。它还会将生活用品送到 你家门口,并开车将你从 A 地送到 B 地。它还会是你与日益复杂的、信息密集的世界之间的接口。 更为重要的是,人工智能将会帮助科学家在所有科学领域(从基因学到数学)取得突破性进展, 从而帮助人类整体向前发展

书籍下载qg群6089740钉钉群21734177 IT书籍http:/t.cn/RDIAj5D 1.2深度学习之前:机器学习简史 11 在这个过程中,我们可能会经历一些挫折,也可能会遇到新的人工智能冬天,正如互联网 行业那样,在1998一1999年被过度炒作,进而在21世纪初遭遇破产,并导致投资停止。但我 们最终会实现上述目标。人工智能最终将应用到我们社会和日常生活的几乎所有方面,正如今 天的互联网一样。 不要相信短期的炒作,但一定要相信长期的愿景。人工智能可能需要一段时间才能充分发 挥其潜力。这一潜力的范围大到难以想象,但人工智能终将到来,它将以一种奇妙的方式改变 我们的世界。 1.2深度学习之前:机器学习简史 深度学习已经得到了人工智能历史上前所未有的公众关注度和产业投资,但这并不是机器 学习的第一次成功。可以这样说,当前工业界所使用的绝大部分机器学习算法都不是深度学习 算法。深度学习不一定总是解决问题的正确工具:有时没有足够的数据,深度学习不适用;有 时用其他算法可以更好地解决问题。如果你第一次接触的机器学习就是深度学习,那你可能会 发现手中握着一把深度学习“锤子”,而所有机器学习问题看起来都像是“钉子”。为了避免陷 入这个误区,唯一的方法就是熟悉其他机器学习方法并在适当的时候进行实践。 关于经典机器学习方法的详细讨论已经超出了本书范围,但我们将简要回顾这些方法,并 介绍这些方法的历史背景。这样我们可以将深度学习放入机器学习的大背景中,并更好地理解 深度学习的起源以及它为什么如此重要。 1.2.1概率建模 概率建模(probabilistic modeling)是统计学原理在数据分析中的应用。它是最早的机器学 习形式之一,至今仍在广泛使用。其中最有名的算法之一就是朴素贝叶斯算法。 朴素贝叶斯是一类基于应用贝叶斯定理的机器学习分类器,它假设输入数据的特征都是独 立的。这是一个很强的假设,或者说“朴素的”假设,其名称正来源于此。这种数据分析方法 比计算机出现得还要早,在其第一次被计算机实现(很可能追溯到20世纪50年代)的几十年 前就已经靠人工计算来应用了。贝叶斯定理和统计学基础可以追溯到18世纪,你学会了这两点 就可以开始使用朴素贝叶斯分类器了。 另一个密切相关的模型是logistic回归(logistic regression,简称logreg),它有时被认为是 现代机器学习的“hello world”。不要被它的名称所误导一Hlogreg是一种分类算法,而不是回 归算法。与朴素贝叶斯类似,logreg的出现也比计算机早很长时间,但由于它既简单又通用, 至今仍然很有用。面对一个数据集,数据科学家通常会首先尝试使用这个算法,以便初步熟悉 手头的分类任务。 1.2.2 早期神经网络 神经网络早期的迭代方法已经完全被本章所介绍的现代方法所取代,但仍有助于我们了解 电子书寻找看手相钉钉或微信pythontesting
1.2 深度学习之前:机器学习简史 11 1 5 3 7 2 6 4 8 9 在这个过程中,我们可能会经历一些挫折,也可能会遇到新的人工智能冬天,正如互联网 行业那样,在 1998—1999 年被过度炒作,进而在 21 世纪初遭遇破产,并导致投资停止。但我 们最终会实现上述目标。人工智能最终将应用到我们社会和日常生活的几乎所有方面,正如今 天的互联网一样。 不要相信短期的炒作,但一定要相信长期的愿景。人工智能可能需要一段时间才能充分发 挥其潜力。这一潜力的范围大到难以想象,但人工智能终将到来,它将以一种奇妙的方式改变 我们的世界。 1.2 深度学习之前:机器学习简史 深度学习已经得到了人工智能历史上前所未有的公众关注度和产业投资,但这并不是机器 学习的第一次成功。可以这样说,当前工业界所使用的绝大部分机器学习算法都不是深度学习 算法。深度学习不一定总是解决问题的正确工具:有时没有足够的数据,深度学习不适用;有 时用其他算法可以更好地解决问题。如果你第一次接触的机器学习就是深度学习,那你可能会 发现手中握着一把深度学习“锤子”,而所有机器学习问题看起来都像是“钉子”。为了避免陷 入这个误区,唯一的方法就是熟悉其他机器学习方法并在适当的时候进行实践。 关于经典机器学习方法的详细讨论已经超出了本书范围,但我们将简要回顾这些方法,并 介绍这些方法的历史背景。这样我们可以将深度学习放入机器学习的大背景中,并更好地理解 深度学习的起源以及它为什么如此重要。 1.2.1 概率建模 概率建模(probabilistic modeling)是统计学原理在数据分析中的应用。它是最早的机器学 习形式之一,至今仍在广泛使用。其中最有名的算法之一就是朴素贝叶斯算法。 朴素贝叶斯是一类基于应用贝叶斯定理的机器学习分类器,它假设输入数据的特征都是独 立的。这是一个很强的假设,或者说“朴素的”假设,其名称正来源于此。这种数据分析方法 比计算机出现得还要早,在其第一次被计算机实现(很可能追溯到 20 世纪 50 年代)的几十年 前就已经靠人工计算来应用了。贝叶斯定理和统计学基础可以追溯到 18 世纪,你学会了这两点 就可以开始使用朴素贝叶斯分类器了。 另一个密切相关的模型是 logistic 回归(logistic regression,简称 logreg),它有时被认为是 现代机器学习的“hello world”。不要被它的名称所误导——logreg 是一种分类算法,而不是回 归算法。与朴素贝叶斯类似,logreg 的出现也比计算机早很长时间,但由于它既简单又通用, 至今仍然很有用。面对一个数据集,数据科学家通常会首先尝试使用这个算法,以便初步熟悉 手头的分类任务。 1.2.2 早期神经网络 神经网络早期的迭代方法已经完全被本章所介绍的现代方法所取代,但仍有助于我们了解 书籍下载qq群6089740 钉钉群21734177 IT书籍 http://t.cn/RDIAj5D 电子书寻找看手相 钉钉或微信pythontesting

12 第1章什么是深度学习 深度学习的起源。虽然人们早在20世纪50年代就将神经网络作为玩具项目,并对其核心思想 进行研究,但这一方法在数十年后才被人们所使用。在很长一段时间内,一直没有训练大型神 经网络的有效方法。这一点在20世纪80年代中期发生了变化,当时很多人都独立地重新发现 了反向传播算法一一种利用梯度下降优化来训练一系列参数化运算链的方法(本书后面将给 出这些概念的具体定义),并开始将其应用于神经网络。 贝尔实验室于1989年第一次成功实现了神经网络的实践应用,当时Yann LeCun将卷积 神经网络的早期思想与反向传播算法相结合,并将其应用于手写数字分类问题,由此得到名为 LeNt的网络,在20世纪90年代被美国邮政署采用,用于自动读取信封上的邮政编码。 1.2.3核方法 上节所述神经网络取得了第一次成功,并在20世纪90年代开始在研究人员中受到一定的 重视,但一种新的机器学习方法在这时声名鹊起,很快就使人们将神经网络抛诸脑后。这种方 法就是核方法(kernel method)。核方法是一组分类算法,其中最有名的就是支持向量机(SVM, support vector machine)o虽然Vladimir Vapnik和Alexey Chervonenkis早在I963年就发表了较 早版本的线性公式①,但SVM的现代公式由Vladimir Vapnik和Corinna Cortes于20世纪90年代 初在贝尔实验室提出,并发表于1995年”。 SVM的目标是通过在属于两个不同类别的两组数据点之间找到良好决策边界(decision boundary,见图1-l0)来解决分类问题。决策边界可以看作一条直线或一个平面,将训练数据 划分为两块空间,分别对应于两个类别。对于新数据点的分类,你只需判断它位于决策边界的 哪一侧。 O 图1-10决策边界 SVM通过两步来寻找决策边界。 ()将数据映射到一个新的高维表示,这时决策边界可以用一个超平面来表示(如果数据像 图1-10那样是二维的,那么超平面就是一条直线)。 1 VAPNIK V,CHERVONENKIS A.A note on one class of perceptrons [J].Automation and Remote Control,1964,25(1). 2 VAPNIK V,CORTES C.Support-vector networks [J].Machine Learning,1995,20(3):273-297
12 第 1 章 什么是深度学习 深度学习的起源。虽然人们早在 20 世纪 50 年代就将神经网络作为玩具项目,并对其核心思想 进行研究,但这一方法在数十年后才被人们所使用。在很长一段时间内,一直没有训练大型神 经网络的有效方法。这一点在 20 世纪 80 年代中期发生了变化,当时很多人都独立地重新发现 了反向传播算法——一种利用梯度下降优化来训练一系列参数化运算链的方法(本书后面将给 出这些概念的具体定义),并开始将其应用于神经网络。 贝尔实验室于 1989 年第一次成功实现了神经网络的实践应用,当时 Yann LeCun 将卷积 神经网络的早期思想与反向传播算法相结合,并将其应用于手写数字分类问题,由此得到名为 LeNet 的网络,在 20 世纪 90 年代被美国邮政署采用,用于自动读取信封上的邮政编码。 1.2.3 核方法 上节所述神经网络取得了第一次成功,并在 20 世纪 90 年代开始在研究人员中受到一定的 重视,但一种新的机器学习方法在这时声名鹊起,很快就使人们将神经网络抛诸脑后。这种方 法就是核方法(kernel method)。核方法是一组分类算法,其中最有名的就是支持向量机(SVM, support vector machine)。虽然 Vladimir Vapnik 和 Alexey Chervonenkis 早在 1963 年就发表了较 早版本的线性公式 a,但 SVM 的现代公式由 Vladimir Vapnik 和 Corinna Cortes 于 20 世纪 90 年代 初在贝尔实验室提出,并发表于 1995 年 b。 SVM 的目标是通过在属于两个不同类别的两组数据点之间找到良好决策边界(decision boundary,见图 1-10)来解决分类问题。决策边界可以看作一条直线或一个平面,将训练数据 划分为两块空间,分别对应于两个类别。对于新数据点的分类,你只需判断它位于决策边界的 哪一侧。 图 1-10 决策边界 SVM 通过两步来寻找决策边界。 (1) 将数据映射到一个新的高维表示,这时决策边界可以用一个超平面来表示(如果数据像 图 1-10 那样是二维的,那么超平面就是一条直线)。 a VAPNIK V, CHERVONENKIS A. A note on one class of perceptrons [J]. Automation and Remote Control, 1964, 25(1). b VAPNIK V, CORTES C. Support-vector networks [J]. Machine Learning, 1995, 20(3): 273-297